哈希函数的工程应用
Hash
散列函数 - 维基百科,自由的百科全书 (wikipedia.org)
Hash 是什么
哈希(Hash)的原理是通过一种特定的函数,将任意长度的输入(也称为键)映射为固定长度的输出(称为哈希值、哈希码或散列值)。这种函数称为哈希函数或散列函数。哈希主要用于快速查找、数据完整性验证等方面,下面具体解释其原理和应用:
哈希函数的原理
哈希函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值(又叫哈希值)(hash values,hash codes,hash sums,或hashes)的指纹。散列值通常用一个短的随机字母和数字组成的字符串来代表。
哈希函数的基本目标是将不同的输入映射为不同的输出。常见哈希函数的特性包括:
- 确定性:相同的输入永远会产生相同的哈希值。
- 效率:计算哈希值的过程非常快,便于快速存取和查找。
- 分布均匀:不同的输入尽可能分布到不同的哈希值上,以减少哈希冲突。
- 不可逆性:通常不能通过哈希值反推出原始输入(主要在密码学中强调)。
- 攻破:能够找出具有相同哈希值的一对报文,但是从一个已知报文篡改成具有相同哈希值的报文仍然没有方法
哈希冲突
哈希函数将无限多的输入映射到有限的输出空间,因此必然会发生不同输入产生相同哈希值的情况,即哈希冲突。常见的处理冲突方法有:
链地址法(链表法):在哈希表中,每个位置存储一个链表,当出现冲突时将数据插入链表。(JDK HashMap)链地址法适用于经常进行插入和删除的情况。
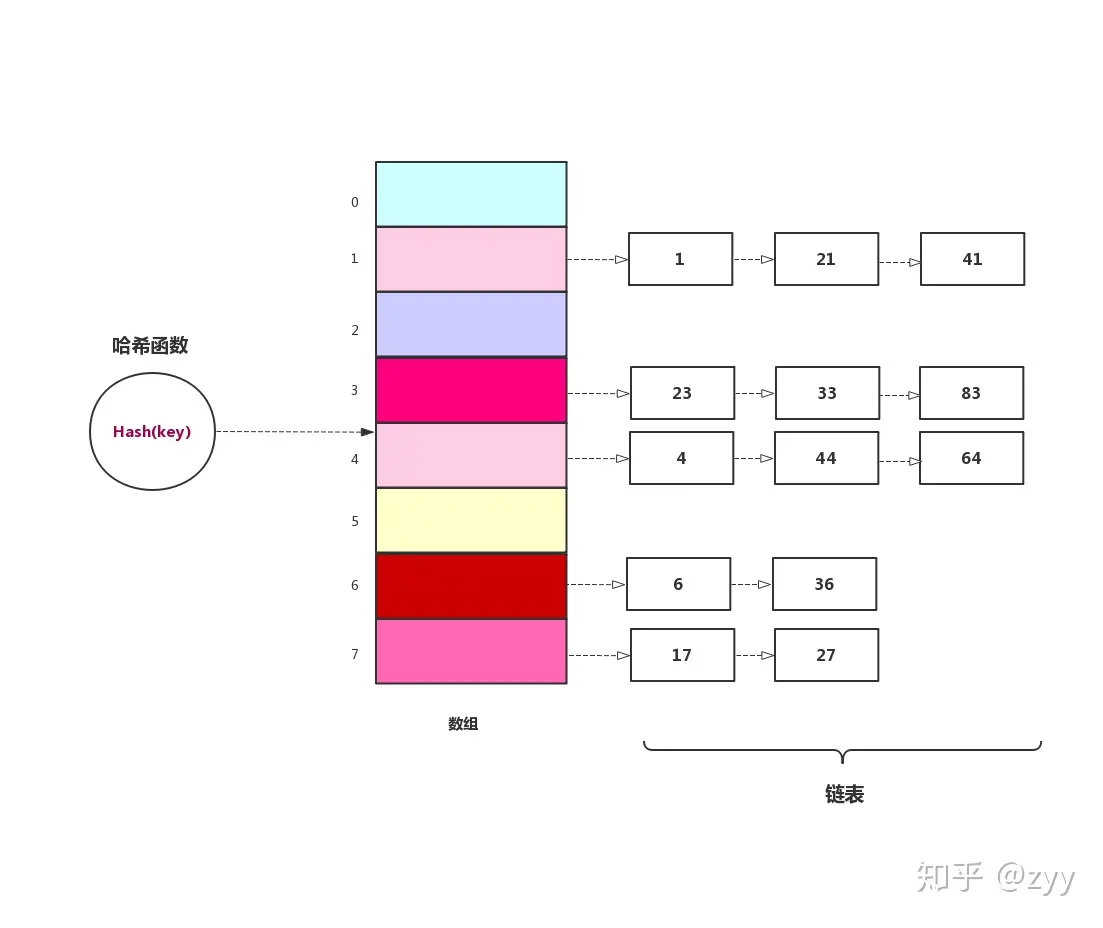
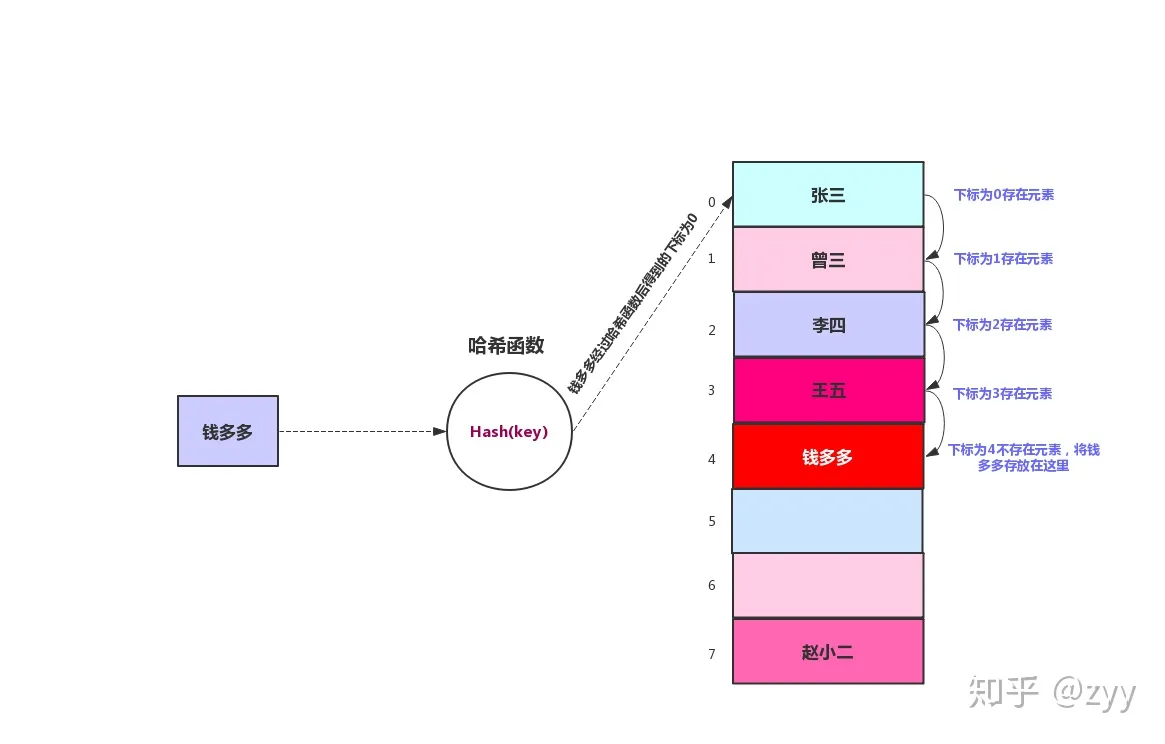
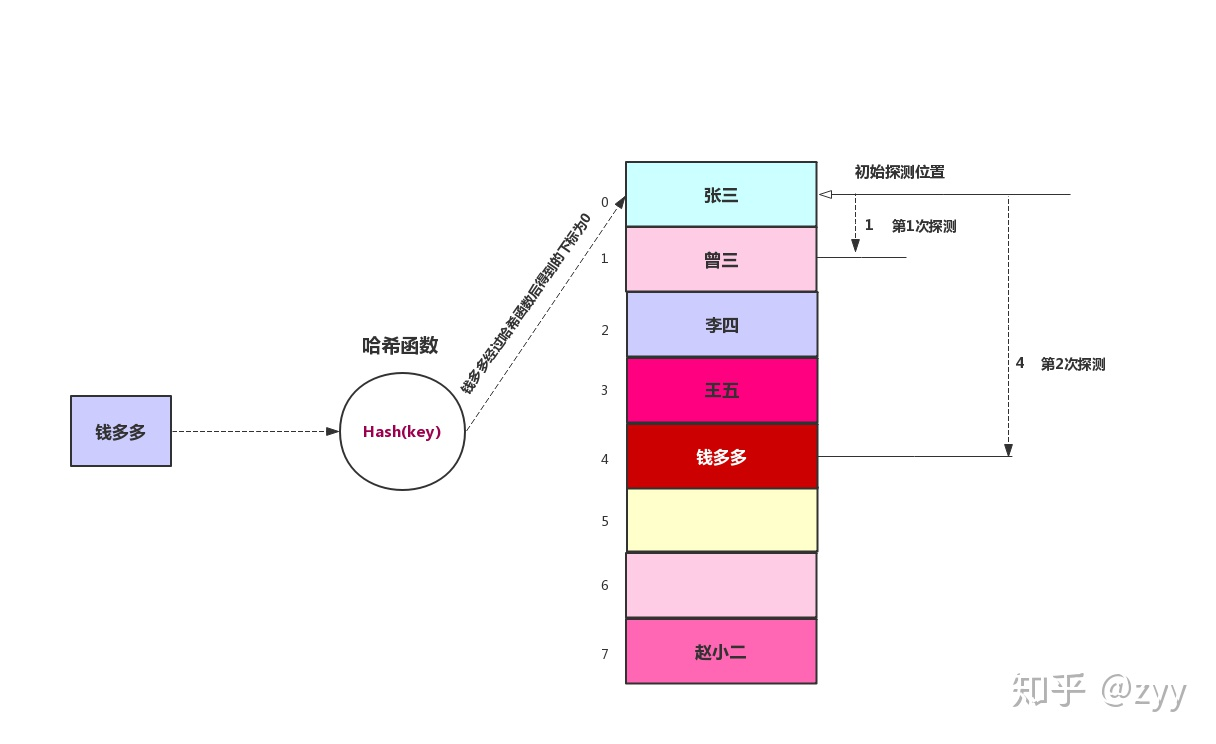
开放地址法:通过探测和寻找空位存储冲突的数据,例如线性探测、二次探测、伪随机探测再散列等。二次探测消除了线性探测的聚集问题,这种聚集问题叫做原始聚集
再哈希法:当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
哈希应用
- 哈希表:用于快速存储和查找数据,常用的数据结构之一。
- 数据完整性:验证数据的完整性,如文件校验和。
- 密码学:生成数据的“指纹”,用于验证用户密码、数字签名等。
哈希函数的常见算法
MD5
MD5消息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16个字节)的散列值(hash value),用于确保信息传输完整一致。曾被用于文件校验、SSL/TLS、IPsec、SSH
深入解析MD5哈希算法:原理、应用与安全性-腾讯云开发者社区-腾讯云 (tencent.com)
- 将报文按模2^64^取余,追加在报文后面
- 在报文和余数之间填充若干位,使得总长度为512的整数倍,第一位是1其他位是0
- 按照512位一块,分成若干块,分割之后再把每块分成4个128位的数据块,送到4个不同的哈希函数进行4轮计算,每一轮按照32位的小块进行运算,一直到最后计算出MD5报文摘要代码。
SHA
安全散列算法(英语:Secure Hash Algorithm,缩写为SHA)是一个密码散列函数家族,是FIPS所认证的安全散列算法。能计算出一个数字消息所对应到的,长度固定的字符串(又称消息摘要)的算法。且若输入的消息不同,它们对应到不同字符串的几率很高。
什么是 SHA 加密? SHA-1 与 SHA-2 - FreeBuf网络安全行业门户
CRC
循环冗余校验(英语:Cyclic redundancy check,通称“CRC”)是一种根据网络数据包或电脑文件等数据产生简短固定位数校验码的一种散列函数,主要用来检测或校验数据传输或者保存后可能出现的错误。生成的数字在传输或者存储之前计算出来并且附加到数据后面,然后接收方进行检验确定数据是否发生变化。
什么是CRC(Cyclic Redundancy Check)?如何解决CRC错误? - 华为 (huawei.com)
校验和 - 维基百科,自由的百科全书 (wikipedia.org)
分布式哈希算法—服务节点集群、DHT
分布式哈希函数:用于负载均衡和分布式存储,如一致性哈希。
一致性哈希
如果简单的用服务器数量取模来进行负载均衡,一旦新增或者故障移除使服务器数变化,就会导致同一个key,一开始存储在A服务器上,数量变化后,去B服务器查询,也就是被分配到了与之前不同的服务器上,导致缓存大量失效,缓存失效的根本原因是:普通哈希算法的映射规则与节点数量高度耦合,导致节点数量变化时,几乎所有数据的映射关系都会变动。因此,之前缓存的绝大部分数据都会失效,无法在原有的缓存节点上找到,导致缓存命中率急剧下降。
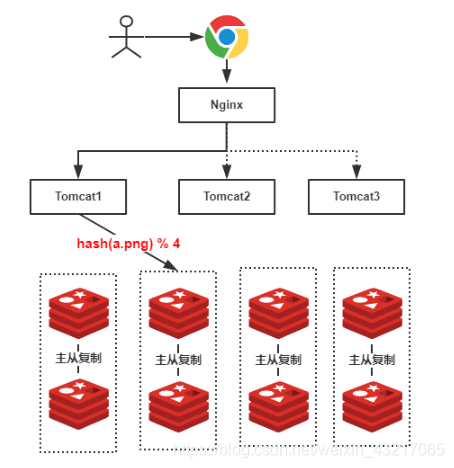
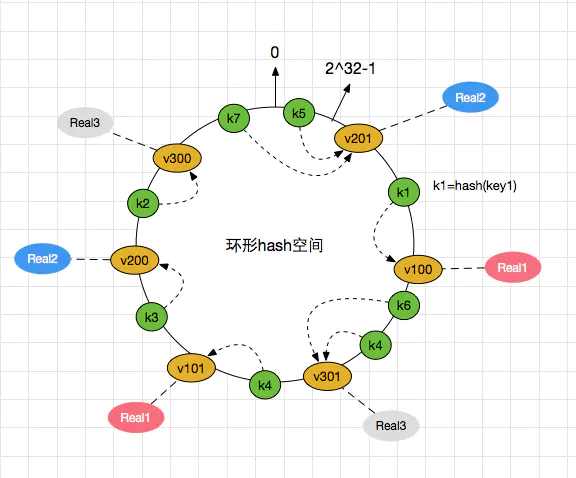
一致性哈希通过对2^32^取模,将各个服务器进行哈希,分配到哈希环上,可以使用IP地址或者主机名哈希
把数据key也分配到哈希环上面,然后顺时针寻找离自己最近的服务器(哈希值)
如下图所示,一台服务器挂了,不会影响到它之后的key,最小化缓存失效的影响
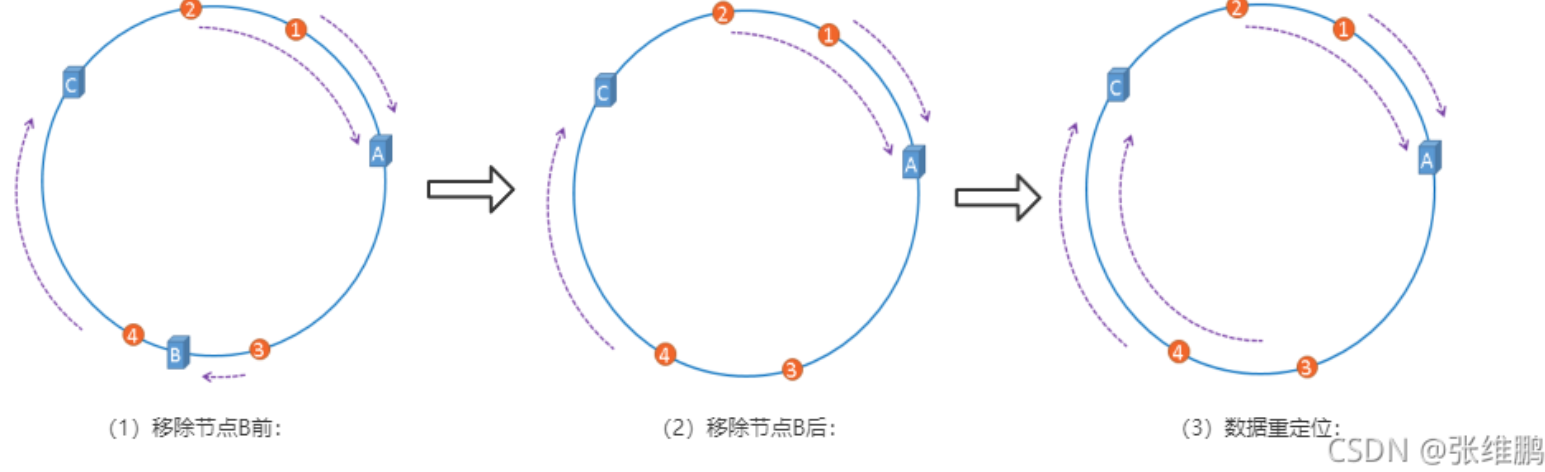
哈希环倾斜—虚拟节点
如下图所示,服务器节点较少,导致大部分key都缓存在A服务器上,数据分布不均匀,削弱了负载均衡的效果
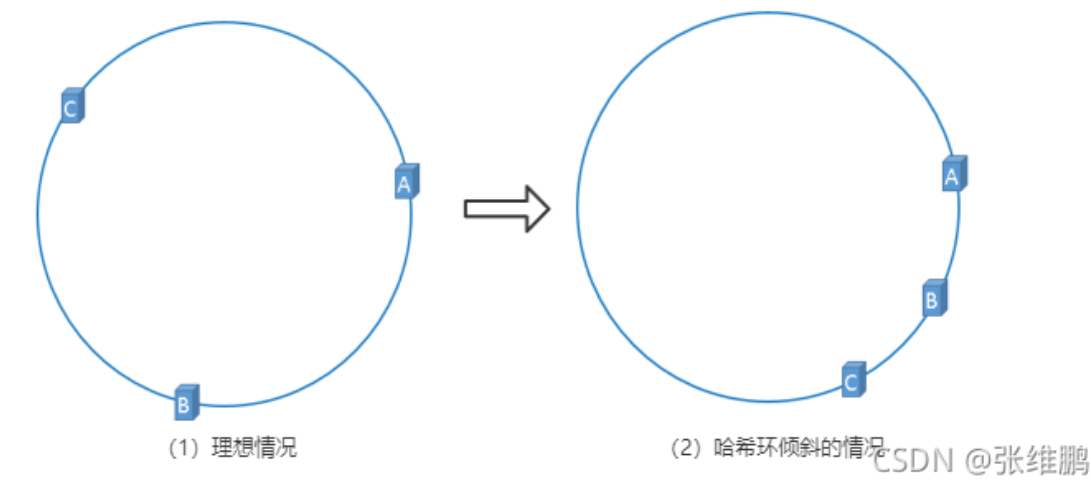
还有一种情况,节点数过少,只有AB
为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点,一个实际物理节点可以对应多个虚拟节点,虚拟节点越多,hash环上的节点就越多,缓存被均匀分布的概率就越大,hash环倾斜所带来的影响就越小,同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射。一个节点挂掉不至于将所有请求打到另一个节点上导致连续崩溃,起到负载均衡的作用。
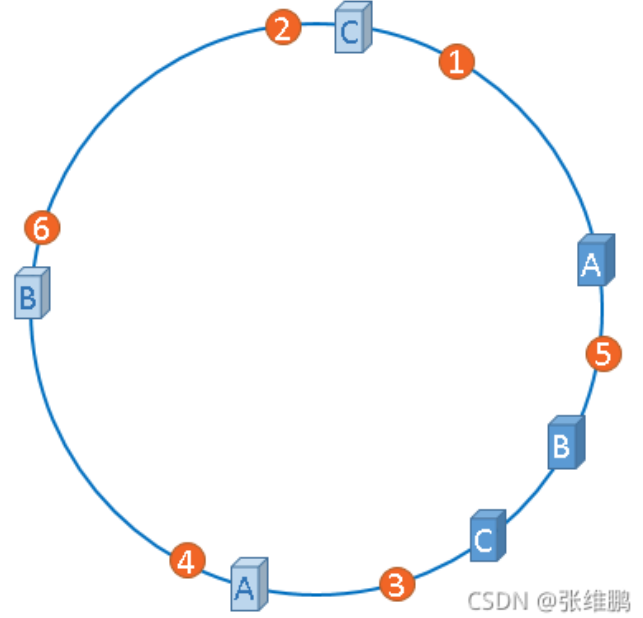
应用:DHT
DHT 将键值对 (key-value) 存储在多个分布式节点中,通过哈希函数映射键值到节点位置,实现快速查找和存储。
- **键 (Key)**:唯一标识数据项的标记。
- **值 (Value)**:存储的实际数据或其引用。
- 哈希函数:将键映射到固定长度的哈希值,用于定位数据。
DHT 使用一致性哈希算法(Consistent Hashing)将节点和数据映射到一个哈希环上,确保节点的加入或退出只影响少量数据的重新分布。
存储数据:
- 数据通过哈希函数生成键,例如
hash(key)。 - 键定位到负责存储的节点。
查找数据:
- 查询方根据相同哈希规则计算键的哈希值,找到对应节点。
- 请求直接或逐步(路由)传递到存储数据的节点。
节点变化处理:
- 新节点加入:重新分配部分数据给新节点。
- 节点退出:其数据重新分配到其他节点上,保证冗余备份和数据一致性。
应用:
P2P 网络:
- BitTorrent 使用 DHT 寻找资源和共享文件。
- Kad 网络(eMule)基于 Kademlia 算法实现。
分布式缓存:
- Cassandra、DynamoDB 等分布式数据库利用 DHT 进行数据分布和一致性维护。
区块链和去中心化存储:
- IPFS(InterPlanetary File System)利用 DHT 定位文件存储位置。
分布式文件系统:
- Chord、Pastry、Tapestry 等协议用于存储和检索分布式文件。
Chord:环形结构,使用一致性哈希算法,支持动态节点增减。
Kademlia:基于二叉树的路由协议,用于 eMule 和 BitTorrent。
Pastry:支持高效查找和动态扩展,适用于大型网络。
Tapestry:与 Pastry 类似,优化了搜索路径和延迟控制。
哈希插槽
详见redis cluster的哈希插槽实现
应用:哈希表
散列表 - 维基百科,自由的百科全书 (wikipedia.org)
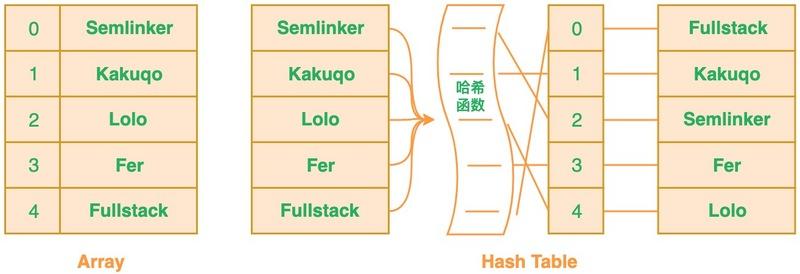
哈希表在大多数实现中,本质上是一个大数组,其中每个元素称为桶(bucket)。在这个大数组的基础上,通过哈希函数将键映射到数组的索引位置来存储和查找数据。
本质还是一个数组,但是数组的角标和键挂钩,在数组角标位置存储值,根据键就能很快找到对应的索引。
哈希表的实现原理
一个大数组:哈希表的核心数据结构是一个数组,用于存储数据的位置。每个数组元素可以直接存储数据(若无冲突)或指向链表、红黑树等其他结构(若发生冲突)。
数组中的每个元素即为一个桶:
- 当多个键的哈希值映射到同一个索引位置(即哈希冲突)时,这个位置的元素会作为桶的“起点”,桶内部可以使用链表或树结构来存储多个值。
- 在 JDK 的
HashMap中,每个桶初始是一个链表,当冲突元素超过一定数量时,该桶会从链表转换为红黑树结构,以提升查找效率。
桶数组的大小:一般是固定大小或者按需扩容。例如,Java 中的
HashMap会在达到一定负载因子后(通常为 0.75)自动扩容,将原数组容量扩大一倍。这相当于增加了存储空间,从而减小了发生冲突的概率。
多数组的情况
一般情况下,哈希表只使用一个数组来存储桶。但在一些特殊的场景下,可能会用到多个数组:
- 分布式哈希表(DHT):在分布式系统中,数据分布在不同的服务器上,可以视作多个“数组”分布在不同节点上。
- 分区哈希表:在特定应用场景中,有时会对哈希表进行分区,每个分区对应一个独立的数组,以实现分片存储或负载均衡。
总结
在常见的哈希表实现(如 HashMap)中,通常是一个大数组来管理桶,在冲突发生时每个桶内可能使用链表或红黑树等结构存储多个值。
JDK HashMap
是的,HashMap 是基于哈希实现的。在 JDK 的 HashMap 中,底层实现利用了数组 + 链表 + 红黑树的结构来存储键值对。其主要原理包括以下几个关键步骤:
哈希计算
HashMap 使用键的 hashCode() 方法来计算哈希值。计算哈希值后,会进一步通过位运算来优化分布,从而减少哈希冲突。具体来说,HashMap 会对哈希值进行一次扰动处理,使得高位和低位信息更加均匀地影响到数组索引。
例如,在 JDK 8 中使用了以下计算方法:
1 | static final int hash(Object key) { |
数组索引映射
HashMap 的底层是一个数组,称为桶数组。通过 (n - 1) & hash 的操作,哈希值被映射到数组的某个索引位置(其中 n 是桶数组的长度,且 n 始终为 2 的幂)。这种位运算的方式比取模运算更加高效。
处理哈希冲突
如果多个键的哈希值映射到了相同的数组索引(即发生哈希冲突),HashMap 会在该索引处使用链表或红黑树来存储这些冲突的键值对。
- 链表:在 JDK 8 及之前,当冲突的键较少时,
HashMap使用链表将冲突的键连接起来。链表的插入操作简单,但是查找速度是O(n)。 - 红黑树:在 JDK 8 中,如果某个桶中的元素数量超过一定阈值(默认是 8),链表会转化为红黑树结构,从而提升查找效率至
O(log n)。
动态扩容
当 HashMap 的负载因子(元素个数 / 数组容量)超过某个阈值(默认是 0.75),HashMap 会进行扩容。扩容会将桶数组的大小扩大为原来的两倍,并重新分配所有元素的位置。这一过程称为rehash,它会重新计算所有键的索引,以减少哈希冲突。
总结
JDK 中的 HashMap 是通过哈希函数来计算键的哈希值,并将其映射到数组的索引。遇到冲突时,采用链表或红黑树存储方式,并通过动态扩容和重哈希来保证存取效率。
布隆过滤器
BitMap
当你往简单数组或列表中插入新数据时,将不会根据插入项的值来确定该插入项的索引值。这意味着新插入项的索引值与数据值之间没有直接关系。这样的话,当你需要在数组或列表中搜索相应值的时候,你必须遍历已有的集合。若集合中存在大量的数据,就会影响数据查找的效率。
针对这个问题,你可以考虑使用哈希表。利用哈希表你可以通过对 “值” 进行哈希处理来获得该值对应的键或索引值,然后把该值存放到列表中对应的索引位置。这意味着索引值是由插入项的值所确定的,当你需要判断列表中是否存在该值时,只需要对值进行哈希处理并在相应的索引位置进行搜索即可,这时的搜索速度是非常快的。

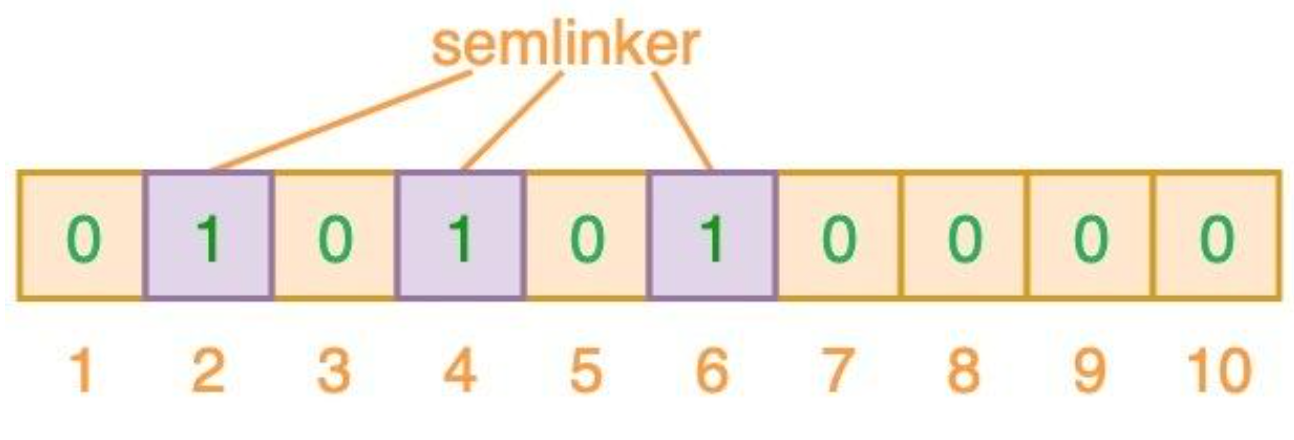
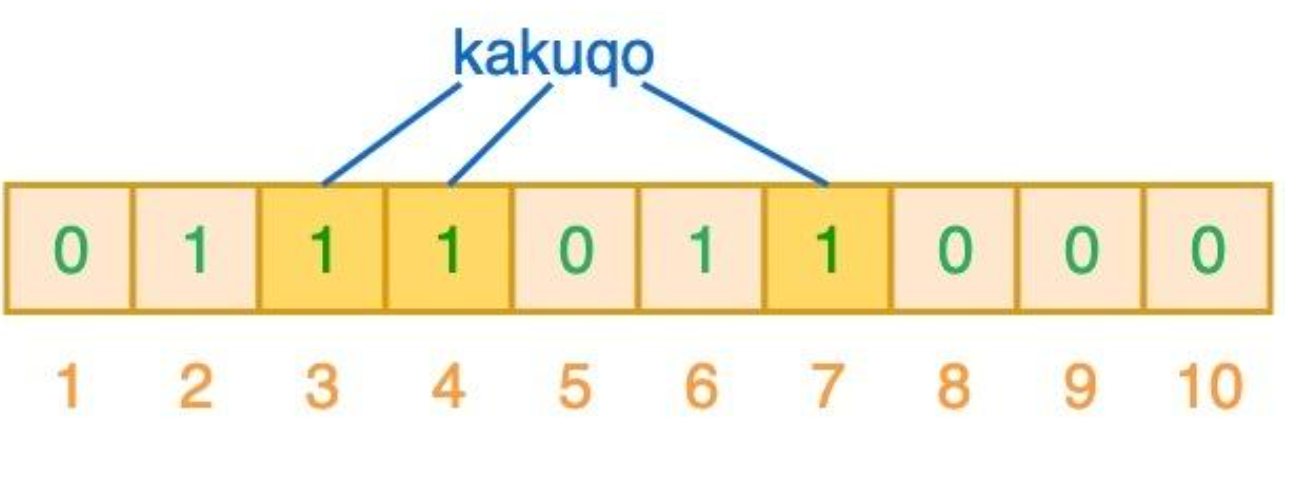
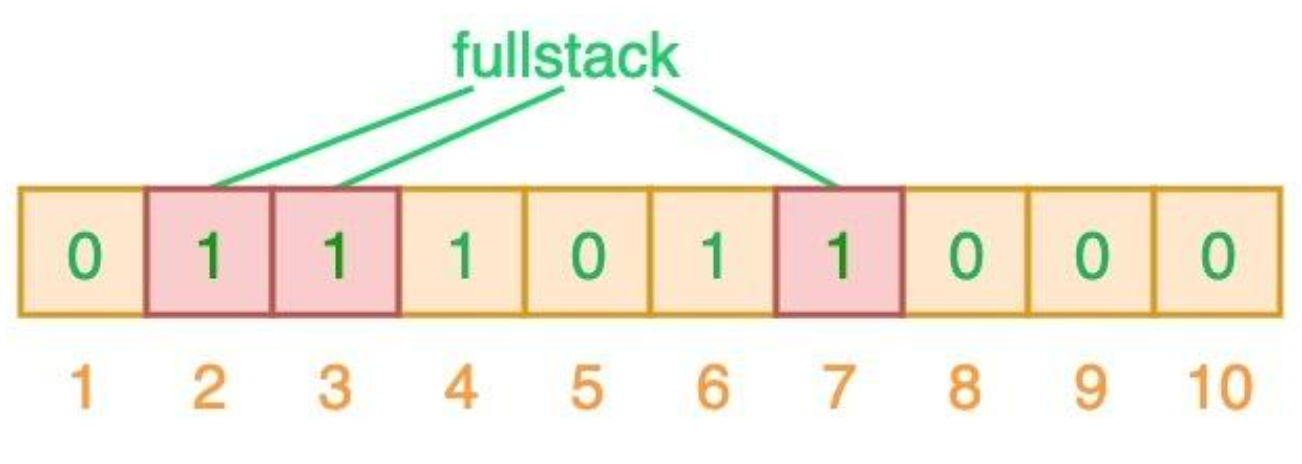
插入数据时顺便将数据键添加进布隆过滤器中,会根据n个哈希函数计算出n个索引,随后将这些索引位置1,因为哈希函数存在碰撞的可能,所以要计算出多个哈希值,图中使用了3个哈希值,fullstack和semlinker出现了完全重复,这就导致了误判。
布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在
如果哈希运算后任何一个索引位为0,则肯定不存在,否则可能存在
误判率
幸运的是,布隆过滤器有一个可预测的误判率(fpp):
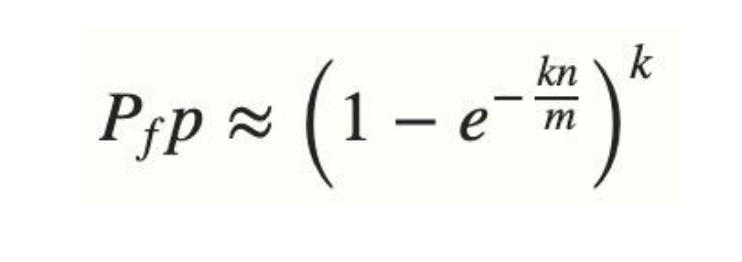
- n 是已经添加元素的数量;
- k 哈希的次数;
- m 布隆过滤器的长度(如比特数组的大小);
- 下图为 (k,fpp) 的关系图,m固定,随着 k 的增大,fpp先增大后减小,最小值出现在 k = m ln2 / n。
- 插入n也就是
expectedInsertions多了,要想维持原来的fpp,就必须增大 k 来减少哈希冲突,或者增大m
- 插入n也就是
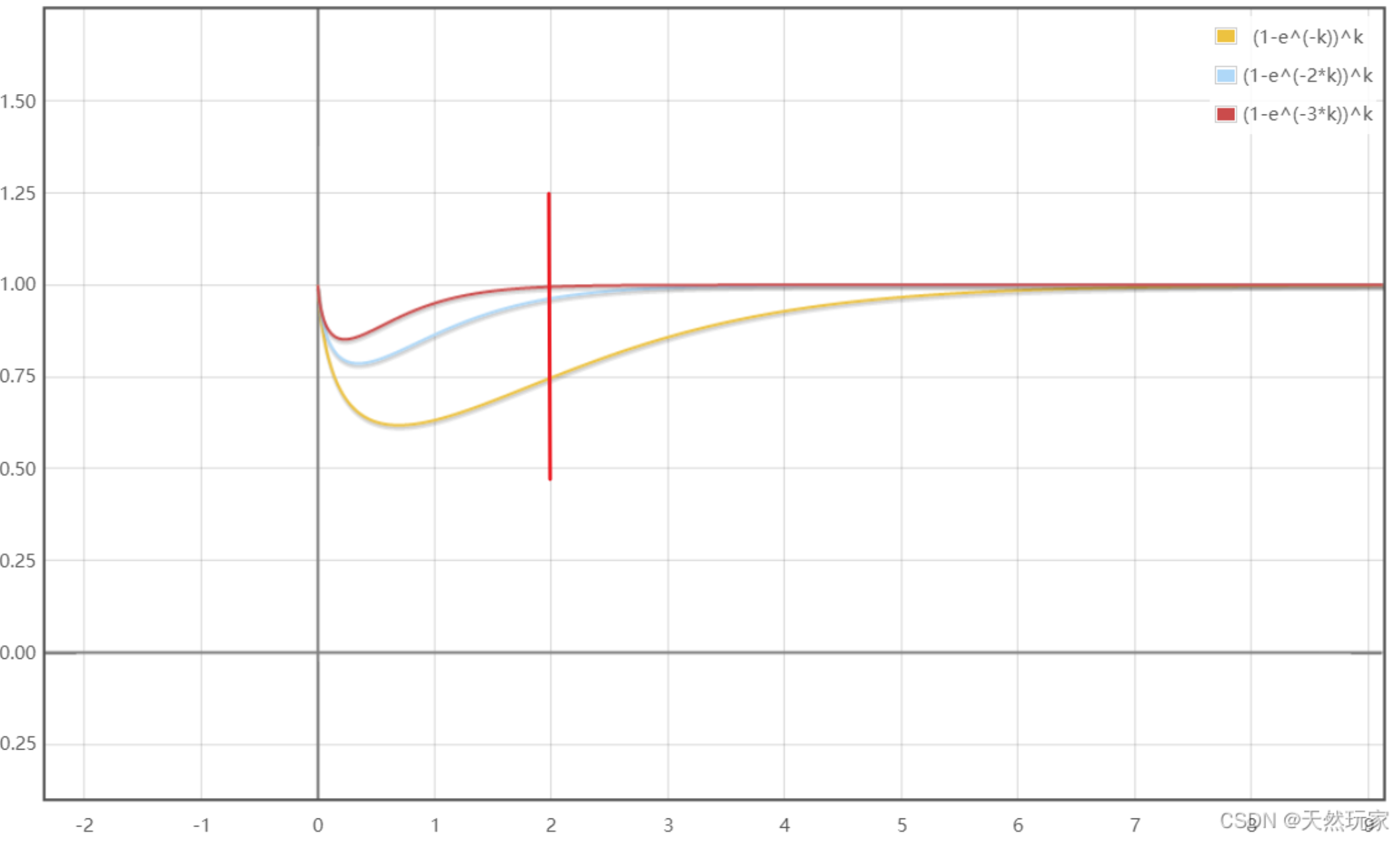
极端情况下,当布隆过滤器没有空闲空间时(满),每一次查询都会返回 true 。这也就意味着 m 的选择取决于期望预计添加元素的数量 n ,并且 m 需要远远大于 n 。
expectedInsertions越大,为了保持相同的fpp,所需的 bit 数组也越长(m增大)。fpp越小(越精确),需要更多的 bit 数组和哈希函数来降低冲突风险。expectedInsertions和fpp是你在初始化布隆过滤器时必须设定的两个指标,系统根据这两个值计算出m和k。

最佳实践:Guava
guava的布隆过滤器直接使用即可
1 | // 创建布隆过滤器对象 |