MyBatis-Plus
大家在日常开发中应该能发现,单表的CRUD功能代码重复度很高,也没有什么难度。而这部分代码量往往比较大,开发起来比较费时。
因此,目前企业中都会使用一些组件来简化或省略单表的CRUD开发工作。目前在国内使用较多的一个组件就是MybatisPlus.
当然,MybatisPlus不仅仅可以简化单表操作,而且还对Mybatis的功能有很多的增强。可以让我们的开发更加的简单,高效。
通过今天的学习,我们要达成下面的目标:
- 能利用MybatisPlus实现基本的CRUD
- 会使用条件构建造器构建查询和更新语句
- 会使用MybatisPlus中的常用注解
- 会使用MybatisPlus处理枚举、JSON类型字段
- 会使用MybatisPlus实现分页
快速入门
创建boot模块
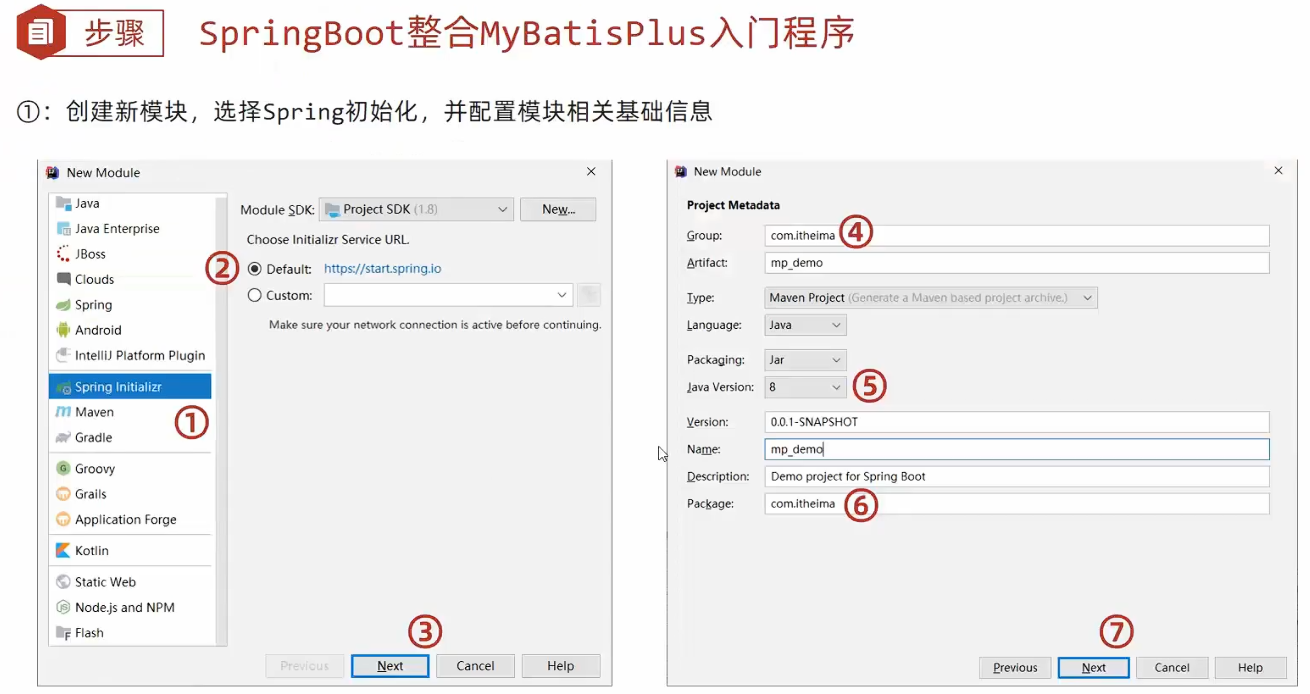
勾选JDBC驱动
不勾mybatis
添加mp, druid依赖
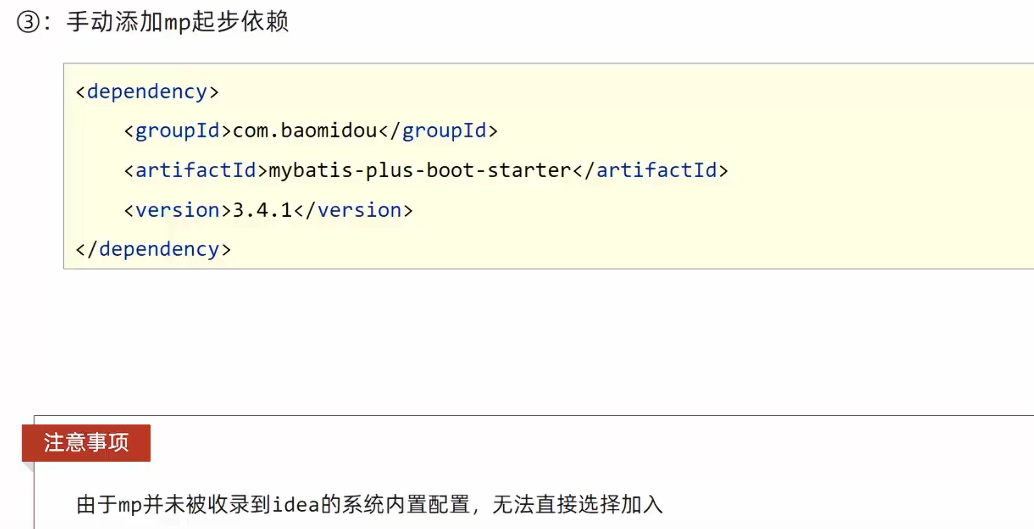
设置数据源参数
继承 BaseMapper<User>

特色



标准数据层开发—DAO 层
pojo实体类注意
字段映射
类名映射表名
Mybatis X 插件 | MyBatis-Plus (baomidou.com)
未指定映射表明,会将驼峰命名转化为下划线命名:
User -> user UserModel->user_model
驼峰命名字段自动映射表字段名
全局配置 驼峰映射mapUnderscoreToCamelCase
- 类型:
boolean - 默认值:
true
开启自动驼峰命名规则(camel case)映射,即从经典数据库列名 A_COLUMN(下划线命名) 到经典 Java 属性名 aColumn(驼峰命名) 的类似映射。
studentNum->student_num student->student
Lombok
简化pojo @Data
@Getter @Setter @EqualsAndHashCode @ToString @RequiredArgsConstructor
一键生成上述所有@Data
@AllArgsConstructor:生成全参构造@NoArgsConstructor:显式生成无参构造
record类 & 不可变对象 @Value
不可变对象 JDK14开始引入record类,用来表示一个不可变的实体类。所有字段都为private final,类也为final,也不能继承其他类,只有一个全参构造器。getName()变成name()
不可变对象@Value:所有字段都为private final,类也为final,只提供@Getter不提供@Setter,,只提供全参构造不提供无参构造。
简单基本属性要用包装类
比如Long Integer Byte Double Boolean Character Float Boolean Short
Lombok @Builder 建造者模式
1 | import lombok.Builder; |
Lombok 会为类自动生成以下内容:
- 一个静态内部类
UserBuilder(构建器) - 链式方法(如
.name(),.age()) build()方法用于最终构造对象
生成的代码示例:
1 | public class User { |
生成的 build() 方法会调用全参构造函数,若类中未显式定义全参构造,需配合 @AllArgsConstructor 使用。
最佳实践
链式构造 + 不可变对象
1 | // 自动生成getter、setter、equals、hashCode、toString requiredargsconstru |
RequiredArgsConstructor 只关注 final 以及 nonnull 字段。
处理继承问题
- 避免
@Data在继承场景
父类和子类同时使用@Data可能导致equals/hashCode忽略父类字段,手动重写更安全。 - 显式排除字段
使用@ToString(exclude = "password")或@EqualsAndHashCode(exclude = {"id"})避免敏感字段泄露或循环引用。
日志框架 @Slf4j
1 |
|
@SneakyThrows 偷偷抛出异常
明确异常类型
建议显式指定@SneakyThrows抛出的异常类型,避免隐藏潜在问题:1
2// ✅ 明确异常类型
// @SneakyThrows // ❌ 不推荐(捕获 Throwable,可能隐藏其他异常)
1 | import lombok.SneakyThrows; |
DQL编程控制
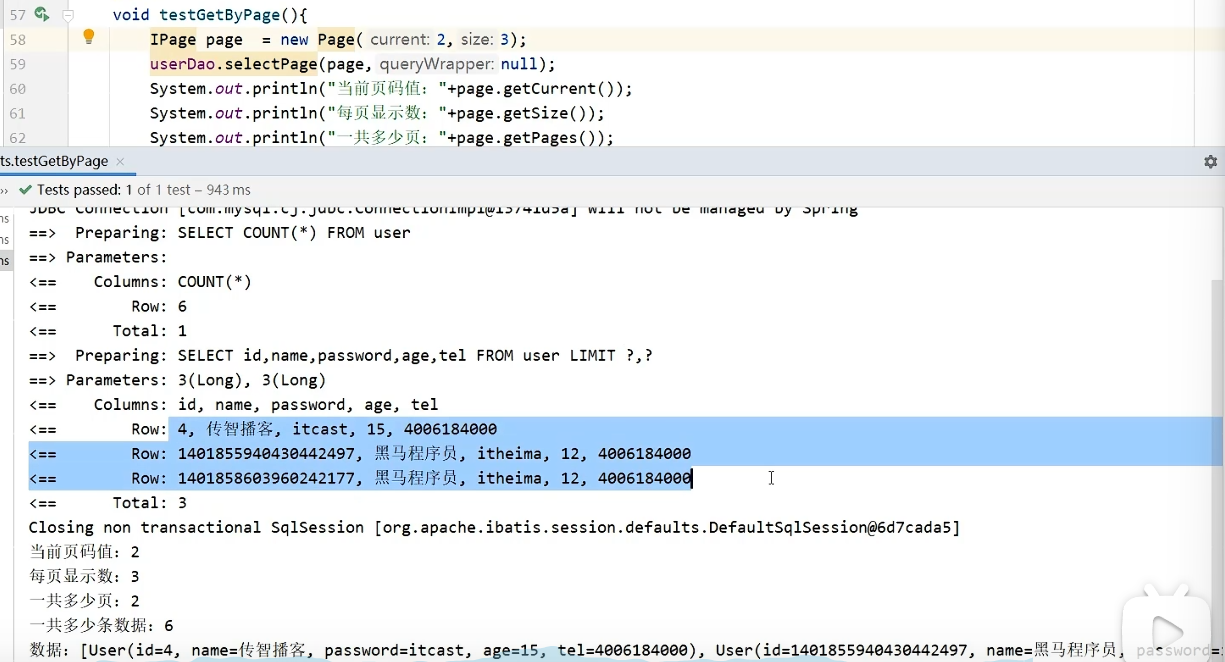
分页查询
配置分页拦截器作为Spring管理的Bean

1 |
|
封装页面数据—IPage
相当于原来的PageBean功能

开启日志:观察执行过程

查询条件
条件构造器 | MyBatis-Plus (baomidou.com)
大小关系
等值匹配 eq
lqw.eq(User::getName,"Jerry").eq(User::getPassword,"jerry")
userDao.selectOne(lqw) 没有必要用List
范围匹配 le lt ge gt between
lqw.between(User::getAge,10,30)
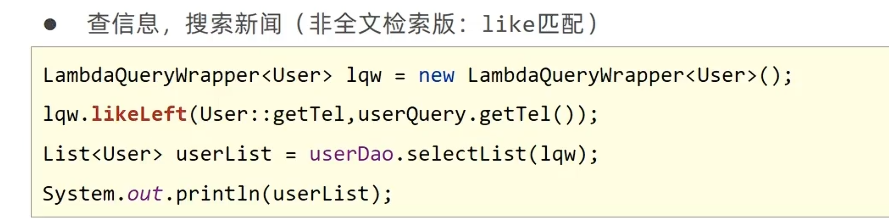
模糊匹配 like
lqw.like(User::getName,"J") -> J%,默认是likeRight 百分号在右边
分组查询聚合函数select, groupBy
QueryWrapper 封装查询条件
查询多条数据,返回List<User> userDao.selectList(queryWrapper)
按照条件查询(QueryWrapper)
1 | QueryWrapper qw = new QueryWrapper(); //通过反射读取字段名称,不用加泛型 |
Lambda方式按照单条件查询(QueryWrapper) -支持链式编程
秒懂Java之方法引用(method reference)详解-CSDN博客
1 | QueryWrapper<User> qw = new QueryWrapper<User>();//泛型 |
QueryWrapper的lambda()方法返回一个LambdaQueryWrapper
qw.lambda().lt(...)⇔lqw.lt(...) 链式编程

Lambda方式按多条件查询(LambdaQueryWrapper)
and—直接增加条件
1 | //age大于5小于10 |
or—条件之间插入or()
1 | //age大于10或小于5 |
条件查询null判定
多查询条件有的时候可能部分为null,查询模型和真正的实体类数据模型不同,查询模型是交给QueryWrapper,而QueryWrapper应该仅根据这个查询模型就能解析出所有的条件,所以应该为查询模型单开一个类,继承自User,把可能会有多条件查询的属性增加一个,分别表示这个属性的上限和下限。

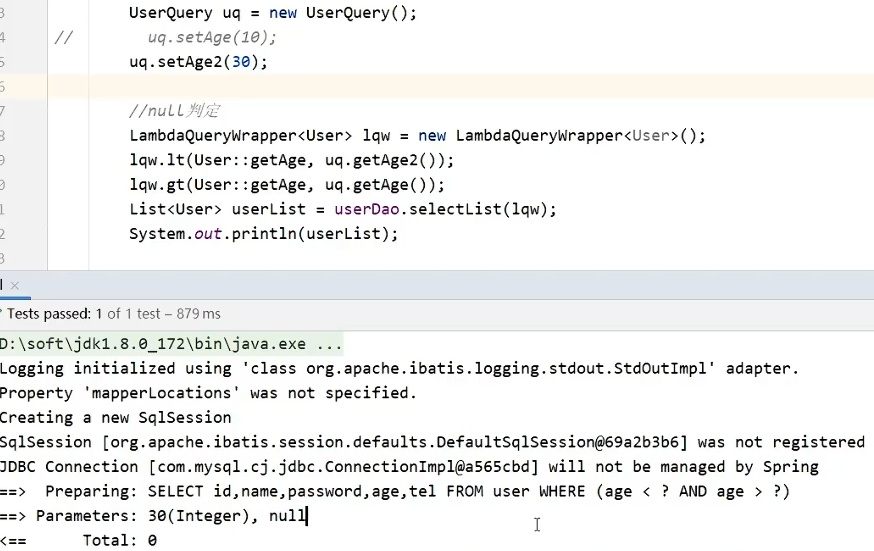
如上图所示,没有设置下限,只设置上限,本意是想去除一个查询条件,但实际上并未去除,而是传进去一个null,导致无效查询,我们要做的就是当null的时候就忽略掉这个查询条件 lqw.lt(condition,column,value) 在条件函数中加一个conditionuq.getAge()!=null

查询投影 (lqw.select)
只查询模型中定义的部分字段
lqw.select(User::getId,User::getAge,User::getName)
lqw.select("id","age","name")
userDao.selectList(lqw)
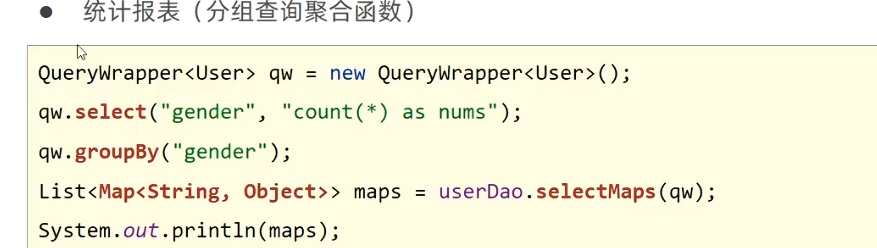
查询模型中未定义的字段(count(*)) lqw.selectMaps()
lqw.select("count(*)") 查询具体字段,就像写sql一样,可以加别名as xxx不支持lambda形式
userDao.selectMaps(lqw)

group by

实体模型与表字段不匹配
字段映射 @TableField
一般情况下我们并不需要给字段添加@TableField注解,一些特殊情况除外:
- 成员变量名与数据库字段名不一致
- 成员变量是以
isXXX命名,按照JavaBean的规范,MybatisPlus识别字段时会把is去除,这就导致与数据库不符。 - 成员变量名与数据库一致,但是与数据库的关键字冲突。使用
@TableField注解给字段名添加转义字符:````
支持的其它属性如下:
| 属性 | 类型 | 必填 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | “” | 数据库字段名 |
| exist | boolean | 否 | true | 是否为数据库表字段 |
| condition | String | 否 | “” | 字段 where 实体查询比较条件,有值设置则按设置的值为准,没有则为默认全局的 |
| update | String | 否 | “” | 字段 update set 部分注入,例如:当在version字段上注解update=”%s+1” 表示更新时会 set version=version+1 (该属性优先级高于 e l 属性) |
| insertStrategy | Enum | 否 | FieldStrategy.DEFAULT | |
| updateStrategy | Enum | 否 | FieldStrategy.DEFAULT | 举例:IGNORED update table_a set column=#{columnProperty} |
| whereStrategy | Enum | 否 | FieldStrategy.DEFAULT | |
| fill | Enum | 否 | FieldFill.DEFAULT | 字段自动填充策略 |
| select | boolean | 否 | true | 是否进行 select 查询 |
| keepGlobalFormat | boolean | 否 | false | 是否保持使用全局的 format 进行处理 |
| jdbcType | JdbcType | 否 | JdbcType.UNDEFINED | JDBC 类型 (该默认值不代表会按照该值生效) |
| typeHandler | TypeHander | 否 | 类型处理器 (该默认值不代表会按照该值生效) | |
| numericScale | String | 否 | “” | 指定小数点后保留的位数 |
属性级别注解@TableField(value = “pwd”)
相当于ResultMap
value 指定实体类的字段对应的数据库表字段名
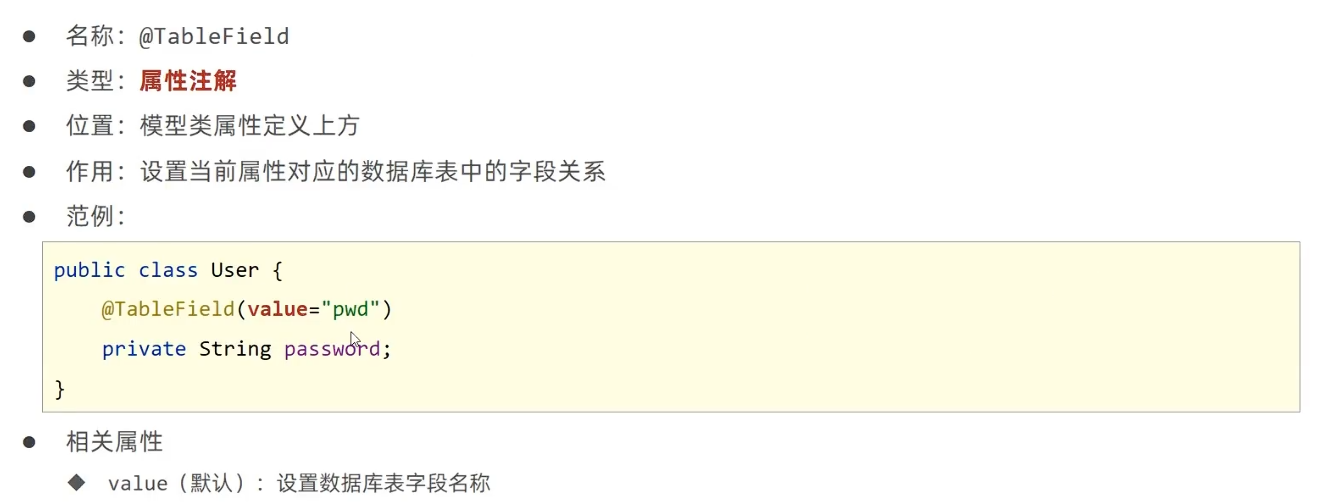
实体类中添加了表中不存在的字段@TableField(exist = false)
exist 设置属性在数据库表中是否存在,默认true,无法与value合并使用
设置属性是否包含在查询结果中@TableField(select = false)
与查询投影select不冲突,有些属性较为敏感,不能参与查询结果中
表名映射 @TableName

TableName注解除了指定表名以外,还可以指定很多其它属性:
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | “” | 表名 |
| schema | String | 否 | “” | schema |
| keepGlobalPrefix | boolean | 否 | false | 是否保持使用全局的 tablePrefix 的值(当全局 tablePrefix 生效时) |
| resultMap | String | 否 | “” | xml 中 resultMap 的 id(用于满足特定类型的实体类对象绑定) |
| autoResultMap | boolean | 否 | false | 是否自动构建 resultMap 并使用(如果设置 resultMap 则不会进行 resultMap 的自动构建与注入) |
| excludeProperty | String[] | 否 | {} | 需要排除的属性名 @since 3.3.1 |
DML编程控制
Insert 添加
id生成策略@TableId
在主键字段上方的注解
@TableId(type = IdType.AUTO)

TableId注解支持两个属性:
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | “” | 表名 |
| type | Enum | 否 | IdType.NONE | 指定主键类型 |
IdType支持的类型有:
| 值 | 描述 |
|---|---|
| AUTO | 数据库 ID 自增 |
| NONE | 无状态,该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT) |
| INPUT | insert 前自行 set 主键值 |
| ASSIGN_ID | 分配 ID(主键类型为 Number(Long 和 Integer)或 String)(since 3.3.0),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法) |
| ASSIGN_UUID | 分配 UUID,主键类型为 String(since 3.3.0),使用接口IdentifierGenerator的方法nextUUID(默认 default 方法) |
| ID_WORKER | 分布式全局唯一 ID 长整型类型(please use ASSIGN_ID) |
| UUID | 32 位 UUID 字符串(please use ASSIGN_UUID) |
| ID_WORKER_STR | 分布式全局唯一 ID 字符串类型(please use ASSIGN_ID) |
这里比较常见的有三种:
AUTO:利用数据库的id自增长INPUT:手动生成idASSIGN_ID:雪花算法生成Long类型的全局唯一id,这是默认的ID策略
默认策略 ASSIGN_ID—雪花算法
未指定id则生成一个随机id,是64位的二进制数,要求数据库主键用bigINT,实体类字段Long


application.yml 全局配置
全局id生成策略 id-type
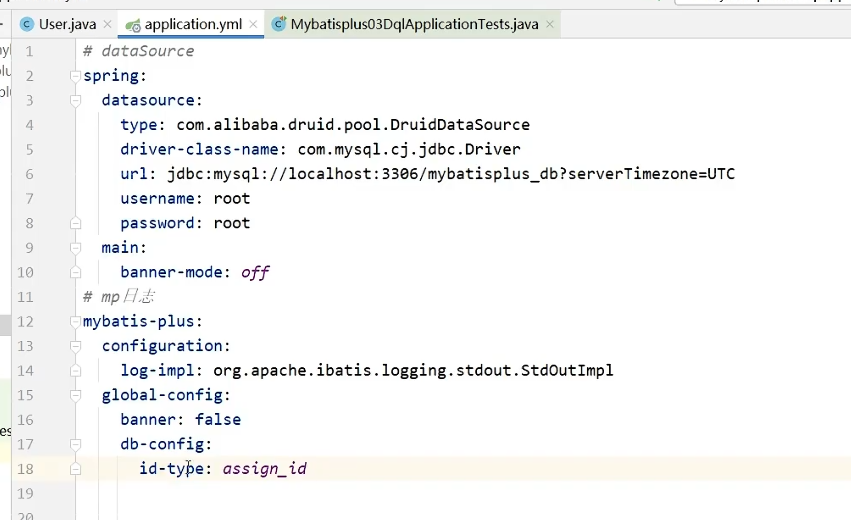
关键字:id-type
全局表名前缀 table-prefix
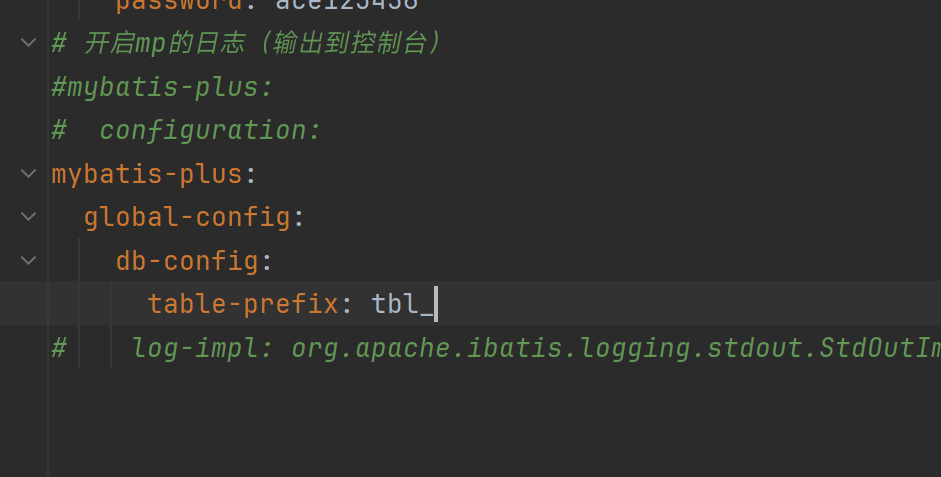
通过反射获取实体类名(User) 首字母小写,加上前缀拼成表名tbl_user
Delete 删除
多记录操作—批量删除
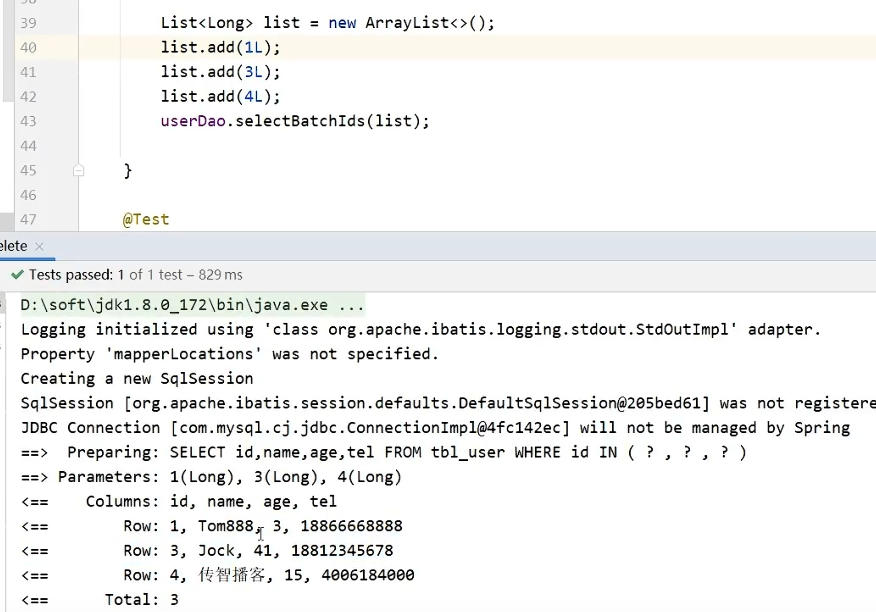
根据id批量删除 deleteBatchIds(list)

根据id批量查询selectBatchIds(list)
逻辑删除—减少物理删除行为
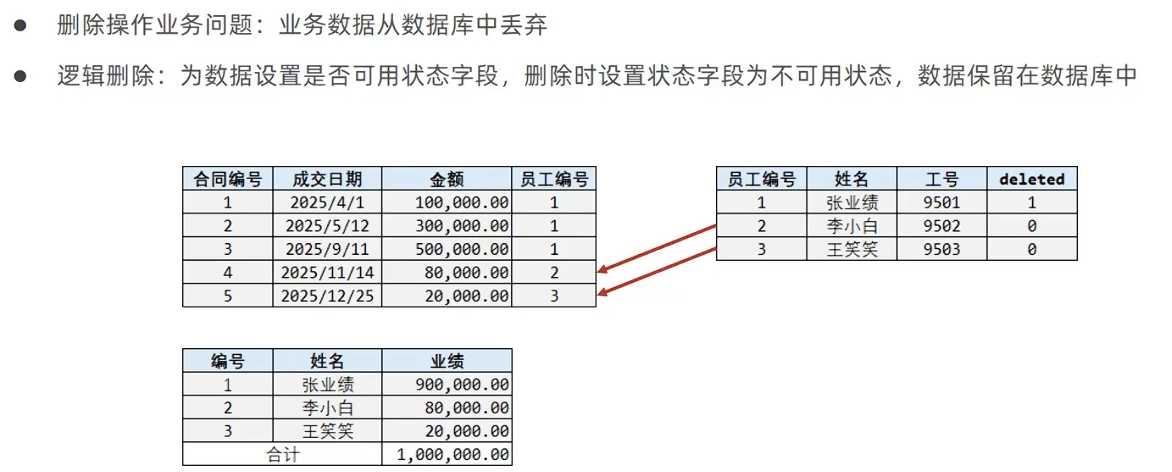
表里添加状态字段
deleted int(1) default 0
实体类添加状态字段@TableLogic(value = “0”, delval = “1”)
delval表示delete操作时(实际为update)将状态字段为0的行更新为1,value表示执行select时无条件追加状态字段=0的查询条件

对语句的影响
**delete操作变成update set deleted = 1 where id = 1 and deleted = 0 **
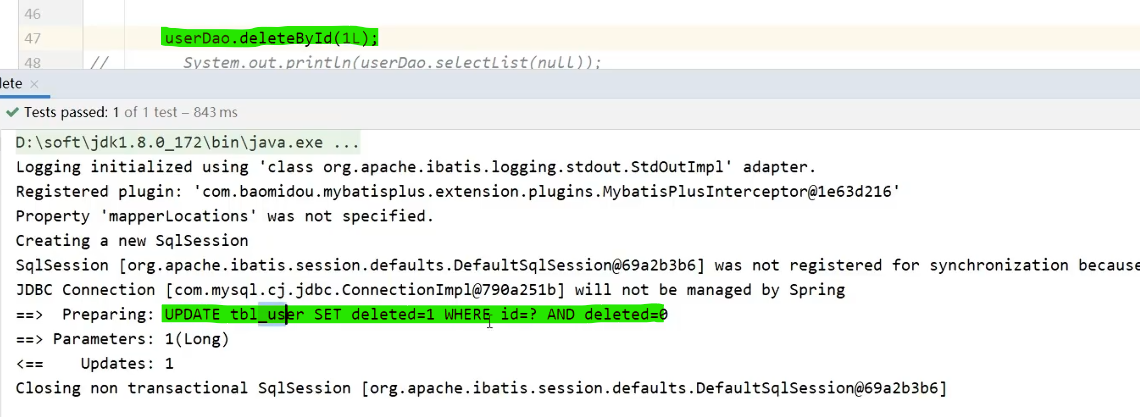
select操作最后添加一个where deleted=0,只查询未被删除的记录
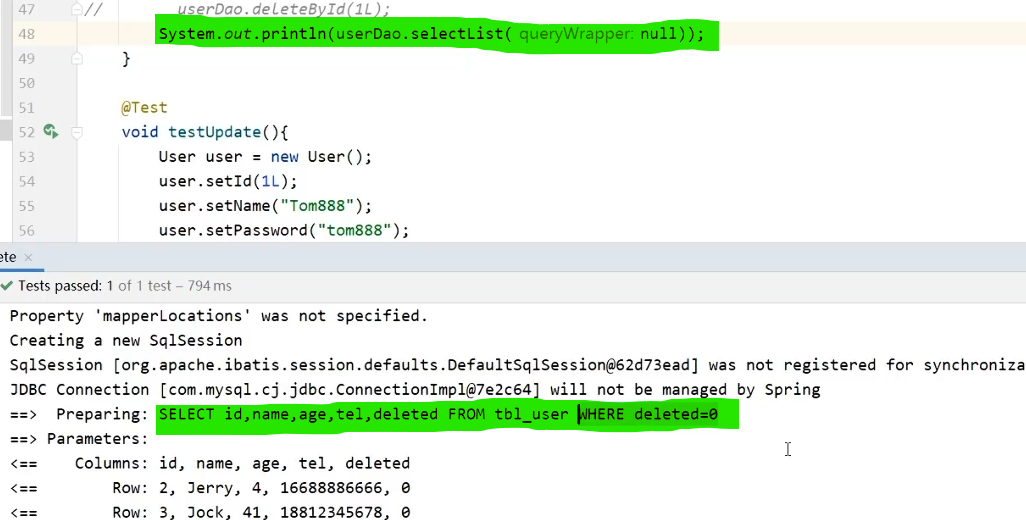
application.yml 全局配置逻辑删除属性
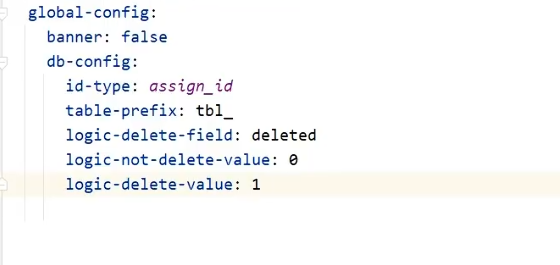
1 | # 删除状态字段名称(实体类的属性名) |
Update 修改
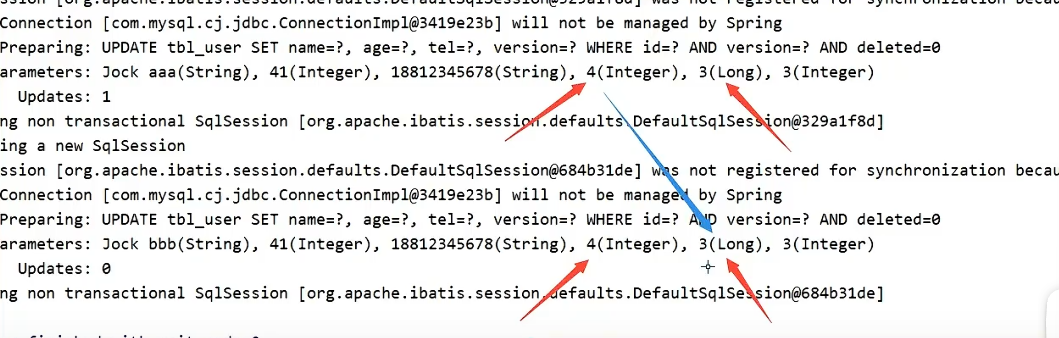
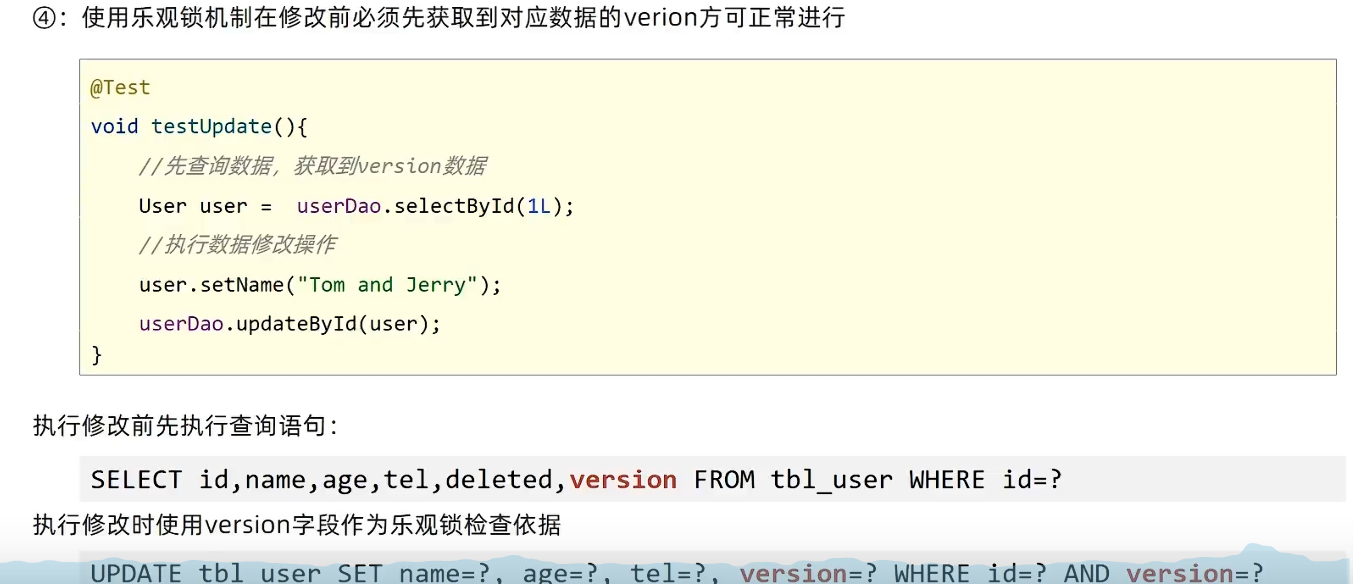
乐观锁—并发控制
添加version字段 @Version注解
数据库和实体类都要加,前面的改完将version自增,让后面的修改失效
配置拦截器
MpConfig : addInnerInterceptor OptimisticLocker
注意事项
- 收集到的实体类对象version属性不能为空
- 可以先将修改的数据查出来,然后逐一set属性值,这样不用手动设置version
- A,B同时来修改记录c,AB获取到的version都是4,A先修改,update语句中会自动给sql加上
set version = version + 1 where version = 4, 下一条执行的时候,SQL语句中的version依然是4,但是实际上version已经变成5,修改失效
Service 层
服务接口和实现类需要继承
接口需要继承IService<T> 实现类需要继承ServiceImpl<TMapper,T> T为实体类名
1 | public interface IBlogService extends IService<Blog> |
Mapper接口继承BaseMapper即可。
查 (get)
开始方法
对于复杂的查询:
query()可以拿到queryWrapper的链式调用 可以用这个开始查询,后面跟条件lambdaQuery()拿到lqw的链式调用
终结方法
count()作为终结方法可以返回查询结果的个数one()返回一个结果 类型为实体类list()将结果作为list返回page(Page page)返回某页的内容
增 (save)
删 (remove)
改 (update)
开始方法、结束方法
update() 更新语句必须以此开始,以此结束,返回的是boolean
中间方法
setsql(String sql) set的复杂表达式
中间使用条件语句
条件语句(中间方法)
- 大小关系:eq ne ge le gt lt
- 模糊匹配:like()
- where id in(1,2,3,4) : in(“id”, idList)
- last(): sql语句的最后一部分,可以添加orderByField等信息,手动拼字符串