并发集合框架
并发容器
并发安全 Map
ConcurrentSkipListMap: 跳表的实现。这是一个 Map,使用跳表的数据结构进行快速查找。
ConcurrentHashMap
JDK 1.7: Segment(ReentrantLock)
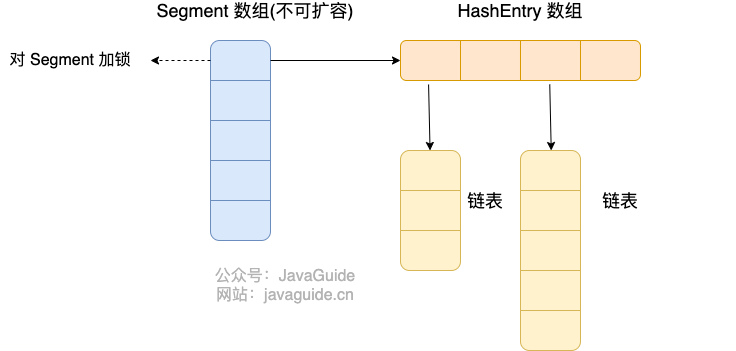
在 JDK1.7 的时候,ConcurrentHashMap 对整个桶数组进行了分割分段(Segment,分段锁),
JDK 1.7 采用 Segment 分段锁来保证安全, Segment 继承自 ReentrantLock。每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment数组中的每个元素包含一个HashEntry数组,每个HashEntry数组属于链表结构。
首先将数据分为一段一段(这个“段”就是 Segment)的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
Segment 继承了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
1 | static class Segment<K,V> extends ReentrantLock implements Serializable { |
一个 ConcurrentHashMap 里包含一个 Segment 数组,Segment 的个数一旦初始化就不能改变。 Segment 数组的大小默认是 16,也就是说默认可以同时支持 16 个线程并发写。
Segment 的结构和 HashMap 类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 的锁。也就是说,对同一 Segment 的并发写入会被阻塞,不同 Segment 的写入是可以并发执行的。
JDK 1.7 最大并发度是 Segment 的个数,默认是 16
JDK 1.8: Node+CAS+synchronized
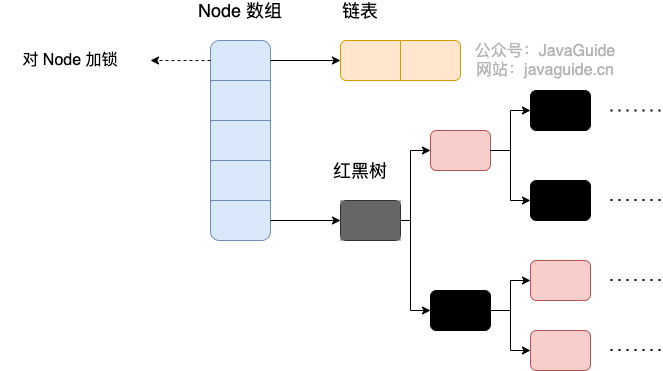
到了 JDK1.8 的时候,ConcurrentHashMap 已经摒弃了 Segment 的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6 以后 synchronized 锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;
JDK1.8 放弃了 Segment 分段锁的设计,采用 Node + CAS + synchronized 保证线程安全,锁粒度更细,synchronized 只锁定当前链表或红黑二叉树的首节点。
每个 桶(bucket) 对应一个链表或红黑树,用于解决哈希冲突。
如果链表长度超过一定阈值(默认为 8),链表会自动转换为红黑树,提高查询效率。
红黑树的情况需要使用
TreeNode。当冲突链表达到一定长度时,链表会转换成红黑树。TreeNode是存储红黑树节点,被TreeBin包装。TreeBin通过root属性维护红黑树的根结点,因为红黑树在旋转的时候,根结点可能会被它原来的子节点替换掉,在这个时间点,如果有其他线程要写这棵红黑树就会发生线程不安全问题,所以在ConcurrentHashMap中TreeBin通过waiter属性维护当前使用这棵红黑树的线程,来防止其他线程的进入。
JDK 1.8 最大并发度是 Node 数组的大小,并发度更大。
链表的线程安全性
在 ConcurrentHashMap 中,链表本身不是直接加锁的,而是通过更细粒度的CAS(Compare-And-Swap)机制和自旋锁来保证线程安全:
- 插入节点时通过 CAS 更新表头或表尾。
- 查询节点时允许并发读操作,而不会阻塞其他线程。
- 扩容操作采用链表迁移的方式,通过分段迁移减少阻塞时间。
不保证复合操作原子性
ConcurrentHashMap 是线程安全的,意味着它可以保证多个线程同时对它进行读写操作时,不会出现数据不一致的情况,也不会导致 JDK1.7 及之前版本的 HashMap 多线程操作导致死循环问题。但是,这并不意味着它可以保证所有的复合操作都是原子性的,一定不要搞混了!
复合操作是指由多个基本操作(如put、get、remove、containsKey等)组成的操作,例如先判断某个键是否存在containsKey(key),然后根据结果进行插入或更新put(key, value)。这种操作在执行过程中可能会被其他线程打断,导致结果不符合预期。
HashTable
Hashtable(同一把锁) :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低
并发安全 List
线程不安全 ArrayList
我们通常使用的ArrayList就是线程不安全的,举个简单的例子
1 | /** |
解决方案,有以下几种!
CopyOnWriteArrayList
1 | import java.util.concurrent.CopyOnWriteArrayList; |
写入时复制(CopyOnWrite,简称COW)思想是计算机程序设计领域中的一种通用优化策略。
CopyOnWrite容器即写入时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
读的时候不需要加锁,如果读的时候有多个线程正在向CopyOnWriteArrayList添加数据,读还是会读到旧的数据。CopyOnWrite并发容器用于读多写少的并发场景。
CopyOnWriteArrayList 比 Vector 厉害在哪里?
CopyOnWriteArrayList底层采用了Lock锁,是JDK层面的,效率高!
优缺点
优点:
- CopyOnWriteArrayList 并发安全且性能比 Vector 好。Vector 是增删改查方法都加了synchronized 来保证同步,但是每个方法执行的时候都要去获得锁,性能就会大大下降,而 CopyOnWriteArrayList 只是在增删改上加锁,但是读不加锁,在读方面的性能就好于 Vector。
- 线程安全的
List,在读多写少的场合性能非常好,远远好于Vector。
缺点:
- 数据一致性问题。这种实现只是保证数据的最终一致性,不能保证数据的实时一致性。在添加到拷贝数据而还没进行替换的时候,读到的仍然是旧数据。
- 内存占用问题。如果对象比较大,内存写操作的时候,需要拷贝数组,会消耗内存,如果原数组的内容比较多的情况下,可能导致 young gc 或者 full gc。 这个时候,我们应该考虑其他的容器,例如 ConcurrentHashMap。
- 由于实际使用中可能没法保证 CopyOnWriteArrayList 到底要放置多少数据,万一数据稍微有点 多,每次 add/set 都要重新复制数组,这个代价实在太高昂了。在高性能的互联网应用中,这种 操作分分钟引起故障。
Vector
Vector底层采用了Synchronized加锁的方式,保证了数据的安全性,但是效率低下!
解释一下:Synchronized是Java内置的机制,是JVM层面的,效率低是因为底层操作依赖于操作系统,操作系统切换线程要从用户态切换到内核态,花费很多时间。
并发安全 Set
线程不安全 HashSet
Set和List同样是多线程下不安全的集合类,同样会报并发修改异常!
1 | /** |
解决方案:
CopyOnWriteArraySet
1 | import java.util.concurrent.CopyOnWriteArraySet; |
和面试官谈到这里,一般都会问hashSet的底层实现原理。
底层其实就是用hashMap实现的

HashSet底层使用了哈希表来支持的,特点:存储快 往HashSet添加元素的时候,HashSet会先调用元素的HashCode方法得到元素的哈希值,然后通过元素的哈希值经过异或移位等运算,就可以算出该元素在哈希表中的存储位置。如果算出的元素存储的位置目前没有任何元素存储,那么该元素可以直接存储在该位置上;如果算出的元素的存储位置上目前已经有了其他的元素,那么还会调用该元素的equals方法 ,与该位置的元素进行比较一次,如果过equals方法返回的是true,那么该位置上的元素就会被视为重复元素,不允许被添加,如果false,则允许添加。
BlockingQueue
BlockingQueue 是 Java 并发包(java.util.concurrent)中的一个接口,专门用于线程安全的生产者-消费者模型。它支持线程在队列为空或已满时自动阻塞,从而简化了多线程编程中的同步问题。
特点
- 线程安全:
- 内部使用锁和条件变量(Condition)实现线程安全操作。
- 阻塞机制:
- 当队列为空时,获取元素的线程会被阻塞,直到队列中有可用元素。
- 当队列已满时,添加元素的线程会被阻塞,直到队列有空间。
- 常用场景:
- 生产者-消费者模型,生产者向队列中添加数据,消费者从队列中取数据。
- 控制线程执行顺序或流量,避免资源争抢。
BlockingQueue: 这是一个接口,JDK 内部通过链表、数组等方式实现了这个接口。表示阻塞队列,非常适合用于作为数据共享的通道。
分类
ArrayBlockingQueue
- best performance
- 单lock 双condition 算法,必须显式设置容量
- 底层是数组,有界队列,如果我们要使用生产者-消费者模式,这是非常好的选择。
LinkedBlockingQueue / LinkedBlockingDeque
- 2 locks 2 conditions,默认Integer.MAX_VALUE
- 底层是链表,可以当做无界和有界队列来使用,所以大家不要以为它就是无界队列。
SynchronousQueue
- 每次插入操作必须等待一个取出操作,否则就会阻塞,适合高并发传递数据。
- 不允许null
- 本身不带有空间来存储任何元素,使用上可以选择公平模式和非公平模式。
DelayQueue
- 延时队列,只有到期的元素才能被取出,适合定时任务或延迟执行场景。
- elements must implement
java.util.concurrent.Delayed
LinkedTransferQueue
- waits for consumer to consume the element (message passing need to be guaranteed)
ConcurrentLinkedQueue:
- 高效的并发队列,使用链表实现。一个线程安全的
LinkedList,这是一个非阻塞队列。
PriorityBlockingQueue
- concurrent version of
PriorityQueue - 无界队列,基于数组,数据结构为二叉堆,数组第一个也是树的根节点总是最小值。
- 基于优先级堆实现的无界阻塞队列,元素按优先级排序,不保证 FIFO。
主要方法: put-take offer-poll
add、remove实际上是对offer的封装
- 插入元素:
put(E e):如果队列已满,阻塞等待空间。offer(E e): 非阻塞插入offer(E e, long timeout, TimeUnit unit):带自旋的非阻塞插入
- 取出元素:
take():如果队列为空,阻塞等待数据。poll(): 非阻塞获取poll(long timeout, TimeUnit unit):带自旋的非阻塞获取
- 检查队列状态:
size():返回当前元素数量。remainingCapacity():返回剩余可用空间。
- 队列数据迁移
int elemCount = queue.drainTo(list);-
drainTo会一次性将队列中所有元素存放到列表,如果队列中有元素,且成功存到 list 中则drainTo会返回本次转移到 list 中的元素数,若队列为空,drainTo则直接返回 0
1 | import java.util.concurrent.*; |
ArrayBlockingQueue
实际上就是生产者——消费者模式的具体实现
加锁访问共享区域,阻塞使用的是和锁相关的condition条件变量,细化了等待条件
condition.await condition.signal/signalAll 就是使用了这个细节
1 | #define MAXSIZE 8 |