虚拟化
CPU Virtualization
进程(process)
操作系统:早期是一些函数库,然后发展出了保护的作用(内核态与用户态),之后是多道程序(多进程、多线程)
软件设计思维:分离机制与策略
- 机制:如何进行上下文切换?
- 策略:什么情况下,应该切换到谁?
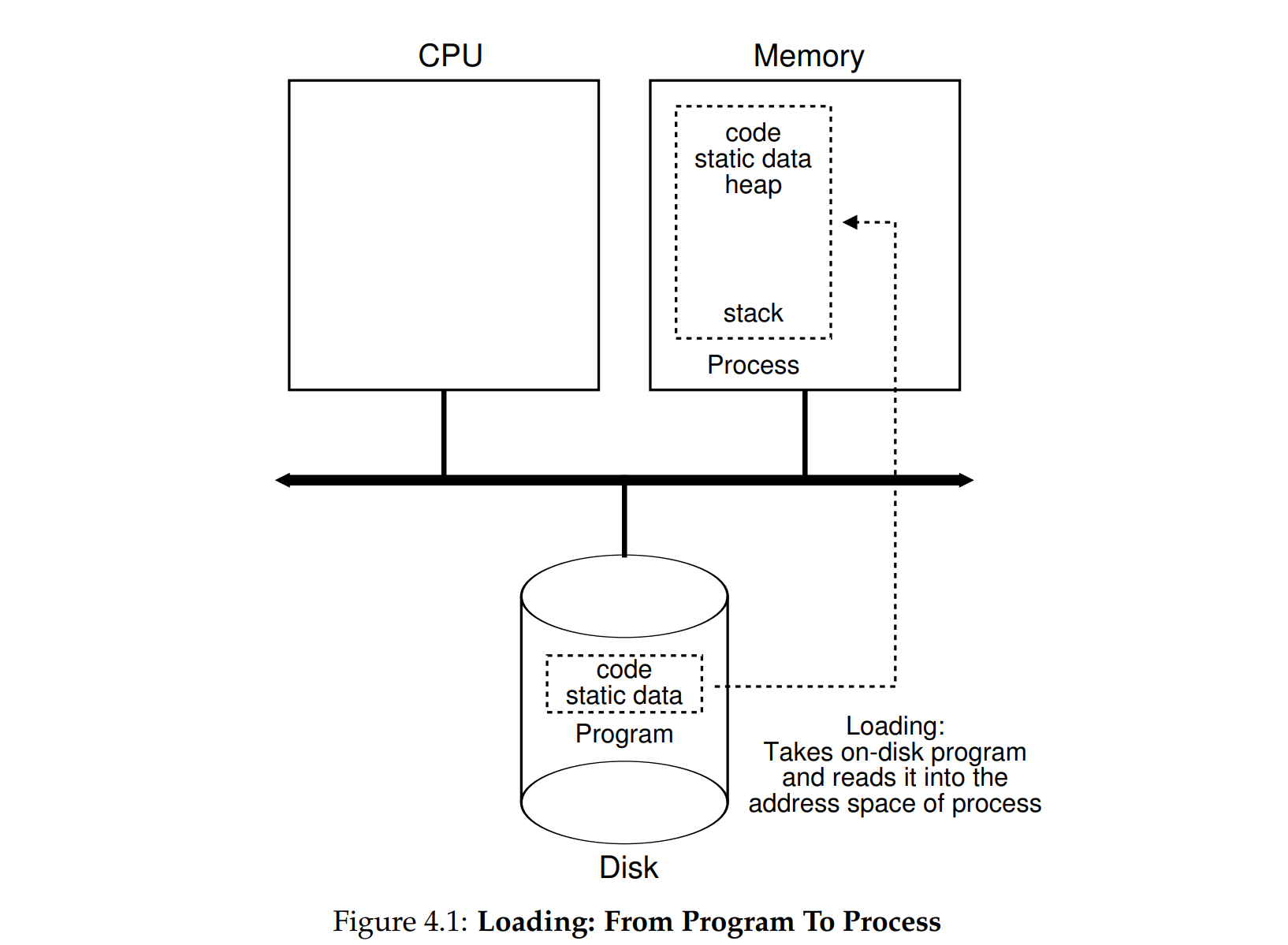
进程:程序没有运行的时候,就是硬盘中静态的代码,程序开始运行了,就在内存中开辟属于自己的空间,进程可以看作是操作系统对程序运行的一种抽象。
进程创建
- 内存地址空间,特定CPU寄存器的值
- 内存分配:程序代码、静态数据、运行时数据(包括堆栈和IO设置)
- 栈空间(Stack):可以由
main传参进行初始化,主要存放局部变量、函数参数和返回地址 - 用于IO的文件描述符(Descriptor):默认开启
stdinstdoutstderr三个文件 - 堆空间(Heap):用于在程序运行时动态地向OS申请一片内存(
malloc) - 在进程创建之后,OS将CPU控制权给到程序,开始执行
main
进程状态
加载到内存的进程基本状态如下三种
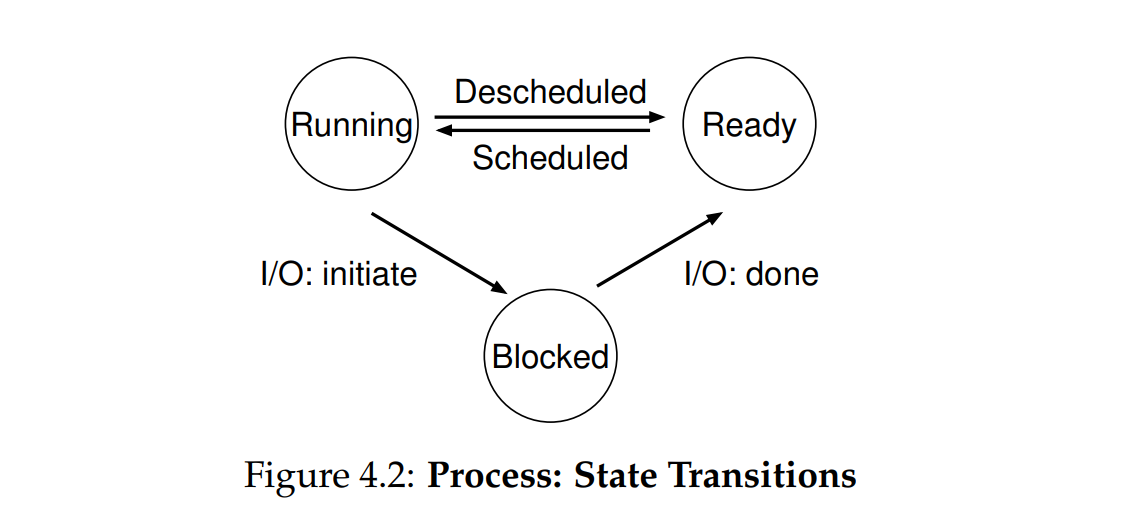
- 运行中:运行中的进程,也可以被反向调度
- 待运行(就绪):就绪的程序随时可以运行,等待调度
- 阻塞:程序运行到不需要CPU的部分(比如IO)就会到阻塞状态,等IO任务完成会变成就绪
- OS选择在进程发起IO时切换到别的进程,这样可以保持CPU繁忙,在IO结束时没有选择切换回去,这就是策略
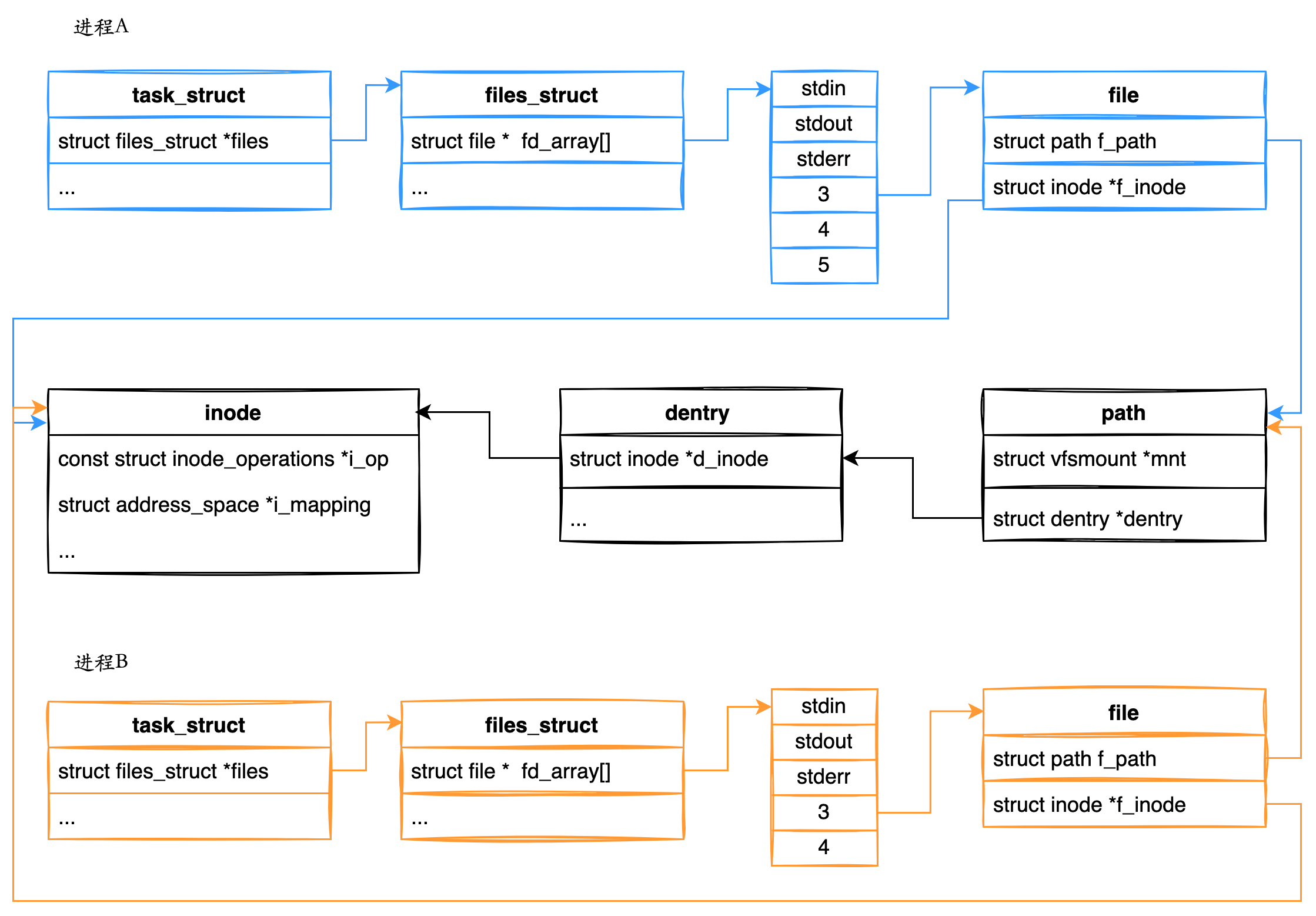
进程的数据结构
1 | // the registers xv6 will save and restore |
A process list contains information about all processes in the system. Each entry is found in what is sometimes called a process control block (PCB), which is really just a structure that contains information about a specific process.
- 上下文:指令指针、栈指针等都是CPU物理寄存器的内容,指令得以继续执行的关键,在恢复进程时很重要。
- 进程状态
- 其他的静态信息:进程地址空间,父进程、中断信息、打开的文件等。
进程API
fork wait exec
- fork:复制一个和父进程一样的子进程(子进程直接从fork返回然后继续执行)子进程的内存空间和父进程是独立的,并且变量的值大部分一样,
- wait:子进程创建后,根据OS调度(schedule)决定先后顺序,wait可以使父进程等子进程执行完再开始运行
- exec:当前进程不想运行和之前一样的代码,可以调用exec加参数运行其他代码,新的程序会替代原来进程的所有信息,因此exec后边的代码是不会被执行的。
shell
- shell的基本原理就是主进程fork wait 子进程这边exec 运行其他程序,运行完成主进程wait结束,继续进行其他操作
- 输出重定向(redirecting):默认输出就是标准输出流,如果你想重定向到一个文件,应当关闭stdout然后重新打开一个你想要的文件描述符。
- 管道(pipe):也类似与输出重定向,上一个的输出无缝作为下一个的输入
- 有用的cli工具:top(table of processes), ps(process status), man(manual)…
signals and users
For example, control-c sends a SIGINT (interrupt) to the process (normally terminating it) and control-z sends a SIGTSTP (stop) signal thus pausing the process in mid-execution (you can resume it later with a command, e.g., the fg built-in command found in many shells).
receive and process those signals within individual processes, and send signals to individual processes as well as entire process groups.
signal()可以使进程能够监听到上述这些信号,暂停现有程序执行,然后对信号做出一定的响应
Users generally can only control their own processes; it is the job of the operating system to parcel out resources (such as CPU, memory, and disk) to each user (and their processes) to meet overall system goals.
用户等级决定他们是否有权利发出某些特定的信号
机制:受限 直接执行
Limited Direct Execution
直接执行:直接在CPU上运行程序。
受限:一个进程要调用I/O,但是还不能让进程完全控制系统。
用户模式(user mode):应用程序不能完全控制硬件资源,如果硬要发起IO请求,CPU会出现异常,OS将终止进程
内核模式(kernel mode):操作系统可以完全掌控硬件。
When changing protection levels from user to kernel mode, the kernel shouldn’t use the stack of the user process, because it may not be valid. The user process may be malicious or contain an error that causes the user %esp to contain an address that is not part of the process’s user memory.
syscall & trap
系统调用(system call):允许内核小心地向用户暴露某些关键功能。执行trap指令,进入操作系统内核,将特权级别提升至内核模式,完成之后return from trap,返回值并将特权级别降低至用户模式。
Typical user applications run in user mode, and use a system call to trap into the kernel to request operating system services.
系统调用的参数放到一个指定的寄存器处,系统调用号也放到指定寄存器,需要仔细遵循约定来正确处理参数与返回值,高级语言通常屏蔽了底层硬件细节,因此需要使用汇编语言:
- 系统调用:用户程序通过陷阱指令请求内核服务(如文件操作、进程管理)。例如,在x86中:
1 | mov eax, 1 ; 系统调用号 (exit) |
- 中断处理:硬件设备通过中断向量触发陷阱,操作系统用汇编语言编写中断向量表。
- 异常处理:陷阱用于处理非法操作(如除零或非法内存访问)。
陷阱表(trap table):用户态不能执行io等直接操控底层硬件,否则就是非法的。进入内核态以后也不能随便寻址执行程序,必须跳到指定地址去执行对应的程序,这个指定的程序地址是内核(kernel)在启动时通过陷阱表告诉硬件的。用户程序也不能够识别陷阱表的内容。
The trap instruction saves register state carefully, changes the hardware status to kernel mode, and jumps into the OS to a pre-specified destination: the trap table.
When the OS finishes servicing a system call, it returns to the user program via another special return-from-trap instruction, which reduces privilege and returns control to the instruction after the trap that jumped into the OS
Limited Direct Execution Timeline:

要么是内核态要么是用户态,在用户进程开始执行之前(main)的准备工作肯定是由内核态完成,因此就要return from trap,切换到用户态。跳转到main函数
执行系统调用或者响应中断时,通过trap指令,cpu控制权腾给os,陷入内核态,执行的是与之前不同的程序,就需要保存执行的现场以便之后继续执行,将cpu寄存器上的内容先保存到内核栈(kernel stack)。
在系统调用结束之后把内核栈的内容弹出恢复到CPU寄存器上,切换回用户模式,继续执行之前的内容,最后main函数返回,同时通过exit()进行trap,进入内核态,做清理工作。
Limited Direct Execution(Timer Interrupt)
直接执行(Direct Execution):用户进程占用CPU,OS作为一个程序并没有在运行。问题在于OS如何重新获得CPU的控制权,以便在操控程序运行取得主动权。
协作:OS只能等待被动的系统调用或者触发异常才会重新获得CPU控制权。
非协作:时钟硬件设备可以编程为若干毫秒产生一次中断信号,CPU 检测到时钟中断信号后,暂停当前正在运行的任务,跳转到内核中预定义的中断服务例程(ISR, Interrupt Service Routine)处理
CPU必须在硬件层面实现能够保存用户程序运行的现场(trap的精髓)
操作系统处理时钟中断操作系统在时钟中断处理程序中执行以下任务:
更新系统时间。
检查是否需要切换任务(触发任务调度)。
处理延迟或周期性任务(如超时处理、定时器事件等)。
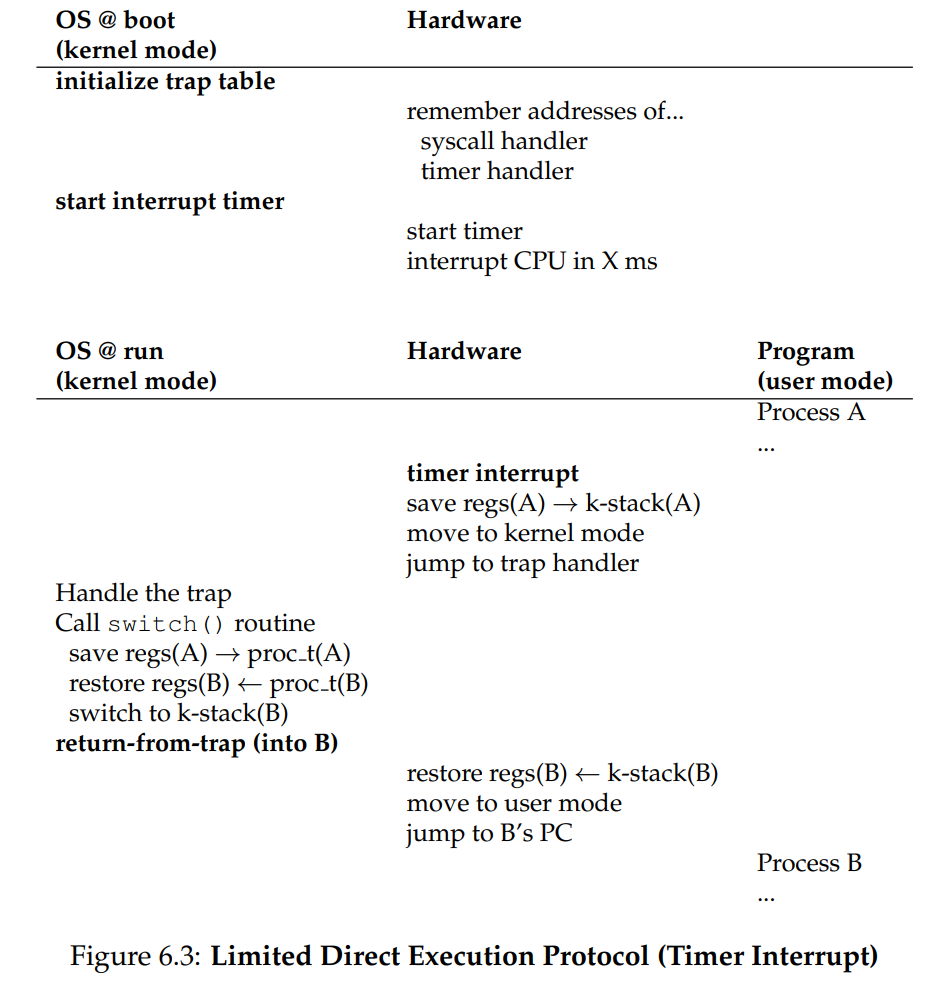
如图 hardware部分 需要在响应时钟中断时,把进程A的运行现场(寄存器)保存到内核栈中,然后跳转到trap处理程序。
上下文切换(context switch)
然后操作系统调用switch进行进程的切换A到B,因为一段时间内A都不会再运行,这时候就需要把A的寄存器内容保存到其进程空间(内存空间)
kernel stack vs Process Control Block
浅谈Linux 中的进程栈、线程栈、内核栈、中断栈 - 知乎
当进程在用户态运行时,使用的是用户栈,当进程陷入到内核态时,这些内核代码所使用的栈并不是原先进程用户空间中的栈,而是一个单独内核空间的栈,这个称作进程内核栈,内核栈保存进程在内核态运行的相关信息,一旦进程返回到用户态后,内核栈中保存的信息无效,会全部恢复,因此每次进程从用户态陷入内核的时候得到的内核栈都是空的。所以在进程陷入内核的时候,直接把内核栈的栈顶地址给堆栈指针寄存器就可以了。
当位于用户空间的进程进行系统调用时,进程用户栈的地址会被存进内核栈中,CPU堆栈指针寄存器中的内容也会变为内核栈的地址。当系统调用执行完毕,进程从内核栈找到用户栈的地址,继续在用户空间中执行,此时CPU堆栈指针寄存器就变为了用户栈的地址。各进程独立的。进程运行时分用户态跟内核态,所以需要有内核栈和常说的堆栈段,寻址方式是相同的,都是查LDT和页表进行地址映射,但二者段描述符里的特权级不同,为了区分用户态和内核态。
为什么每个进程都有一个内核栈,而不是所有进程共用一个。老的UNIX和Linux当时就是每个CPU只有一个内核栈,那个时候不会出现“执行到一半的时候上下文切换”,因为不允许用户态程序抢占正在执行系统调用的另一个用户态程序。后来每个进程一个内核栈了,就可以发生“执行到一半的时候上下文切换”了
语言书里面讲的堆、栈大部分都是用户态的概念,用户态的堆、栈对应用户进程虚拟地址空间里的一个区域,栈向下增长,堆用malloc分配,向上增长。
- 中断发生时,寄存器先保存到内核栈;如果需要切换进程,内核会将内核栈中的寄存器内容转存到进程结构中。
- 内核栈主要用于快速保存和恢复寄存器内容,适用于临时的上下文切换或中断处理。
- 进程结构适用于更复杂的进程调度和长时间的上下文切换,提供长期的状态保存。proc结构体中的context字段就是用来保存寄存器信息的(xv6)
| 方面 | 内核栈 | 进程结构(PCB) |
|---|---|---|
| 保存时机 | 短暂事件(如中断、系统调用) | 进程调度时 |
| 存储位置 | 当前进程的内核栈 | PCB 或其他持久性数据结构 |
| 存储时间 | 临时保存,内核处理结束后直接恢复 | 长期保存,直至进程切换回来 |
| 访问开销 | 较低,直接访问内核栈 | 较高,涉及更多内存操作 |
| 适用场景 | 快速上下文切换、临时中断处理 | 进程调度或长时间上下文切换 |
| 局限性 | 不能长期存储 | 开销大,需要额外的数据结构 |
| 优点 | 连续内存块,访问效率较高,内核处理完直接恢复 | 寄存器信息可以跨多个调度周期存储 |
进程调度,需要把B的现场信息从进程空间中恢复到寄存器里,然后恢复到用户态,跳转到B的PC,执行B的内容。
并发:系统调用时触发中断。
策略:CPU 调度
基本策略
批处理
FIFO:先到先得,计算密集型会阻塞io密集型,降低效率
SJF:Shortest Job First 最短工作优先,同时到达,先进行最短的工作
STCF:Shortest Time-to-Complete First 最短完成时间优先,针对随时到达的情况,到达时比较里完成还有多少时间,首次出现了任务切换的概念。
交互式
以上能够逐步优化 T周转 = T完成 - T到达,但是对于T响应 = T首次运行 - T到达 不友好,因为完成时间最长的必须等其他任务完成,自己才能继续。
交互式的任务对于响应时间很敏感。因此需要另外一种调度策略
RR:Round-Robin 轮转,运行一个任务到时间片就切换到下一个任务(context switch)
- 上下文的切换需要时间,因此时间片的大小也应该选择恰当
Overlap:重叠,如果A任务有IO,当A因为IO而空出CPU时,CPU就应该去服务B
不可预知性:调度程序不知道到来的任务持续多长时间。
实时系统
准时比准确更加重要
基于优先级且无需先验知识的调度:多级反馈队列 MLFQ
MLFQ:Multi-Level Feedback Queue,多级反馈队列
- 设置不同的优先级,每个任务刚到达都是最高级
- 级别低的任务必须先让级别高的执行完
- 相同级别的任务轮转执行
- 在同一个优先级执行时间达到阈值就降低优先级:防止高优先级一直占据CPU,如果采用每次执行的计时方法可能会有恶意占据CPU的情况发生
- 每隔一段时间就重置所有任务的优先级为最高:防止低优先级变成饥饿状态
Memory Virtualization
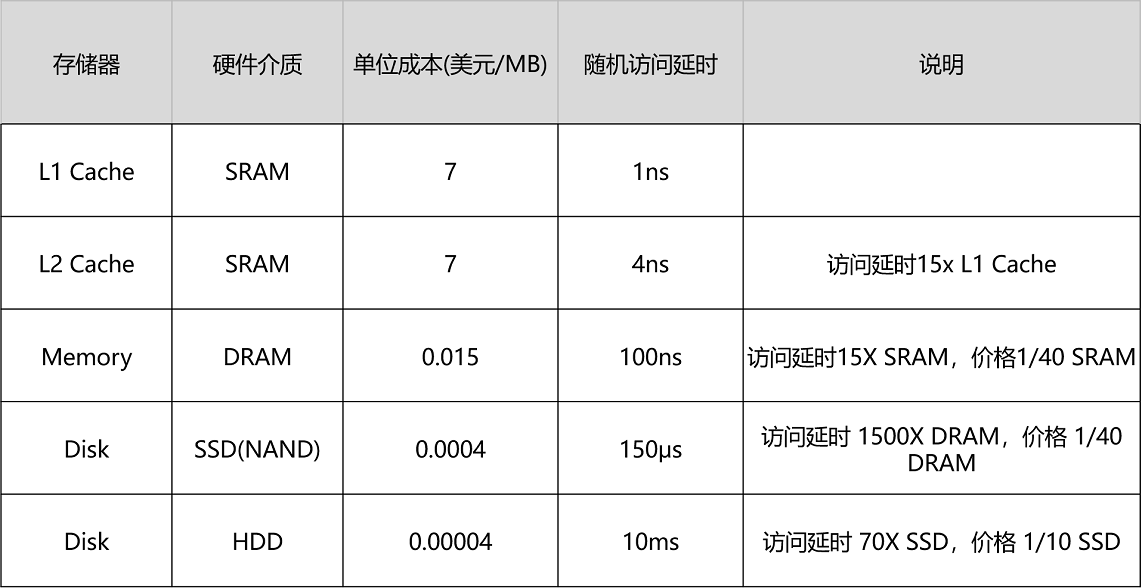
每个程序员都应该知道的时延
1 | L1 cache reference ......................... 0.5 ns |
虚拟地址空间

地址空间:程序认为自己独占了这片内存空间,以为自己是连续的内存空间。低位是代码,堆往上递增,栈往下反向增长。
实际上是在物理内存中申请了一片连续的内存空间分配给进程,进程根据指令寻址的时候,操作系统将虚拟地址 重定位 到真正的物理地址。虚拟地址从0开始,因此虚拟地址实际上就是物理地址的偏移量。直接打印指针变量的值是虚拟地址而不是物理地址。
虚拟内存的作用
隔离进程:物理内存通过虚拟地址空间访问,虚拟地址空间与进程一一对应。每个进程都认为自己拥有了整个物理内存,进程之间彼此隔离,一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存。
提升物理内存利用率:有了虚拟地址空间后,操作系统只需要将进程当前正在使用的部分数据或指令加载入物理内存。
简化内存管理:进程都有一个一致且私有的虚拟地址空间,程序员不用和真正的物理内存打交道,而是借助虚拟地址空间访问物理内存,从而简化了内存管理。
多个进程共享物理内存:进程在运行过程中,会加载许多操作系统的动态库。这些库对于每个进程而言都是公用的,它们在内存中实际只会加载一份,这部分称为共享内存。
提高内存使用安全性:控制进程对物理内存的访问,隔离不同进程的访问权限,提高系统的安全性。
提供更大的可使用内存空间:可以让程序拥有超过系统物理内存大小的可用内存空间。这是因为当物理内存不够用时,可以利用磁盘充当,将物理内存页(通常大小为 4 KB)保存到磁盘文件(会影响读写速度),数据或代码页会根据需要在物理内存与磁盘之间移动。
重定位(relocation)
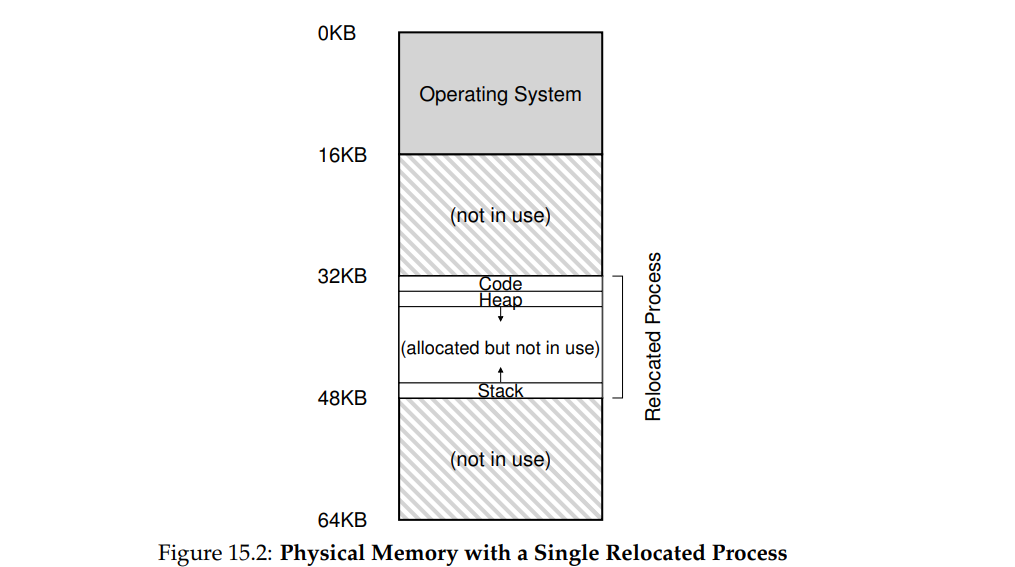
Virtual Address + Base = Physical Address
静态重定位:用软件实现,直接将指令中的虚拟地址用计算的真实物理地址覆盖。
- 缺点:不安全,不方便更改。
动态重定位:用硬件实现,也就是CPU中的==MMU==,里面两个最基本的寄存器:基址寄存器、界限寄存器。将指令中的虚拟地址和基址相加得出真实物理地址,然后取得从硬件层面取得对应地址的值。这一切都是用硬件进行的。
- 安全性:用界限(bound)和虚拟地址比较,如果超过了界限,说明虚拟地址访问越界,抛出异常
- 便于更改:改变寄存器的值即可实现基址的改变
- 性能高:硬件实现性能好

实现虚拟内存
实现虚拟内存机制的硬件支持:MMU
划分用户空间和内核空间
一对基址寄存器和界限寄存器,专门用来进行地址转换的电路
专门用来判断是否越界的电路,判断越界之后应当向CPU抛出异常
特权指令:操作系统应当能够设置上述寄存器的值
特权指令:操作系统应当告诉硬件发现异常应该执行哪些代码(Exception Handler)
实现虚拟内存机制的软件支持:OS
- 内存管理:分配机制、释放机制、空闲空间的管理——free list
- 切换上下文时正确设置对应的寄存器
- 抛出异常(内存访问越界、非法指令)时执行特定的处理代码
地址空间的不足:内部碎片(inner fragment)栈和堆之间未使用的空间也分配给整个地址空间,浪费较大
分段
segmentation
段式管理:以段(—段连续的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。然后给每个段都配一对基址寄存器和界限寄存器。
例:0-16KB的虚拟地址空间,虚拟地址14位,高2位为段号,低12位为最大4KB的段空间。虚拟地址 = 段号 + 偏移
1 | // get top 2 bits of 14-bit VA |

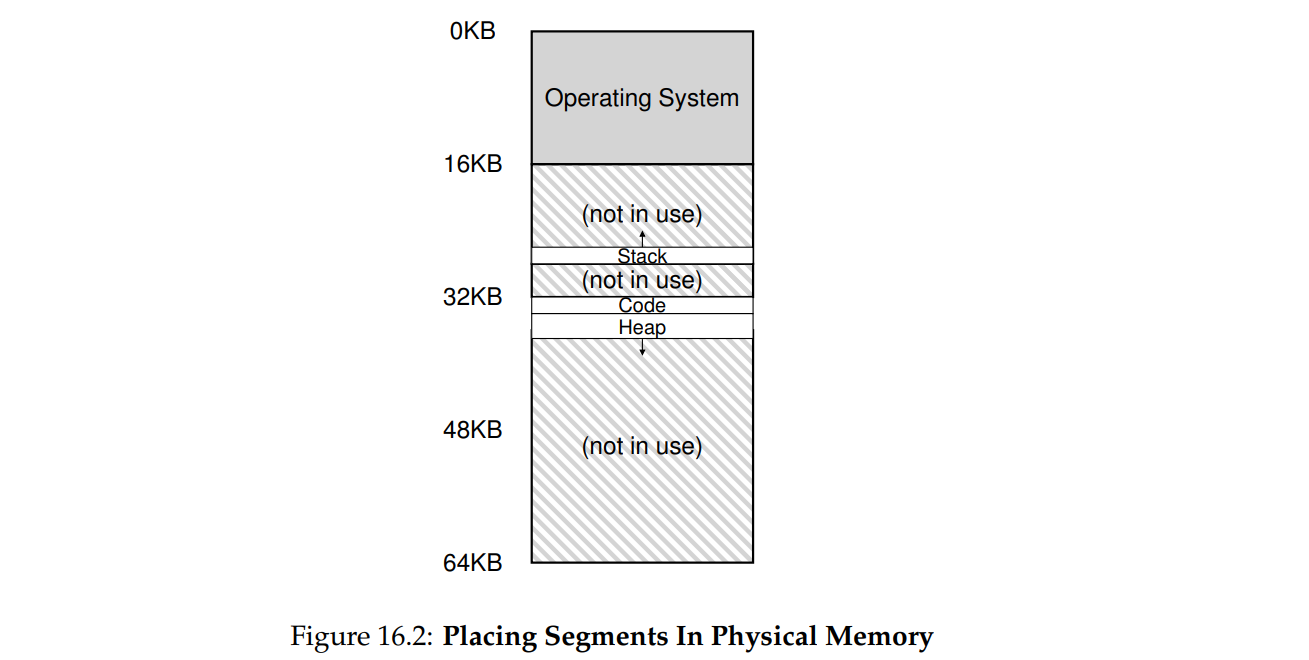
| 段名称 | 段号 | 基址寄存器 | 界限寄存器 | 是否正向增长 |
|---|---|---|---|---|
| 代码 | 00 | 26 KB | 2 KB | 1 |
| 堆 | 01 | 28 KB | 2 KB | 1 |
| 栈 | 11 | 18 KB | 2 KB | 0 |
现在要判断虚拟地址15KB的真实地址:11 11 00000 00000 可见段号为 11,偏移 3 KB,栈空间反向增长,最大段空间为 4 KB,实际上就是计算15KB离全1有多远:3KB - 4KB = -1 KB,因此在基址寄存器减1KB即为实际物理地址。
用于保护的额外状态字
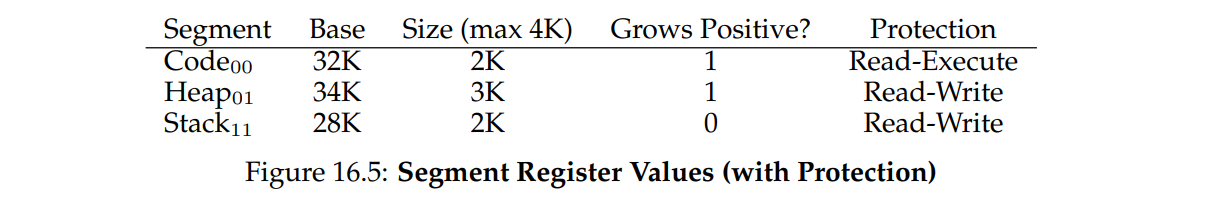
分段的问题
- 外部碎片:每个分段的大小不一致,因此产生了大小不一致的碎片,无法使空间得到有效利用。
- 不支持稀疏的大堆:Another problem is that some segments could have a larger size and since this segment can’t be “broken” into smaller pieces, it must be fully allocated in memory. 分段大小是固定的,并不能将其拆成小段,申请了一段物理内存,寄存器的基址和界限已经确定好,这部分物理空间就不能再由其他的进程使用了,因此不支持按需分配。
- Segments of unequal size not suited as well for swapping.
段表:更细粒度的分段
细粒度分段需要进一步硬件支持,并且在内存中存储 段表 (segment table)
分段机制下的虚拟地址由两部分组成:
- 段号:标识着该虚拟地址属于整个虚拟地址空间中的哪一个段。
- 段内偏移量:相对于该段起始地址的偏移量。
具体的地址翻译过程如下:
- MMU 首先解析得到虚拟地址中的段号;
- 通过段号去该应用程序的段表中取出对应的段信息(找到对应的段表项);
- 从段信息中取出该段的起始地址(物理地址)加上虚拟地址中的段内偏移量得到最终的物理地址。
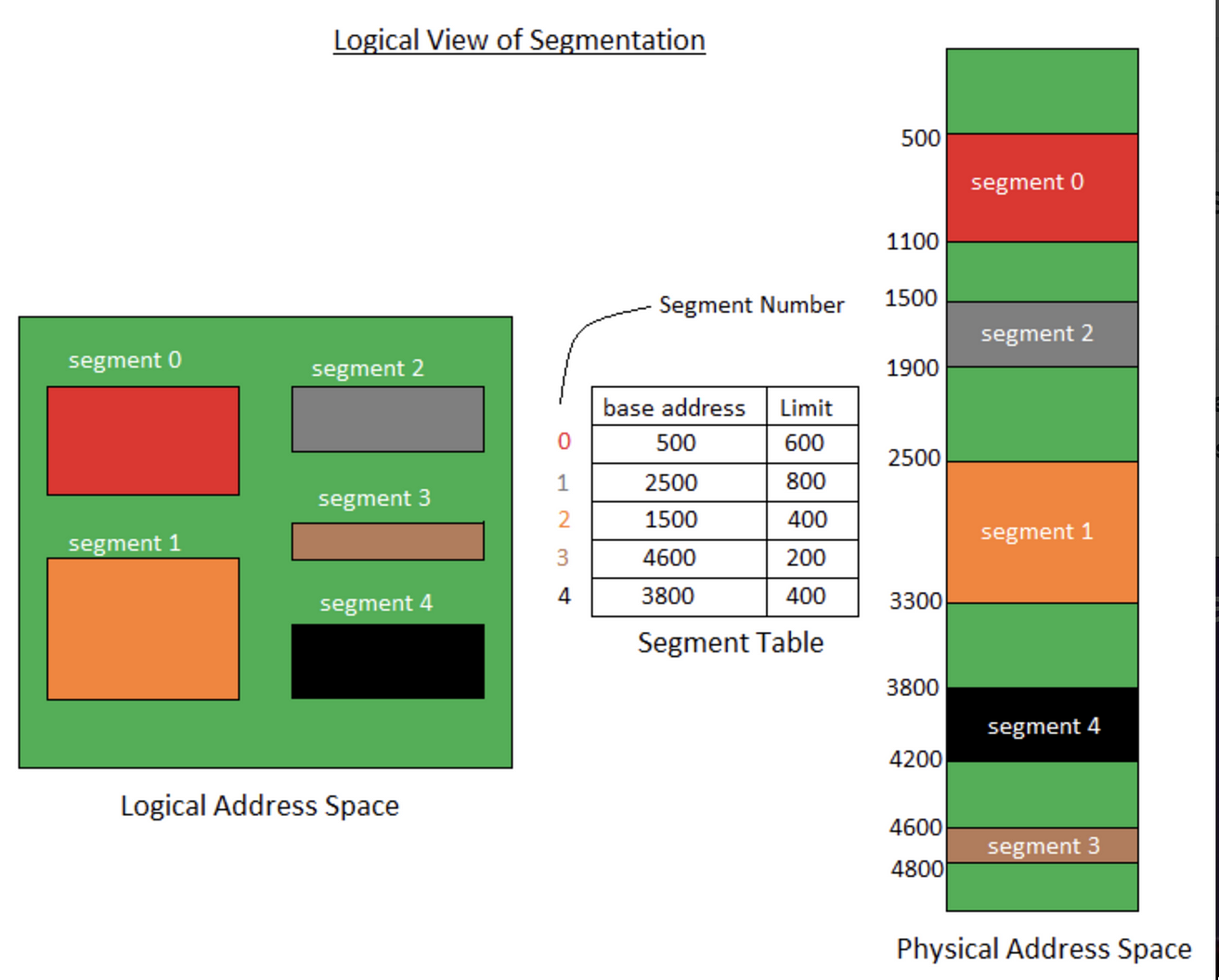 分段机制下的地址翻译过程
分段机制下的地址翻译过程
段表中还存有诸如段长(可用于检查虚拟地址是否超出合法范围)、段类型(该段的类型,例如代码段、数据段等)等信息。
通过段号一定要找到对应的段表项吗?得到最终的物理地址后对应的物理内存一定存在吗?
不一定。段表项可能并不存在:
- 段表项被删除:软件错误、软件恶意行为等情况可能会导致段表项被删除。
- 段表项还未创建:如果系统内存不足或者无法分配到连续的物理内存块就会导致段表项无法被创建。
减少碎片
内存紧缩(compact):内存存储不下程序,会把暂时休息的第一个进程方法放入磁盘,过段时间移除进程b放入进程a,这样会让内存中出现空洞,所以要将进程整体往下移动。必须将运行中的进程中断,将所有分散的内存碎片压到连续的部分中,然后再将新的基址和界限移动到寄存器中,进程按照新的上下文继续执行。缺点是代价太高,性能不好
改善空闲列表(free list):分配内存的时候采取一定的策略,尽量减轻内存碎片的现象,但也无法根除碎片的出现
空闲空间的管理
维护一个空闲空间的列表(freelist)
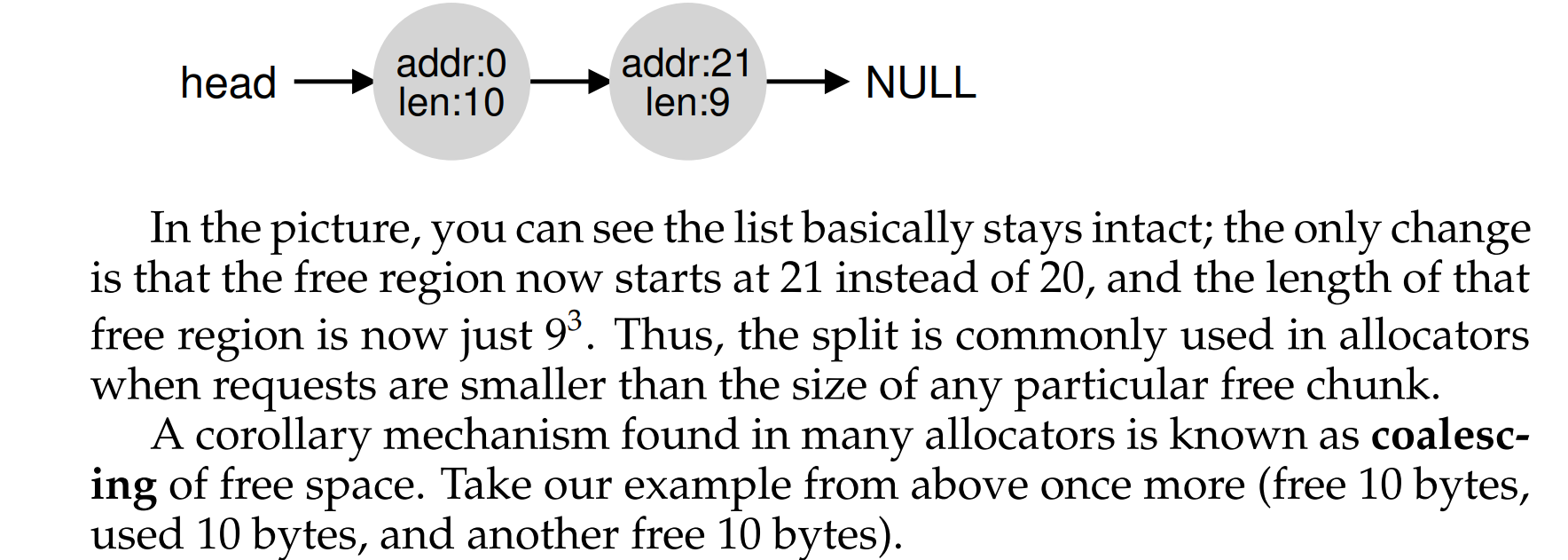
机制:分割与合并
splitting

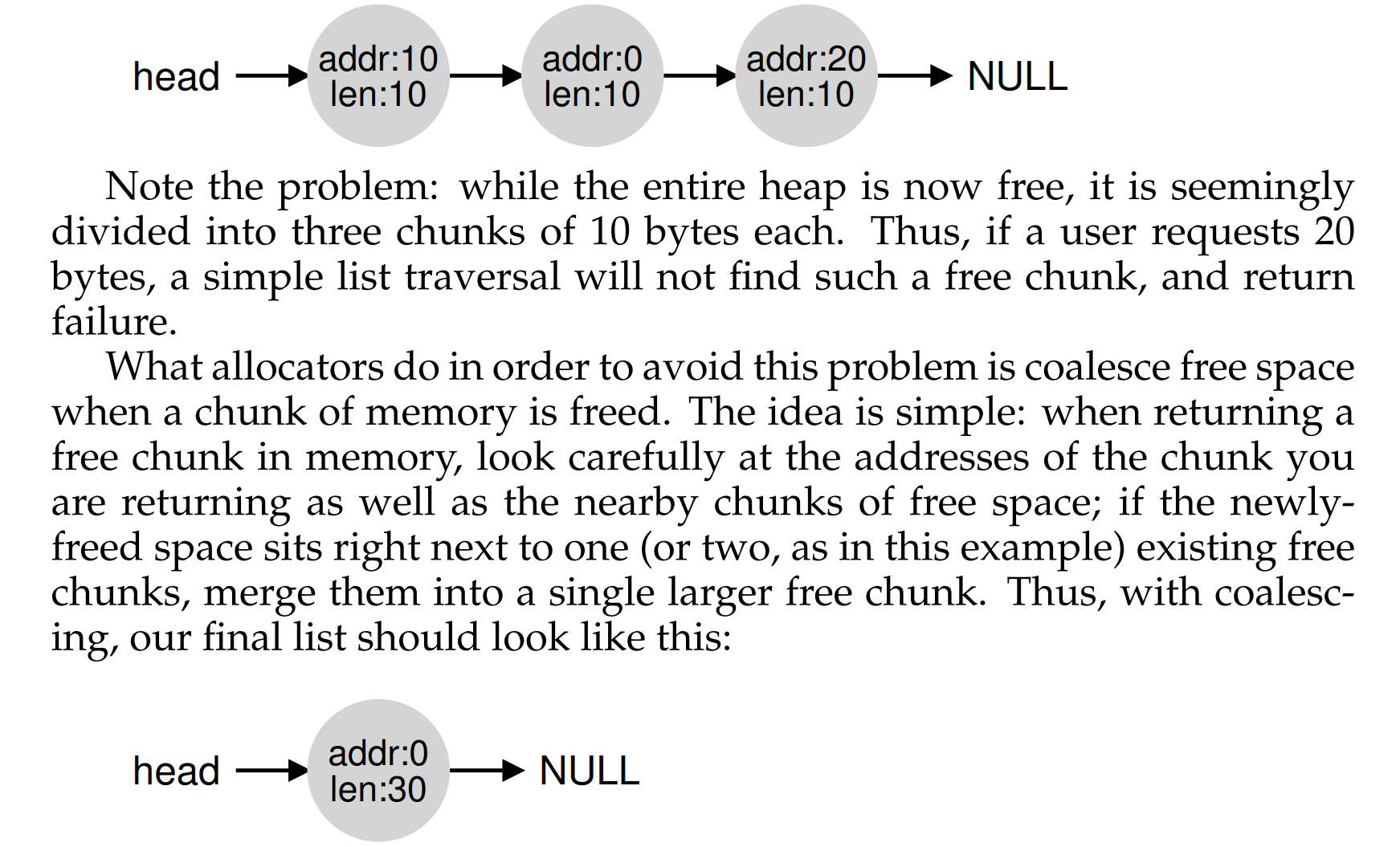
coalescing
内存 API
malloc
void* malloc(int size) 申请大小为size的连续字节空间(虚拟意义上的连续),返回一个指向这个空间首部的指针
除了用户申请的空间之外,在malloc时还会申请一个头部Header,size用来表示申请空间的大小,magic魔数用来验证完整性延迟分配:提供内存利用率的三种机制 - 牛犁heart - 博客园
- malloc只是分配了虚拟内存,程序真正访问才会触发页错误给这些虚拟页分配物理页框(demand paging)
- 在标准 C 库中,提供了 malloc / free 函数分配释放内存,这两个函数底层是由 brk,mmap,munmap 这些系统调用实现的。 (详见Linux虚拟内存系统) 不过跟直接调用还是有区别的。
free
void free(void* ptr) 将指针ptr所指向的已分配空间释放掉,依据的信息是分配内存的Header部分 ,因此malloc的size并不是真正的大小,还要分配头部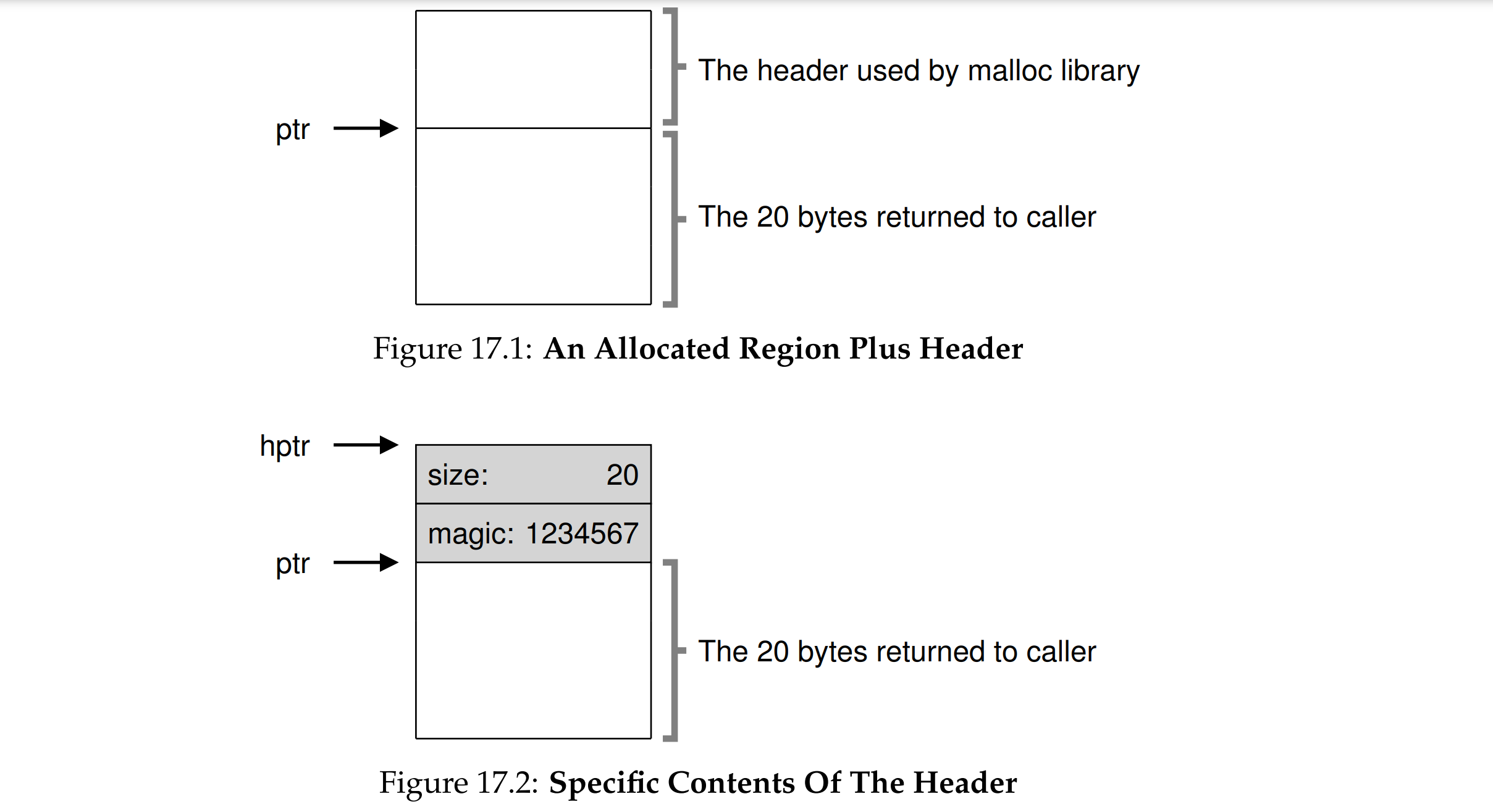
嵌入 free list 到内存中
free list 本身也需要存储在内存中,这里我们知道:空闲的块作为空闲节点有额外的简单数据结构(int size, node* next),已分配的块同样也有简单的数据结构(int size, int magic),因此堆实际上是一个空闲内存和已分配的内存的混合。
- 未分配空间

- 连续分配了3个100字节的空间
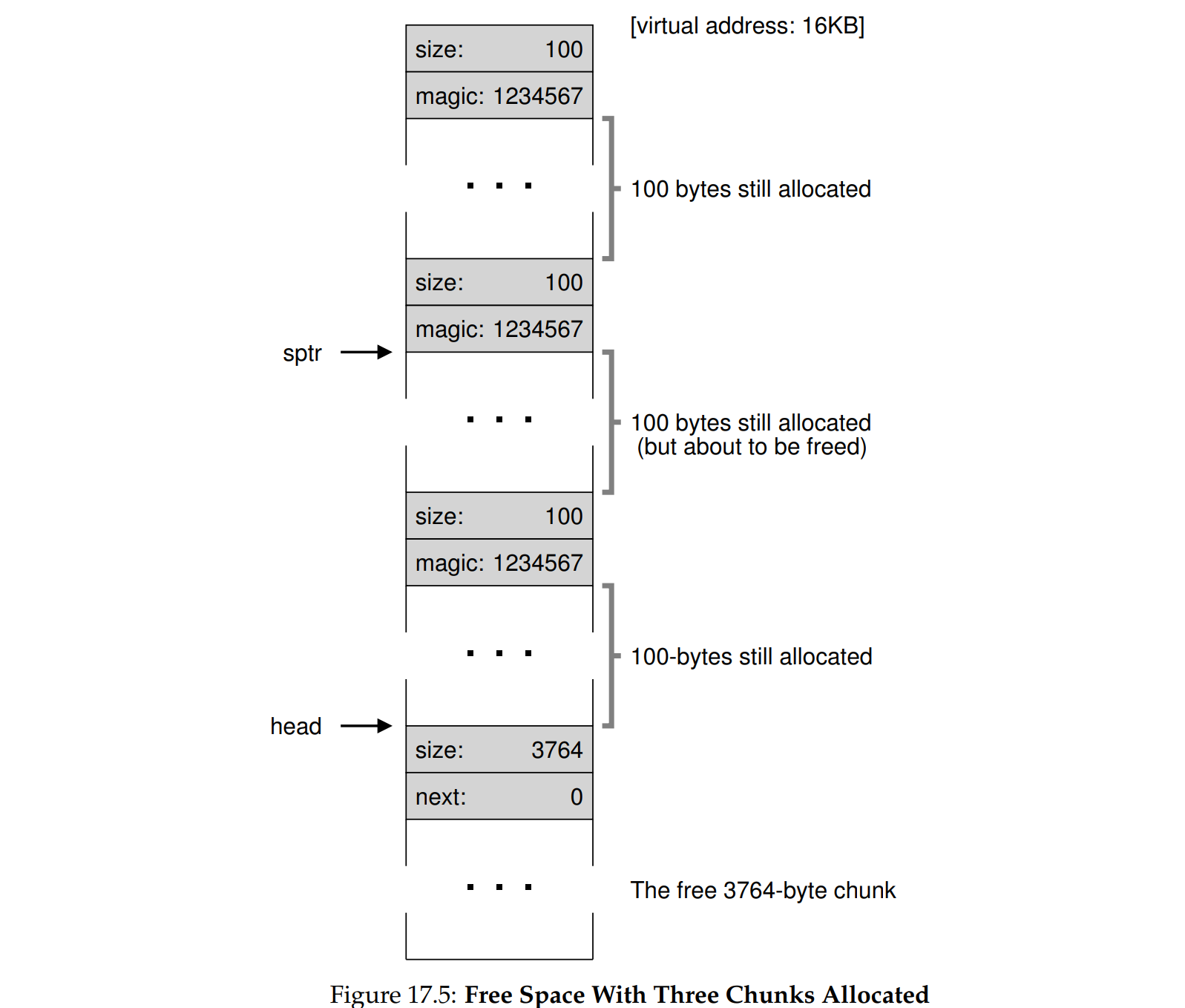
- 中间出现了空隙,可以看到空闲列表的头节点(head)发生了变化,两个空闲的块通过链表连接起来
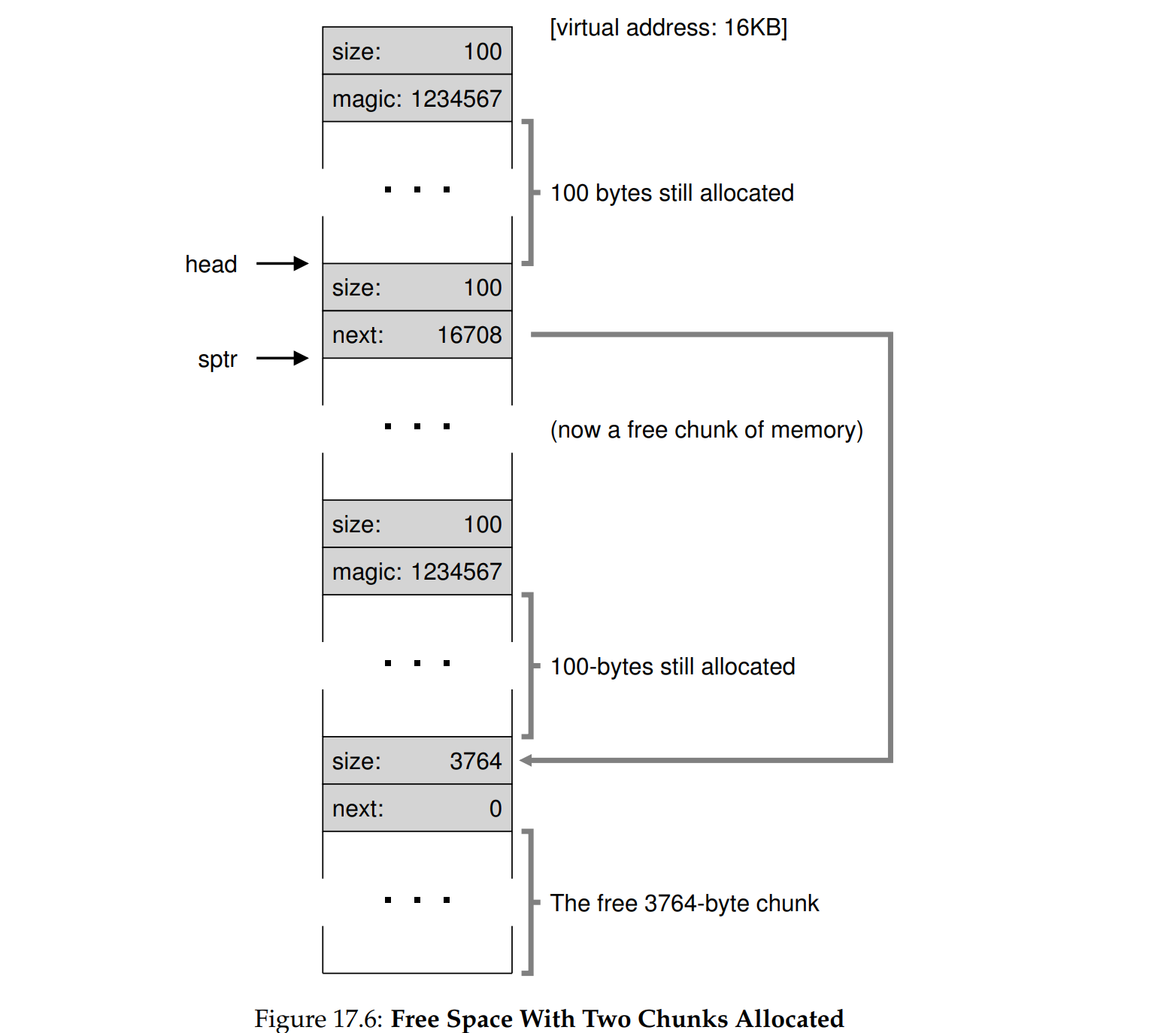
- 全部释放之后,出现了4个空闲的块,但是还没有合并(merge)
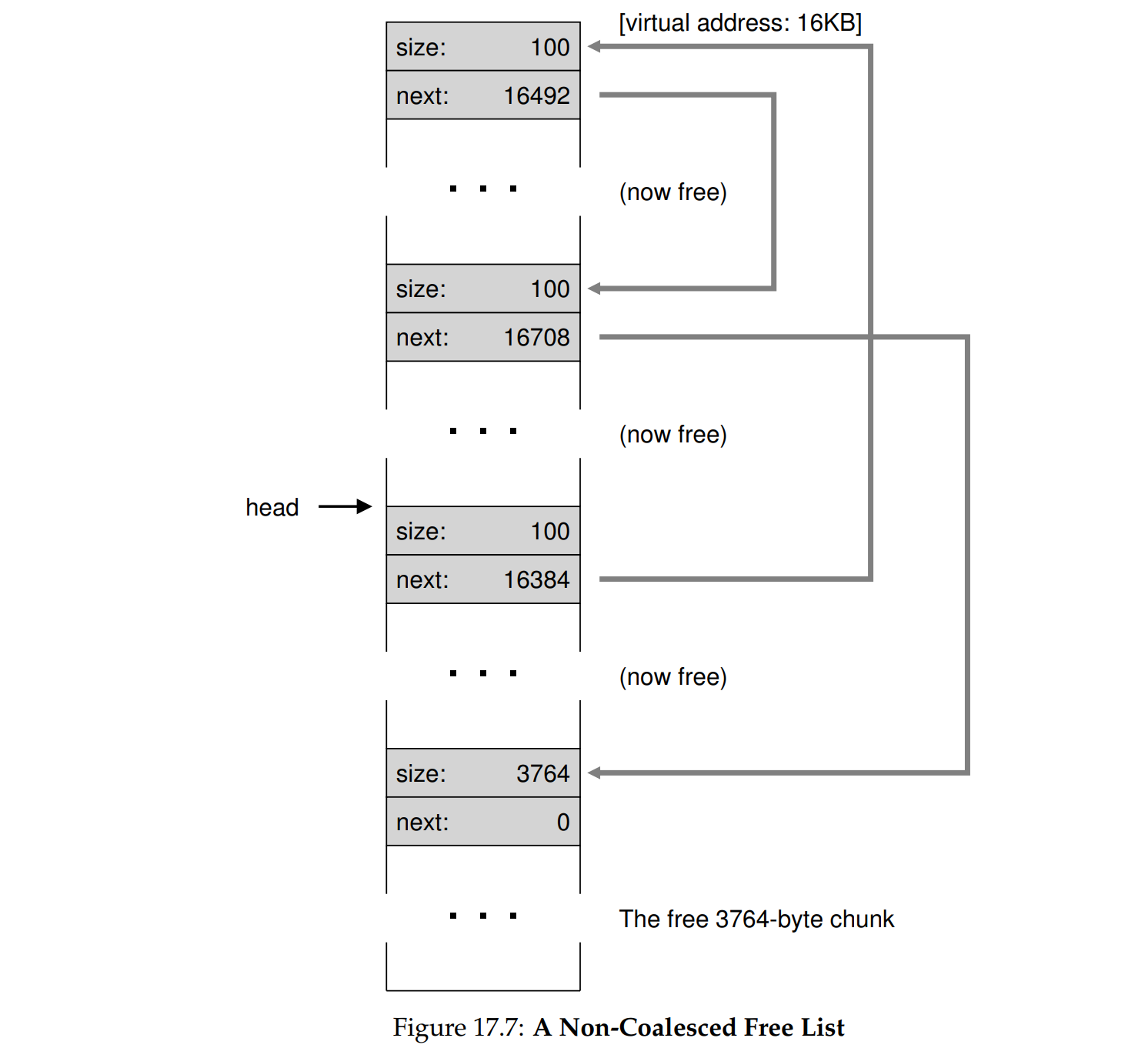
策略:连续内存分配
基本策略:空闲链表
- Best Fit:遍历整个列表,找到跟分配块大小最接近的空闲块,尽量减少碎片大小。细小碎片多,开销大。
- Worst Fit:遍历整个列表,找到跟分配块大小差距最大的,分割之后将剩余块加入空闲列表。碎片过量,开销大。
- First Fit:第一次找到足够大的块就直接分配。会让开头部分有许多小的碎片,可以通过按地址排序,便于合并操作。
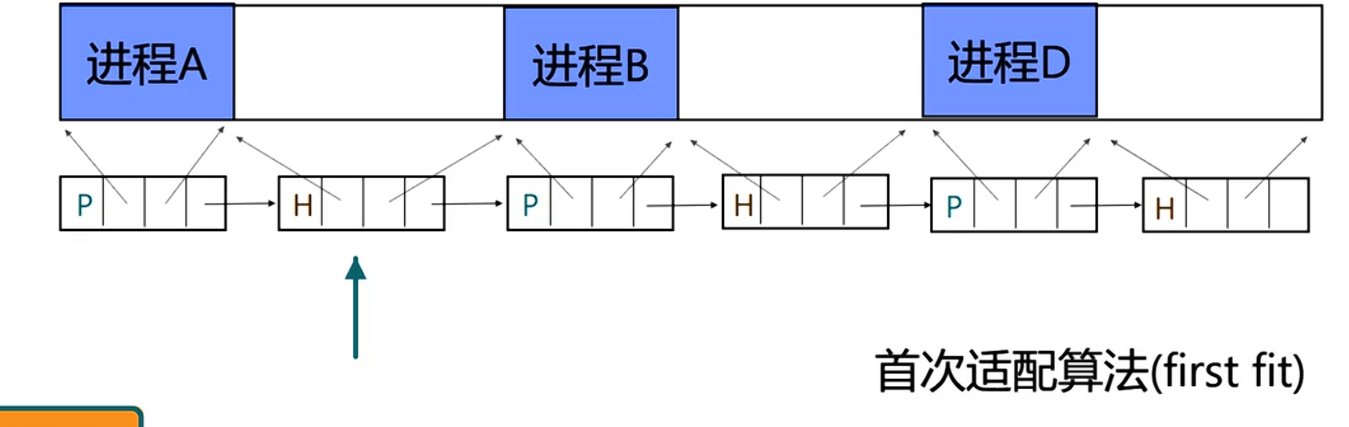
- Next Fit:每次查找都从上次结束的地方开始,剩下逻辑依然是首次匹配,可以减少开头部分过多的小碎片,将其分散到其他地方。
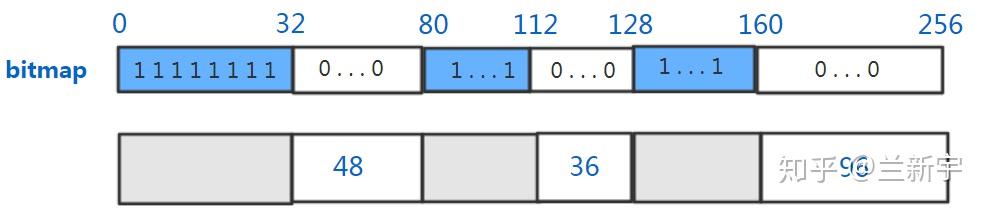
位图:
内存池(memory pool)
如果能将一大块内存分成多个小内存(称为内存池),不同的内存池又按照不同的「尺寸」分成大小相同的内存块(比如分别按照32, 64, 128……字节),同一内存池中的空闲内存块按照free list的方式连接。每次分配的时候,选择和申请的的内存在「尺寸」上最接近的内存池,比如申请60字节的内存,就直接从单个内存块大小为64字节的内存池的free list上分配。
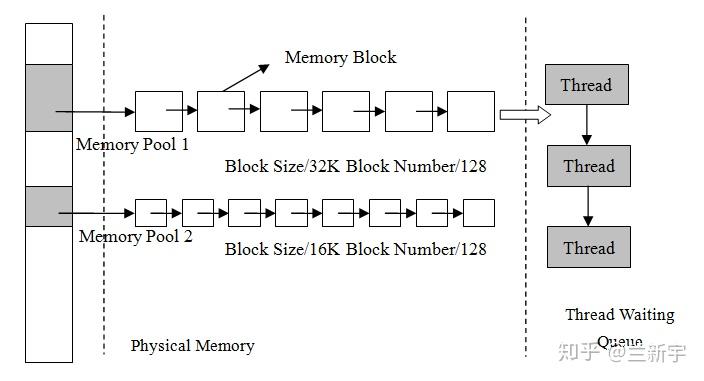
需要结合系统实际的内存分配需求,对内存池的大小进行合理的划分。比如一个系统常用的是256字节以下的内存申请,那设置过多的256字节以上的内存池,就会造成内存资源的闲置和浪费。
其他策略
Linux 发展出两种基于内存池的分配策略,详见 Linux 实现
- Buddy system: 将内存池划分为以2^n^为大小的类型,同一内存池中的空闲块大小相同,如果空闲块是相邻的则合并,将合并后的块加入更大的内存池中
- SLAB: 伙伴系统是按页分配的,但内核经常会申请一些特定大小的内存,往往不到一页,如果仍然使用伙伴系统将造成很多内部碎片,SLAB为它们分配了内核对象缓存,专门的连续内存区,依然使用内存池的思路,但是池子变得比以前更小。
分页(paging)
虚拟——物理页号转换
页帧、页帧号、虚拟页号
分页机制:将虚拟的地址替换成物理地址,用大小相等的页代替大小不等的段。原来一个进程是代码段和数据段不等,分配的内存空间也不一样,现在将段继续拆分成大小相等的页表项,这样从根本上解决了外部碎片的问题。
页帧(Page Frame):物理内存中存放数据的最小单位。当一个虚拟页被映射到物理页时,数据会存放在对应的页帧中。假设一个进程的虚拟地址空间中有一个虚拟页,虚拟地址 0x1000 对应的虚拟页页号是 0x1,偏移量为0。此时,操作系统通过页表将虚拟页 0x1 映射到物理内存中的一个页帧 0x3,即物理地址为 0x3000。那么,当该进程访问虚拟地址 0x1000 时,CPU 会通过页表将其转换为物理地址 0x3000,并在页帧 0x3 中访问数据。页帧大小固定为PageSize
虚拟地址(Virtual Address)= 虚拟页号(VPN, Virtual Page Number) + 偏移量(Offset)
页表项(Page Table Entry)= 物理页号(PFN, Page Frame Number)+ 保留的功能位
页表的物理地址:加载到页表基址寄存器(PTBR, Page Table Base Register),一个页表项(PTE)分为物理页号(PFN),有效位valid,读写权限位protection,内核模式位,脏位dirty,引用reference,存在位present等功能位。
从虚拟地址访存基本步骤
VirtualAddress = VPN + OffsetPTE Address(Physical) = VPN * PageSize + PTBRPTE保存着PFN以及其他功能位Physical Address = PFN * PageSize + Offset实际上VPN PFN Offset都是通过和MASK(作用和子网掩码相同)相与,然后PFN移位后和Offset相或。
1 | // Extract the VPN from the virtual address |
一些功能位
- Protection bit:权限位,保护位 r w x,如果违反了越权访问,就要陷入OS
- Valid bit:有效位,虚拟地址空间并不是全部都要分配,如果访问了还没有分配的(valid bit = 0)就是非法访问,将会抛出异常陷入OS
- Dirty bit:脏位,页面带入内存之后是否被修改过
- Present bit:存在位,表示内存页在内存中还是已经被换出
- Reference bit:参考位,追踪页面是否被访问
页表开销
- 内存开销:每个页表项需要4B,页大小(PageSize)是4KB,要虚拟出一个4GB的空间,就要有4GB/4KB * 4B =4MB 空间来存储。对每个进程操作系统都要有4MB的空间用于页表的储存,开销很大。页表是按照页号进行索引查找的,这就需要本身是一段连续的内存空间,页表就是一个大的数组,实际上页表在物理上也连续。
- 性能开销:对于每个内存引用,都要额外引入一次内存引用,效率不高,每一次访存都多了一步访问页表,性能显著下降
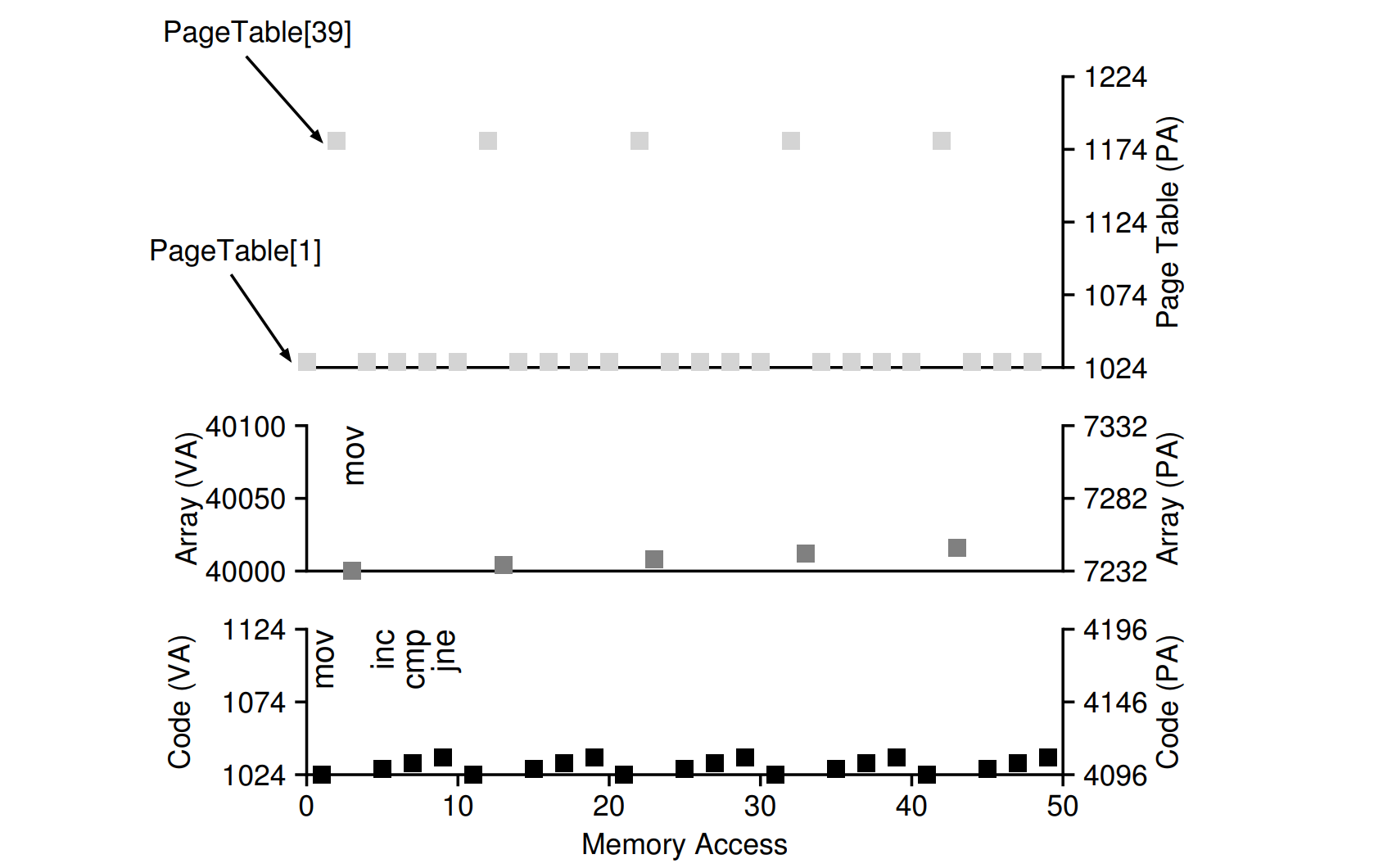
页表总结
Pros:
- No external fragments
- Flexible, good support for sparse address space
Cons:
- Physical Space costs (Page table)
- Speed Costs (extra memory access)
快表 TLB
如果想要快速的缓存,他就必须小,因为光速和其他物理限制会起作用
TLB:因为有二八定律,所以MMU要记下经常使用的虚拟页号,将VPN与PFN的映射关系存在 TLB 快表中(Translation Lookaside Buffer aka. Address Translation Cache)
硬件实现 TLB 控制流
CISC 将tlb miss逻辑全权交给硬件负责,拿着虚拟页号 VPN 去 TLB 中查询
- TLB hit:直接访存(
AccessMemory) - TLB miss:查页表,查到PFN后写入TLB(
TLB_Insert),重新执行TLB查询操作(RetryInstruction)

硬件实现:需要PTBR(x86架构中为CR3寄存器),页表的确切格式是写死在硬件里的(x86中为多级页表)
软件实现 TLB 控制流
RISC 将tlb miss看作一个异常,陷入OS,执行对应的处理程序

软件实现的好处:可以随时更改,可扩展性强,页表的数据结构由操作系统自行决定,
注意的问题:
- TLBmissHandler和一般的trap不同,一般return from trap 会从陷入后的地方继续执行,而TLBmiss则会从重试陷入之前的程序,因此保存的上下文很重要,尤其是程序计数器
- TLBmissHandler也是代码,要访存,须谨防无限递归tlb miss的问题,可以专门把一块TLB的空间划给TLBmiss处理程序使用;或者也可以不使用虚拟内存,直接把代码物理地址告诉硬件(unmapped,陷阱表)
TLB 内容
概览
VPN | PFN | other bits
是一个全相联(fully-associative)的cache结构,硬件会并行地查找这些项,
other bits:
protection:访问权限
valid:表示TLB是否记录着一个有效的
VPN->PFN映射,PTE的有效位为0表示这是一个并未被应用申请过的非法地址dirty:脏位
asid:access space id,地址空间id,用来标识不同进程的TLB条目Linux进程管理+内存管理:进程切换的TLB处理(ASID-address space ID、PCID-process context ID)_进程的asid-CSDN博客
上下文切换
TLB集成在CPU内部的MMU,因此一定会有上下文切换的问题,VPN一样的条目会导致数据错误
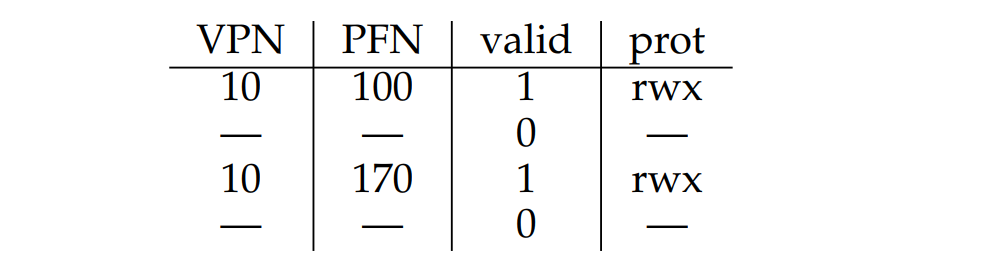
解决方案:
- 上下文切换的时候将所有 TLB 条目的有效位置0(flush),下一个进程可以随便覆盖
- 使用ASID(类似于pid)记录这个TLB条目属于哪个进程

PFN一样的条目:可能是共享代码页,这样可以减少额外分配物理页

例:MIPS TLB Entry

0-18 VPN 19 Global 进程间共享 24-31 ASID 进程空间
刷新、替换
TLB flush
TLB之flush操作[一] - 知乎 TLB之flush操作[二] - 知乎 Linux内存管理:TLB flush操作-CSDN博客
Linux进程管理+内存管理:进程切换的TLB处理(ASID-address space ID、PCID-process context ID)_进程的asid-CSDN博客
在页表PTE的内容出现变化时,比如page fault时页面被换出,munmap()时映射被解除,就需要invalidate对应的TLB entry,有时这个操作也被称为flush(以下的讨论将统一称为flush)。
当系统中各个cpu的TLB中的asid合起来不大于256个的时候,系统正常运行,一旦超过256的上限后,我们将全部TLB flush掉,并重新分配ASID,每达到256上限,都需要flush tlb并重新分配HW ASID。
在多核系统中,虽然每个核心的MMU是独立的,但它们在访问共享内存时需要进行协调。共享内存区域允许多个核心同时访问相同的物理内存,这对于核心间的通信或共享数据非常关键。MMU可以通过为不同的内存区域设置权限和属性,确保多个核心在访问这些共享区域时不会出现数据冲突或不一致的情况。这在多线程或多进程系统中,尤其在同步和内存一致性方面,显得尤为重要。
缓存更新策略
优化分页
扩大页面大小(Bigger Pages)
Linux
对TLB更加友好,考虑到空间局部性,同一页能够访问更多数据,也就不用频繁地查页表了
增大页面大小,VPN
max变小,每个虚拟页占空间4B,页表占用总空间减小;但应用程序申请的并不一定是会充满整个页,所以会出现内部碎片(internal fragment)
分段 + 分页(Hybrid Approach)
线性页表的局限
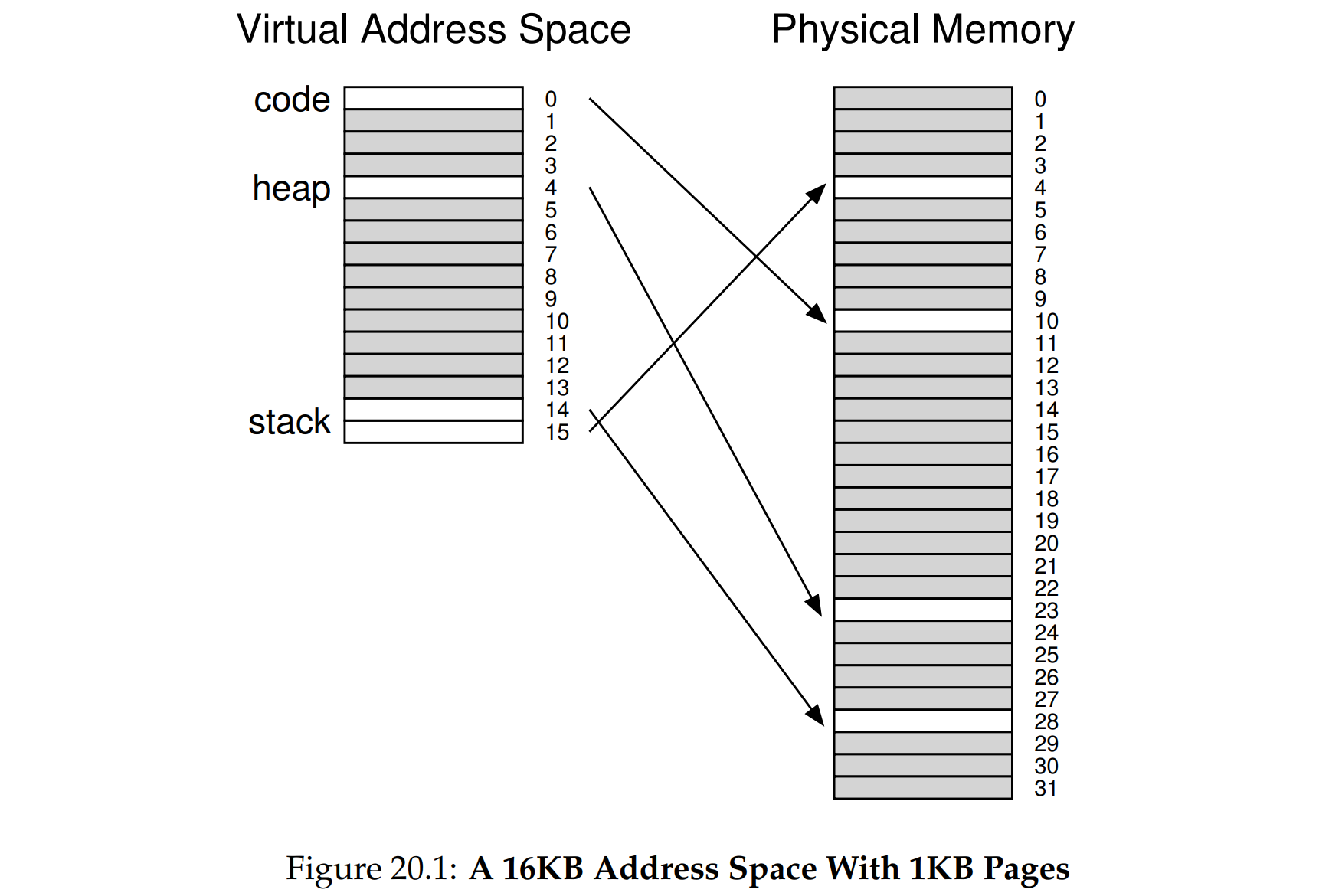

如图,虚拟空间是16KB,页面大小为1KB,因此页表共有16 entries,除去代码段,堆栈之间的空间是严重浪费的,就像分段会导致内部碎片一样,连续的线性页表也会导致内部碎片。
段页结合
VAX/VMS

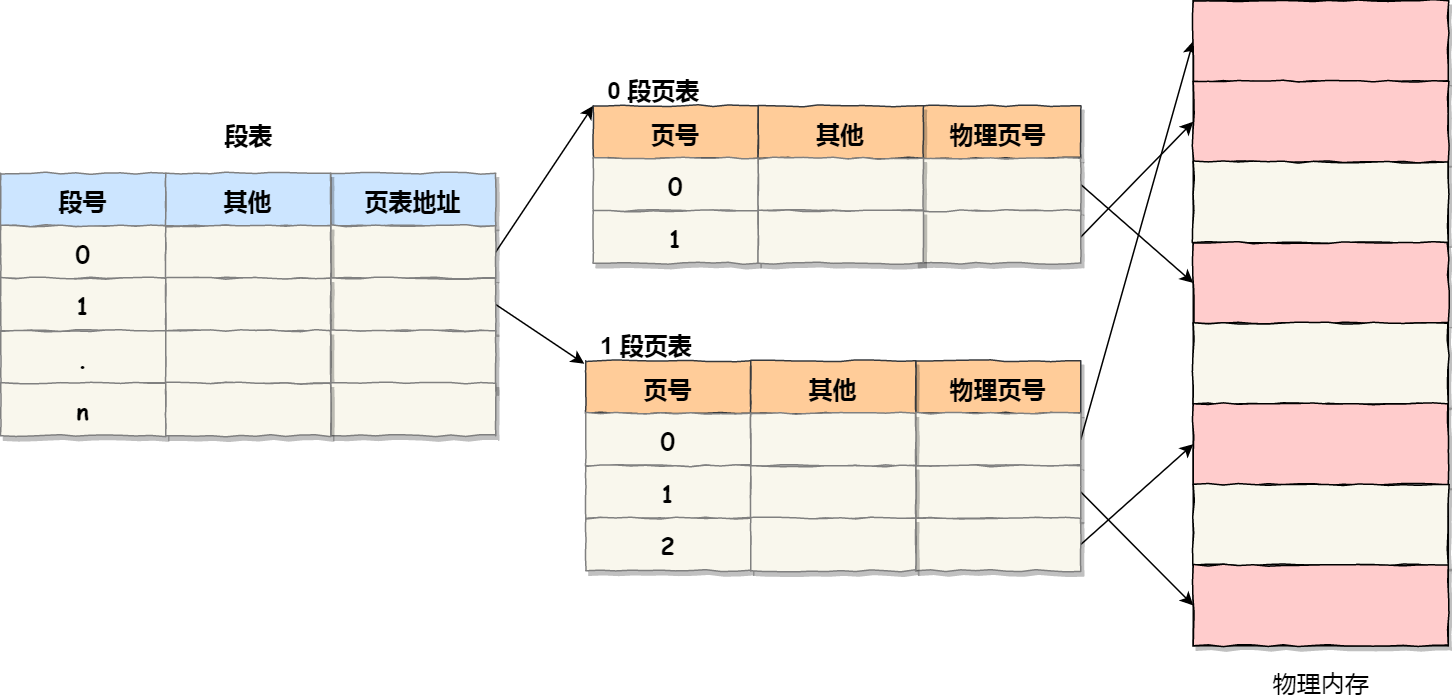
可以根据代码、堆、栈对页表进行分类,然后使用三个base-bound寄存器对,上下文切换时保存、恢复寄存器内容。更细粒度的分段可以使用段表。base存储段在物理内存的位置,bound表示段大小。
1 | SN = (VirtualAddress & SEG_MASK) >> SN_SHIFT |
缺陷
- 与分段的缺陷一样,只不过是将真正的数据部分换成了页表
- 不灵活,假设地址空间有一定的使用模式,分段则需要为整个堆段预留连续空间,即使中间部分未使用也无法释放。
- a large but sparsely-used heap 仍然可能导致大量的页表浪费
- 由于界限寄存器的存在,每个段有多少页是不确定的,因此每个段的页表大小也不确定,导致寻找足够的连续自由空间比较复杂。虽然节省内存但是有外部碎片问题
多级页表(Multi-level Page Tables)
x86 ARM Linux Windows
减小页表占用的空间,分散成多个页表,每张页表大小==相同==,并且刚好能填满一整个内存页,消灭了外部碎片
如果整页的PTE都是无效的(未分配),则完全不分配该页面的页表。
- PDE的有效位:此条目指向的页是否有页表?PTE的有效位:此条目是否是一个有效的PFN映射?
- 树形结构,不用的可以不分配页表空间。支持稀疏空间:不用的就不分配物理内存页
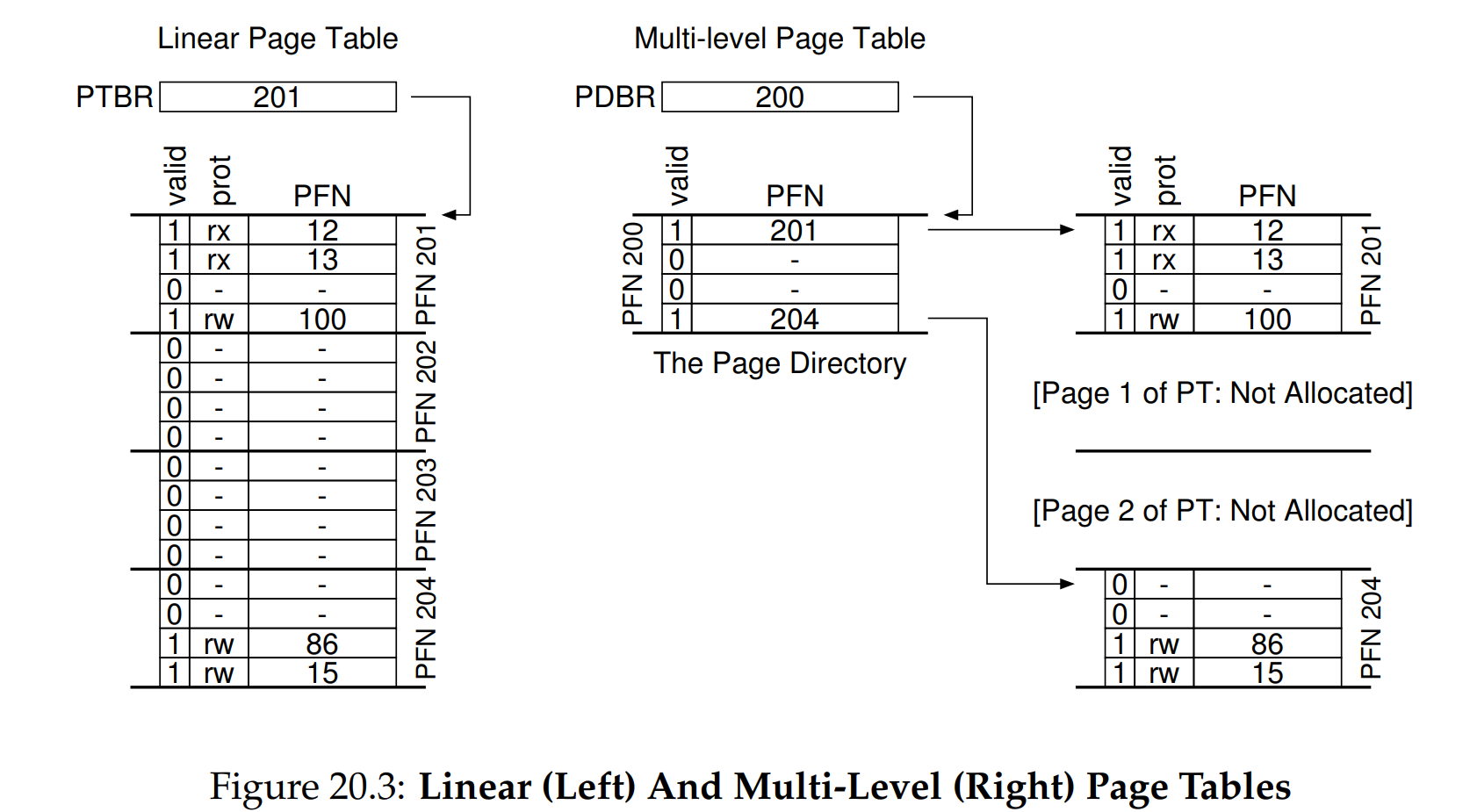
页表目录-页表-内存
CR3存的是页表目录(Page Directory)的基址,假设虚拟地址前4位是页表目录的编号,中间4位是页表(Page Table)编号,后12位为偏移。CR3找到了页表目录,根据前4位索引到PTE的PFN,根据中间4位找到页表中的PTE,PTE中存储着物理页的PFN。
基本思想:基址 + 偏移
VPN = PD_index | PT_index页目录项地址:
PD_Entry_Addr = Page_Dir_Base + PD_index * sizeof(PD_Entry_Addr)页表项地址:
PT_Entry_Addr = PD_Entry.PFN << SHIFT + PT_index * sizeof(PT_Entry_Addr)页面地址 :
Page_Entry_Addr = PT_Entry.PFN << SHIFT + Offset
以16位虚拟地址为例:
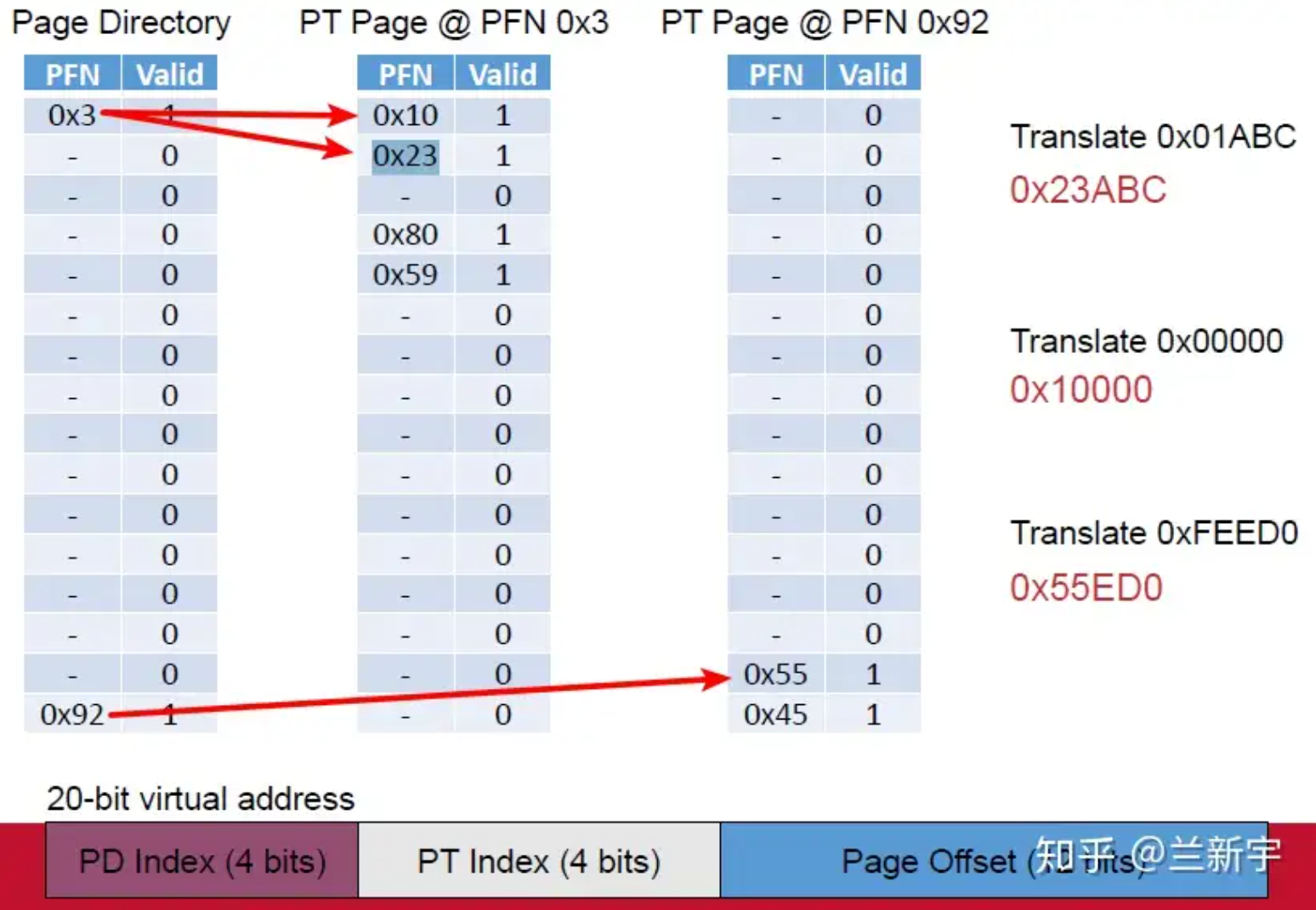
- 虚拟内存的要求:每一层级内部必须是连续的,因为分配物理内存空间只能一次性分配连续的一段
- 单级页表要想实现页表只能一次性分配256个连续的entries。
- 多级页表如果真的只有这3个地址所在的physical page被用到,那么只需要48 个entries就可以了
在32位系统中,进程的虚拟地址空间为4GB,但某个进程实际使用的页只占其中的一小部分,其分布是稀疏的,因此非常适合使用多级页表这种稀疏的级联数组(radix tree)来表示。
fill the pages
例:30位虚拟地址
目标:每张表填满一整个内存页 Page Size = 2^7^ * 4 B = 512 B,二级页表不能刚好占满一页
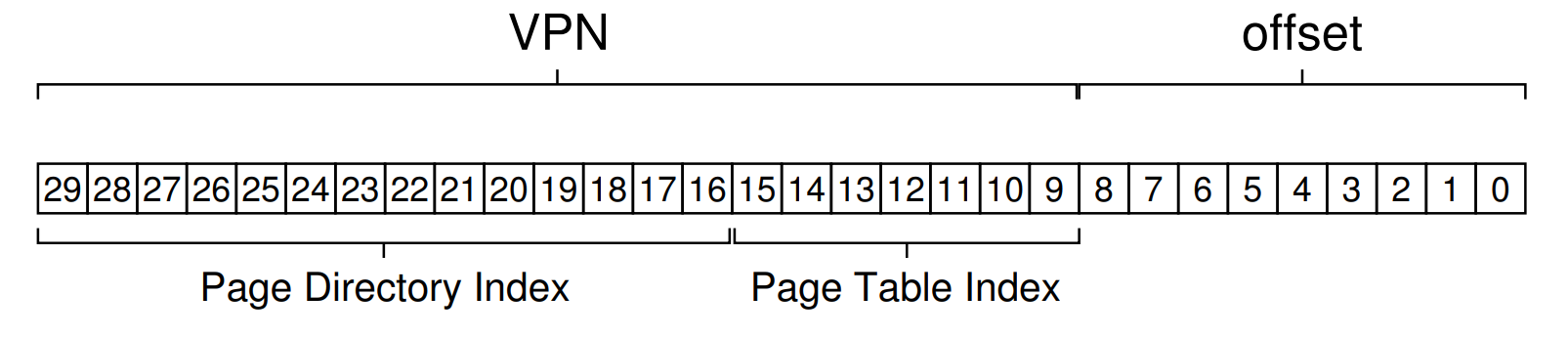
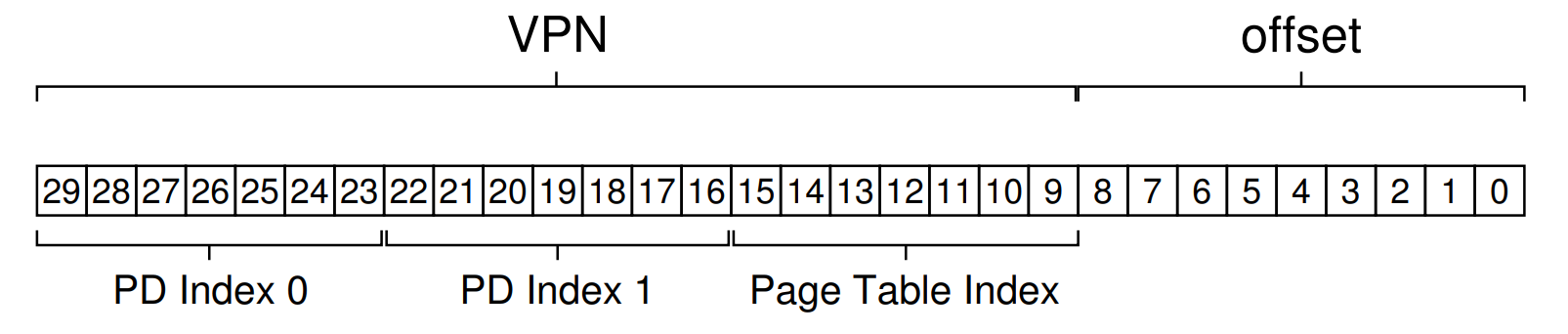
实际的32位和64位页表
在32位处理器中,采用4KB的page大小,则虚拟地址中低12位为offest,剩下高20位给页表,分成两级,每个级别占10个bit(10+10)。为什么32位系统的页表每级占10位,每个页的大小被设定为4KB而不是2KB或者8KB?
如果index为10位,则其可索引的范围是1024个entris,32位系统中,每级页表的每个entry的大小为4个字节,则每个页表的大小刚好是4KB。页表首地址也是要按页对齐的,如果占不满一个页,页中剩下的空间也就浪费了。80386引入分页机制的时候应该就考虑过把页设置为多大是最合适的,显然4KB的页大小对内存的利用是最充分的。1024 * 4 = 4 K
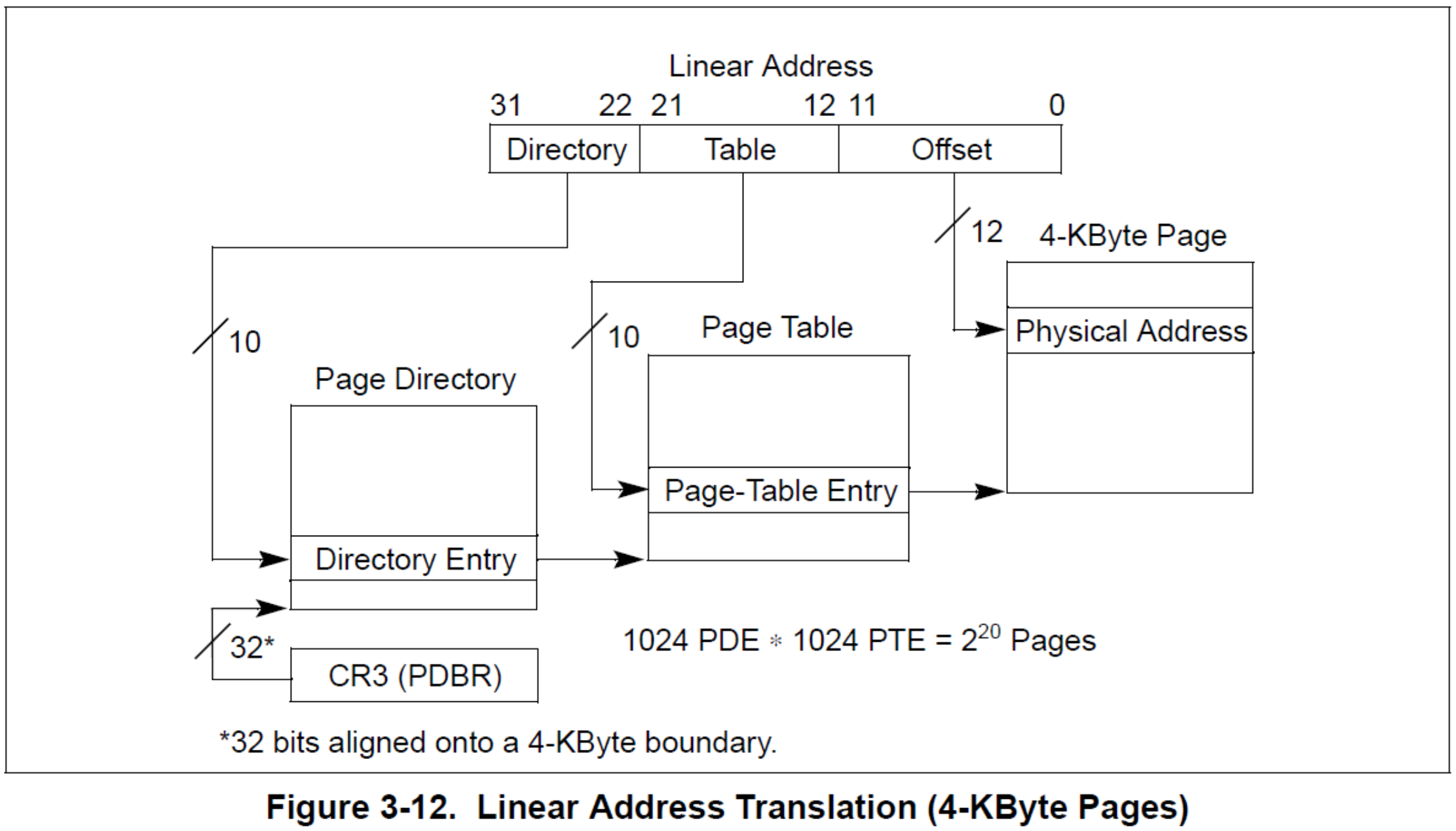
为什么64位系统的页表每级占9位呢?为了和硬件配合,基于i386编写的linux也采用4KB的页大小作为内存管理的基本单位。处理器进入64位时代后,其实可以不再使用4KB作为一个页帧的大小,但可能为了提供硬件的向前兼容性以及和操作系统的兼容性吧,大部分64位处理器依然使用4KB作为默认的页大小(ARMv8-A还支持16KB和64KB的页大小)。因为64位系统中,每级页表的每个entry的大小为8个字节,如果index为9位,则每个页表的大小也刚好是4KB。
512 * 8 = 4K

TLB 控制流

依然是先查TLB,TLB没有再查页表,先用PDBR加偏移 算出PDE的物理地址得到PTE所在的PFN,找到PTE之后根据PTE里面的PFN加偏移算出真实的物理地址。
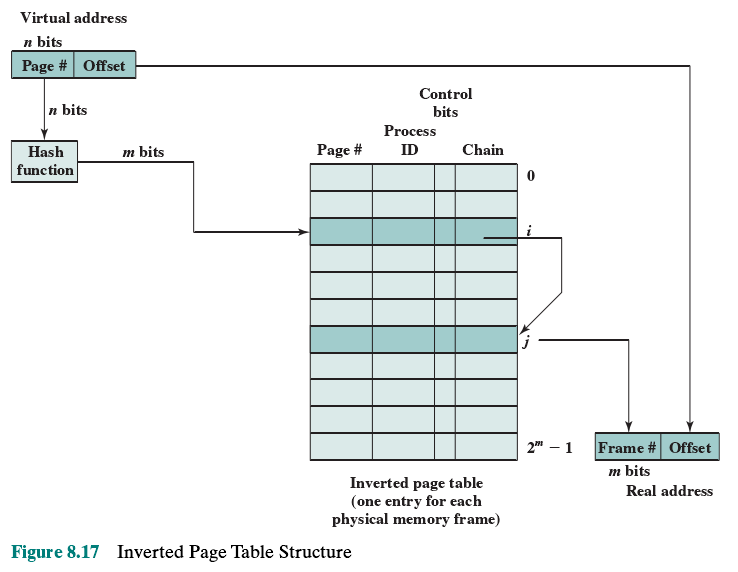
倒排页表(Inverted Page Table)
PowerPC
页表的映射反过来,PFN->VPN,除了VPN,还有使用此页的进程标识。通常使用Hash散列表来加快搜索。
交换到磁盘(Swap)
之前的页表都需要直接访问物理内存,页表本身并没有在程序的地址空间中,因此页表必须时时刻刻在物理内存中
VAX/VMS 把页表纳入内核的虚拟内存,允许在内存压力较大时将页表的一部分交换到磁盘。
超越物理内存
虚拟内存本质是虚的,实际数据可以存储在任何地方:寄存器(TLB)、物理内存(DRAM),甚至是磁盘(HDD SSD),因此虚拟内存大小跟物理内存大小并没有直接的关系,编程人员只需提供Virtual Address,由硬件和OS负责剩下的步骤,这就提升了程序的易用性,也提升了处理程序的多样性,考虑页表的数据结构,页表存储的位置等问题。
机制
交换空间
硬盘需要腾出一片专门的空间用来存放物理内存的内容,因此也需要进行编址。
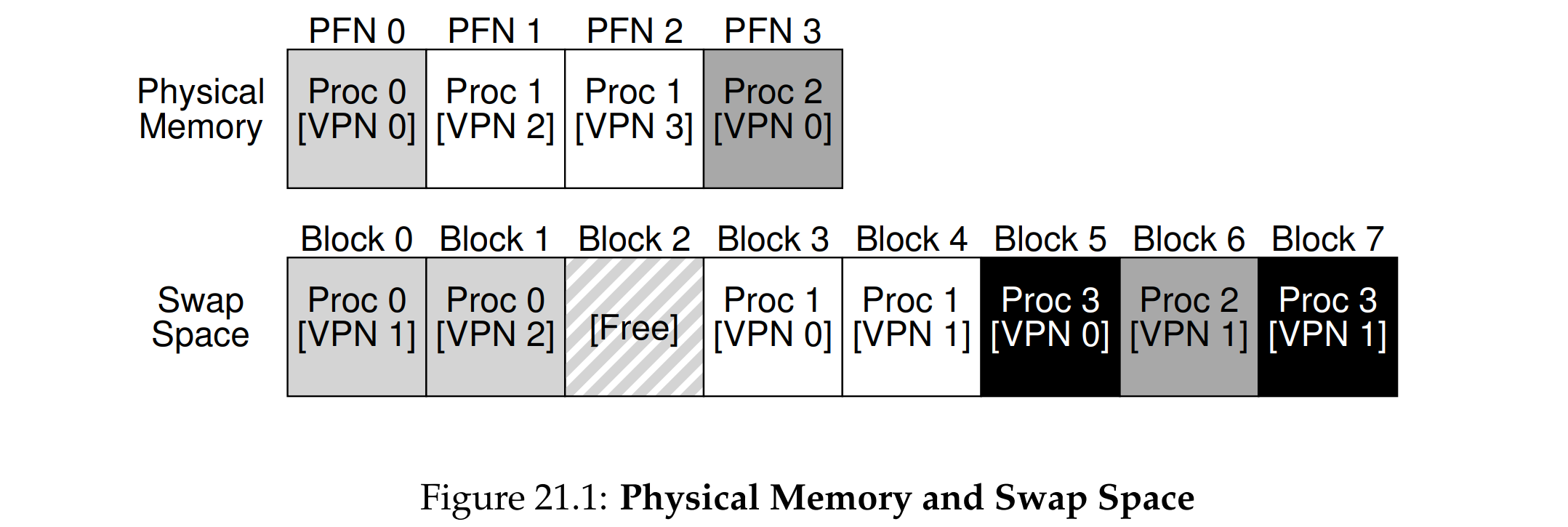
The code pages from this binary are initially found on disk, and when the program runs, they are loaded into memory (either all at once when the program starts execution, or, as in modern systems, one page at a time when needed). However, if the system needs to make room in physical memory for other needs, it can safely re-use the memory space for these code pages, knowing that it can later swap them in again from the on-disk binary in the file system.
虚拟内存提供了一种将磁盘和物理内存结合起来的方式:
- 代码页从磁盘加载到内存,过一段时间被换出,随后在需要的时候又被换入。
- 操作系统将整个物理内存看作“缓存”。
- 当内存不足时,系统会将不常用的内存页换出到磁盘(称为交换或分页)。
- 反之,如果需要使用换出的页面,系统会从磁盘重新加载到内存。
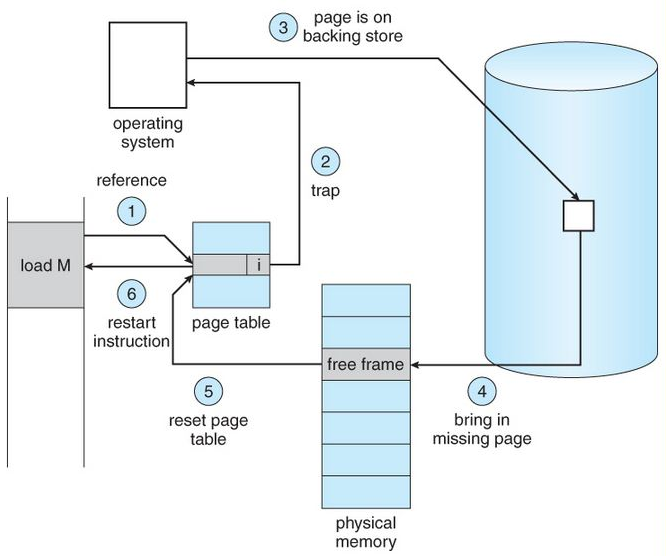
页错误(page fault)
存在位(presentation bit):用来标识一个页是否在物理内存中,如果不在,对此内存地址的访问就会触发page fault(实际上是page miss),陷入OS
Why OS Handles This?:TLB miss可以由硬件实现,但是Page Fault并不需要,因为Page Fault的处理性能瓶颈在硬盘:硬盘的读写速度比内存慢很多,硬件处理性能提升并不明显,并且硬件必须添加其他复杂的机制(写死在硬件里)
硬盘IO完成,更新PTE的PFN和存在位(也可以同时写入TLB中)然后Retry Instruction,IO过程中进程处于阻塞状态(blocked state),OS可以在这段时间内切换到其他进程以提高CPU利用率。
上述是硬性的页错误(虚拟内存地址不在物理内存中),还有一种软性页错误(虚拟内存地址在物理内存中),详见VAX/VMS
控制流:
- 错误的严重程度:
segmentation fault(valid bit = 0, 没有分配)protection fault(protect bits, 权限不够)page fault(present bit = 0, 不在内存里)


Page-Fault Handler by OS:
- 找空闲的物理内存,记录其PFN
- 找不到就使用淘汰策略,把现在的物理内存页换一部分到磁盘里,腾出空间
- 如果找到了就进行磁盘 I/O,系统调用会休眠,直到 I/O 完成。
- 换入完成就更新页表的存在位和PFN
访存机制总结
首先到 MMU 集成的 TLB 中查询,TLB 中存储的是虚拟地址页号(VPN)和物理地址页号(PFN)的映射关系,TLB 命中则直接访问物理页框;之后就是之前正常的 CPU 访存过程,与操作系统没有关系。TLB 未命中则去找 CPU 集成的 Table Walk Unit,TWU 中的 CR3 寄存器存储着当前页目录(Page Directory)的物理地址页号PFN,如果内存中的页表没有对应的内容,则触发页错误(Page Fault)去磁盘中寻找,页表命中则更新 TLB,重试指令。
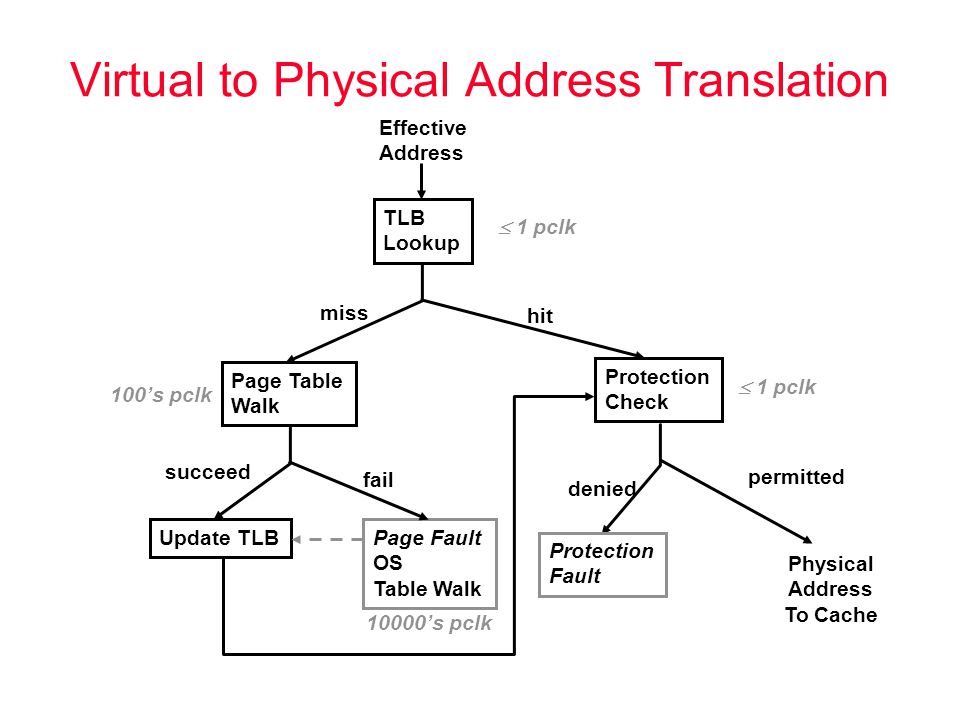
Swap 页面置换策略
$$
AMAT=(P_\text{Hit} \cdot T_\text{Mem})+(P_\text{Miss} \cdot T_\text{Disk})
$$
Tmem = 100ns(100个时钟周期) Tdisk = 10ms(10000个时钟周期) 对性能影响极大
基本策略
将物理内存看作虚拟内存的缓存,置换策略实际上就是缓存淘汰策略
局部性原理
缓存算法:LRU、LFU、随机替换等常见算法简介 - 个人文章 - SegmentFault 思否
我们能不能既享受 CPU Cache 的速度,又享受内存、硬盘巨大的容量和低廉的价格呢?前辈们已经探索出了答案,那就是,存储器中数据的局部性原理(Principle of Locality)
**时间局部性(temporal locality)**:如果一个数据被访问了,那么它在短时间内还会被再次访问。如 LRU 缓存机制,将频繁访问的数据保存在内存中。
**空间局部性(spatial locality)**:如果一个数据被访问了,那么和它相邻的数据也很快会被访问。如果数组的 CPU 预读功能。
OPT 最优:事先知道缓存的访问顺序(不可能)但是可以作为一个比较指标。
无状态策略:
FIFO:先进先出
Random:随机
LRU(Recently)基于上次被访问时间,LFU(Frequently)基于被访问的频率
基本有LRU FIFO Random,时钟算法(近似LRU),SecondChance(完善的FIFO),2Q(LRU+FIFO)
LFU:当使用 mmap() 访问文件缓存页面时,无法计数,实现较为复杂,不适合操作系统对虚拟内存的管理
性能比较
完全随机访问
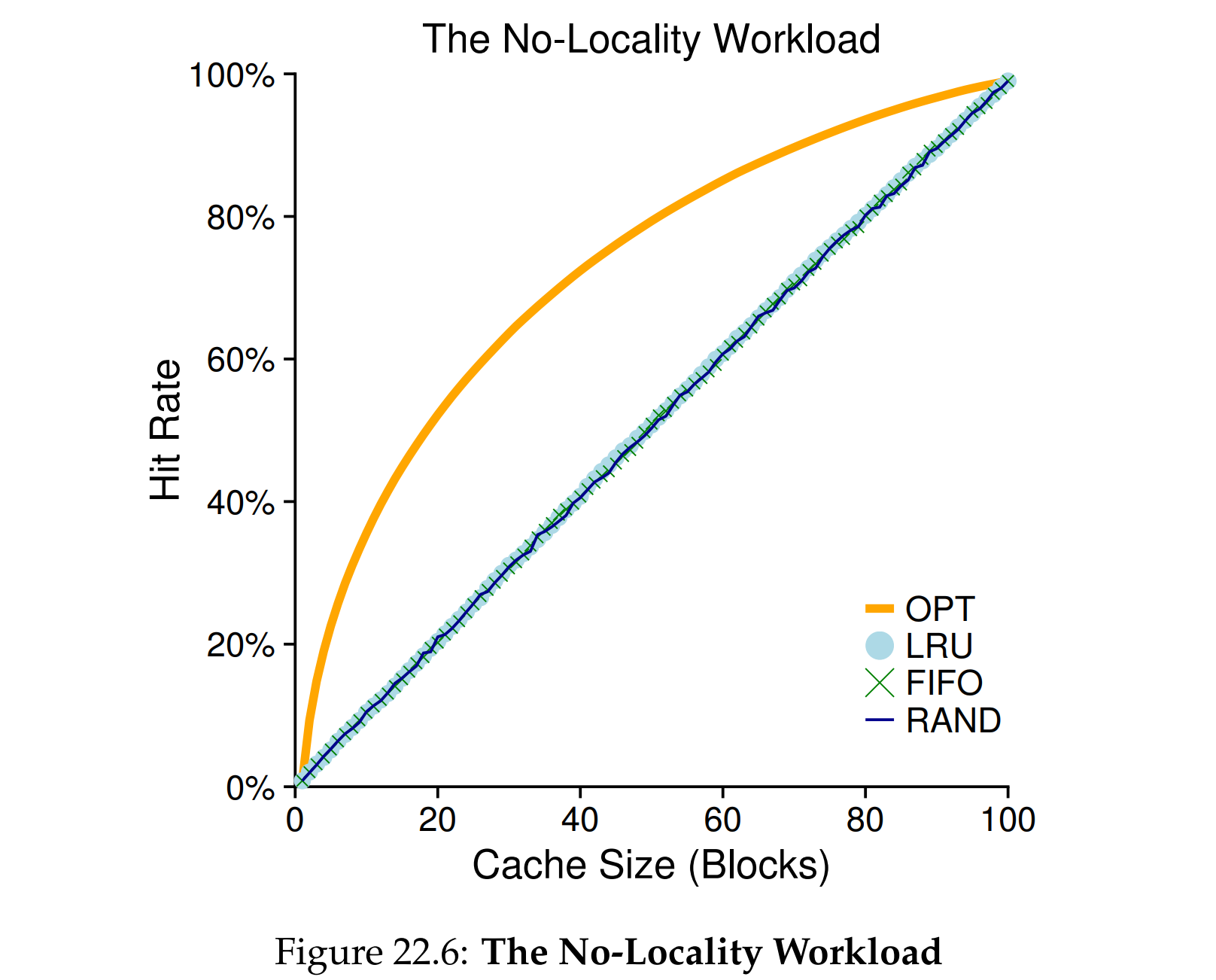
二八定律
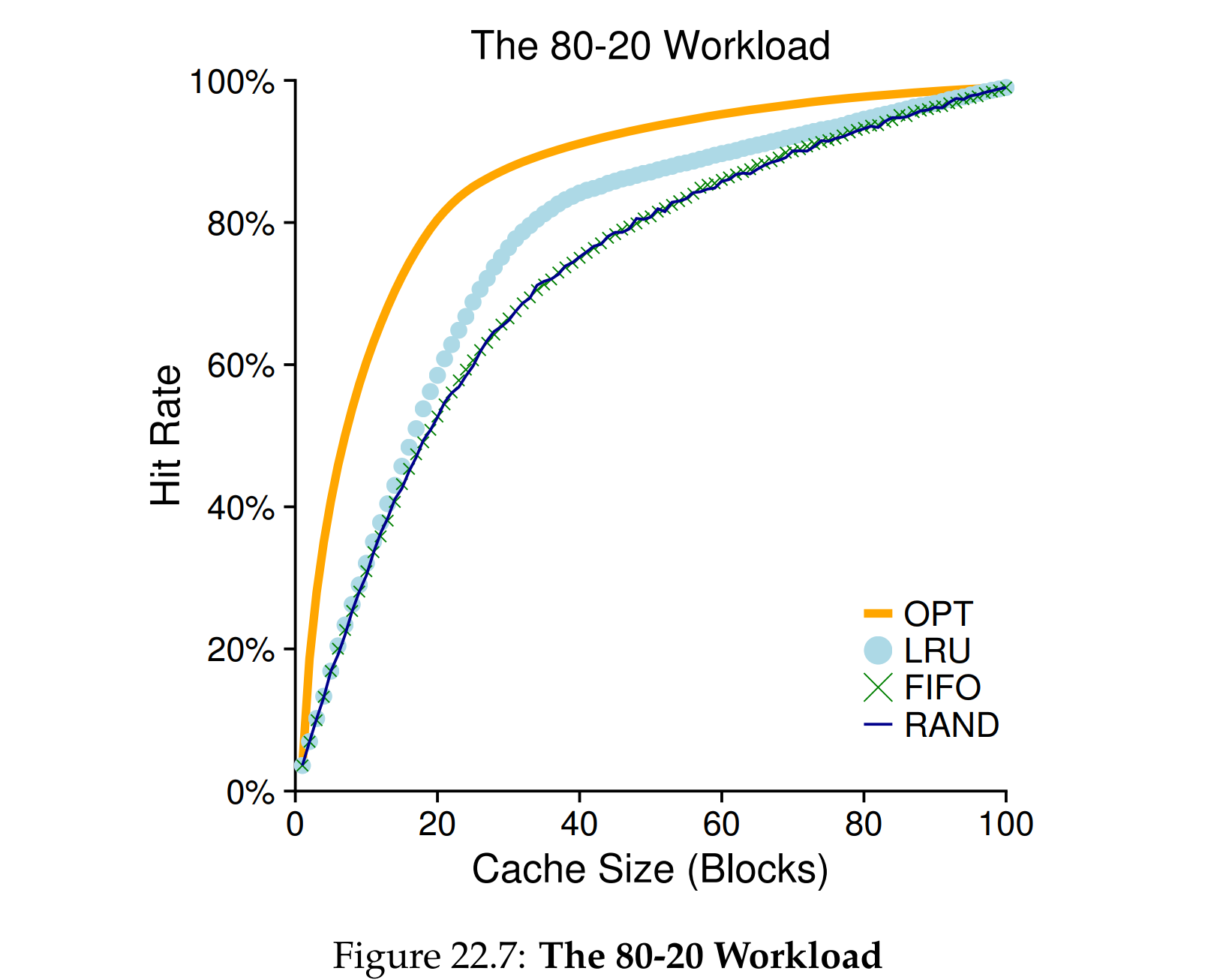
循环顺序访问
依次引用第0到第49页,LRU和FIFO,缓存在50以内,命中率为0
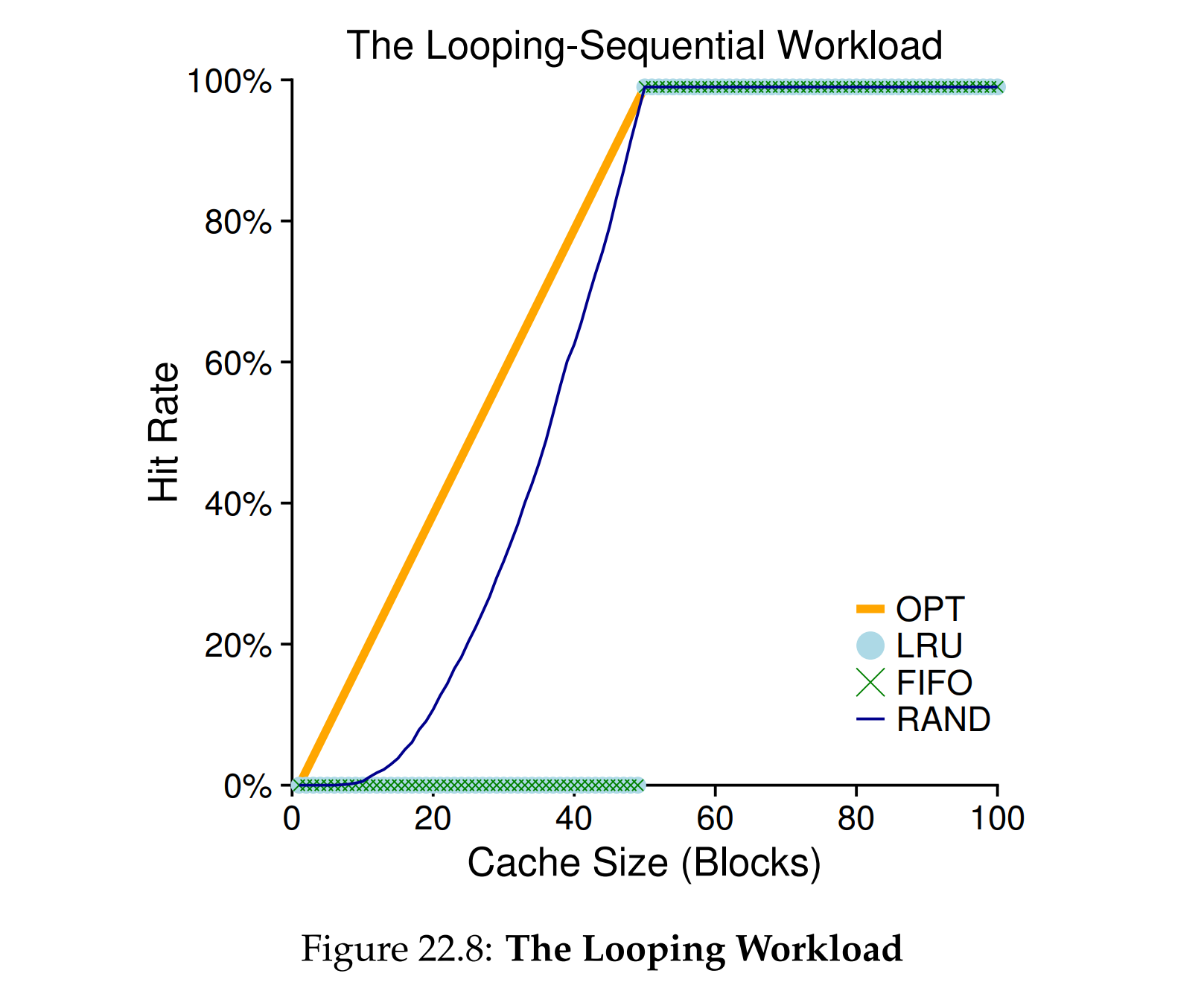
LRU,基于时间局部性的策略,预测性强:对于访问频繁的页表项保留效果好。
- 循环访问 n+1 页,但TLB只有n页容量,第一次TLB空的,全部 miss,由于空间限制,最后第n+1页会覆盖第1页。下一个循环开始第1页又 miss,第1页覆盖第2页内容,连锁的 miss
Random,实现简单,避免出现极端情况下LRU命中率极低的情况,不可预测:无法优化特定程序的访问模式。
| 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| LRU | 高命中率,适应访问局部性 | 实现复杂,硬件成本高 | 对性能敏感的高端系统 |
| 随机 | 实现简单,硬件成本低,性能稳定 | 命中率较低,忽略访问规律 | 简单的嵌入式系统或硬件资源有限的场景 |
LRU 实现
- 可以对每一页添加时间字段,可以在页表中也可以专门在物理内存中的一片区域(redis就是这么做的),但代价高。
添加一个 reference bit 使用位(用页表或者bitmap存储)当页被访问(读或写)时,由硬件(MMU)将其置1,操作系统负责将其置0,1代表最近用过了,0代表最近没用过
近似 LRU:时钟算法
维护一个循环列表,里面放着所有页的使用情况,时钟指针指向其中的一页,当需要替换页,如果use bit=1,将其置0,然后移动到下一页,直到寻找到第一个use bit = 0的页,将其换出
脏位
dirty bit的优先级大于use bit 也由MMU维护,硬件会在发生写操作时自动设置脏位,页面换出首先考虑的是未被访问过的干净页,然后是被访问过的干净页。
- 标记页面是否被修改过
- 当一个页面被写入(例如进程对该页面的内容进行了修改),操作系统会将该页面的脏位置为
1。 - 如果页面从加载到内存以来未被修改,脏位保持为
0。
- 当一个页面被写入(例如进程对该页面的内容进行了修改),操作系统会将该页面的脏位置为
- 决定页面是否需要写回磁盘
- 如果一个页面需要被换出(从内存移到磁盘),操作系统会检查其脏位:
- 脏位为 1:表示页面内容已被修改,需要将修改后的内容写回磁盘(例如文件或交换区)。
- 脏位为 0:页面未被修改,可以直接丢弃内存中的内容,因为磁盘上已有最新副本。
- 如果一个页面需要被换出(从内存移到磁盘),操作系统会检查其脏位:
- 减少不必要的磁盘写入
- 通过脏位的判断,可以避免无意义的磁盘写入操作,提高性能。例如,如果页面内容没有修改,就无需将内存中的数据写回磁盘。
LRU-K
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。
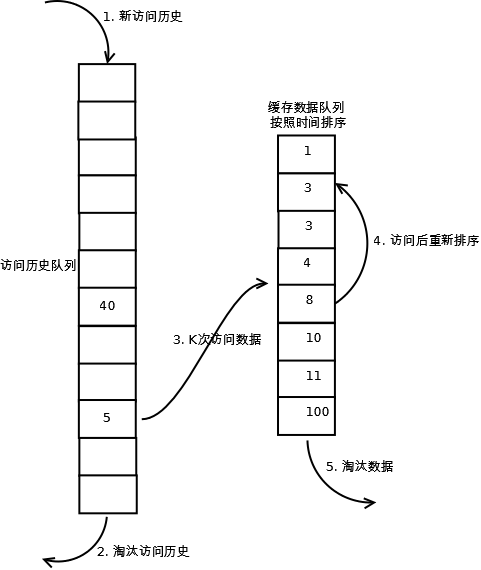
- 数据第一次被访问,加入到访问历史列表;
- 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;
- 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
- 缓存数据队列中被再次访问后,重新排序;
- 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
其他 Swap 策略
页面置换策略:which page to swap out?
页面选择策略:when to swap in which page?
- OS决定何时将页面载入内存,大多数页面是按需载入(demand paging)
- 有时会提前载入(prefetching)马上可能要被访问的页面,比如连续的代码页
写入磁盘策略:when and how to swap out? or not?
- 不一定是内存满了才会开始交换,OS预留部分空闲空间,设置HW和LW,当可用页少于LW,就swap out,直到可用页数达到HW,有一个守护进程
swapd专门做这件事情。 - 交换本身是IO操作,可以通过聚集/分组的方式将多个等待写入写出的页合并操作,提高硬盘效率,执行单次大的写操作比许多小的写操作有效。
- 数据一致性:脏页需要被换出(刷盘, sync)
颠簸(thrashing): 内存被超额请求,os需要不断进行页面的置换,此时可能会考虑终止一些进程(linux oom killer会杀死内存密集型,一般这些都是低优先级的,也有一定的风险)
完整的虚拟内存系统
VAX/VMS 虚拟内存系统
地址空间
应用进程共享内核空间
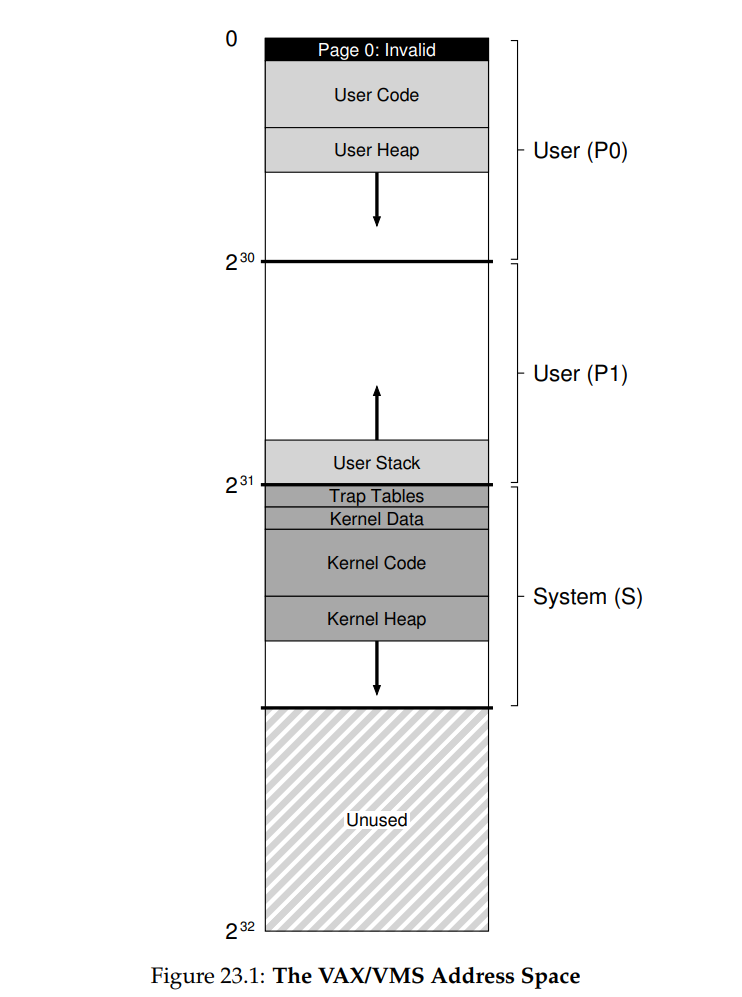
- 地址空间的下半部分称为进程空间,前半段是代码和向下增长的堆(P0),后半段是向上增长的堆(P1),各自拥有一个页表,减少了内部碎片。
- 地址空间的上半段称为系统空间S,只使用其中一半
内核段包含在用户空间中,是所有的进程共享的,这样使得内核与用户程序之间数据交互更加方便,OS可以轻松地解析用户程序传入的指针。通过给系统空间设置保护位来确保内核的安全。
优化页表
- 分出来的两个段,各自有一个页表[段页式管理],减少了内部碎片
- 进程的虚拟地址空间也包含了内核段,因此可以把用户页表纳入受保护的内核虚拟内存中,当存储压力巨大时可以将页表换出到磁盘,有一定的访问性能开销。
空指针
NULL是一个宏,实际上就是0,虚拟地址0有效位始终是0,因此试图访问这个有效位会出现段错误异常,陷入OS终止进程
惰性优化(Lazy)
延迟分配:提供内存利用率的三种机制 - 牛犁heart - 博客园
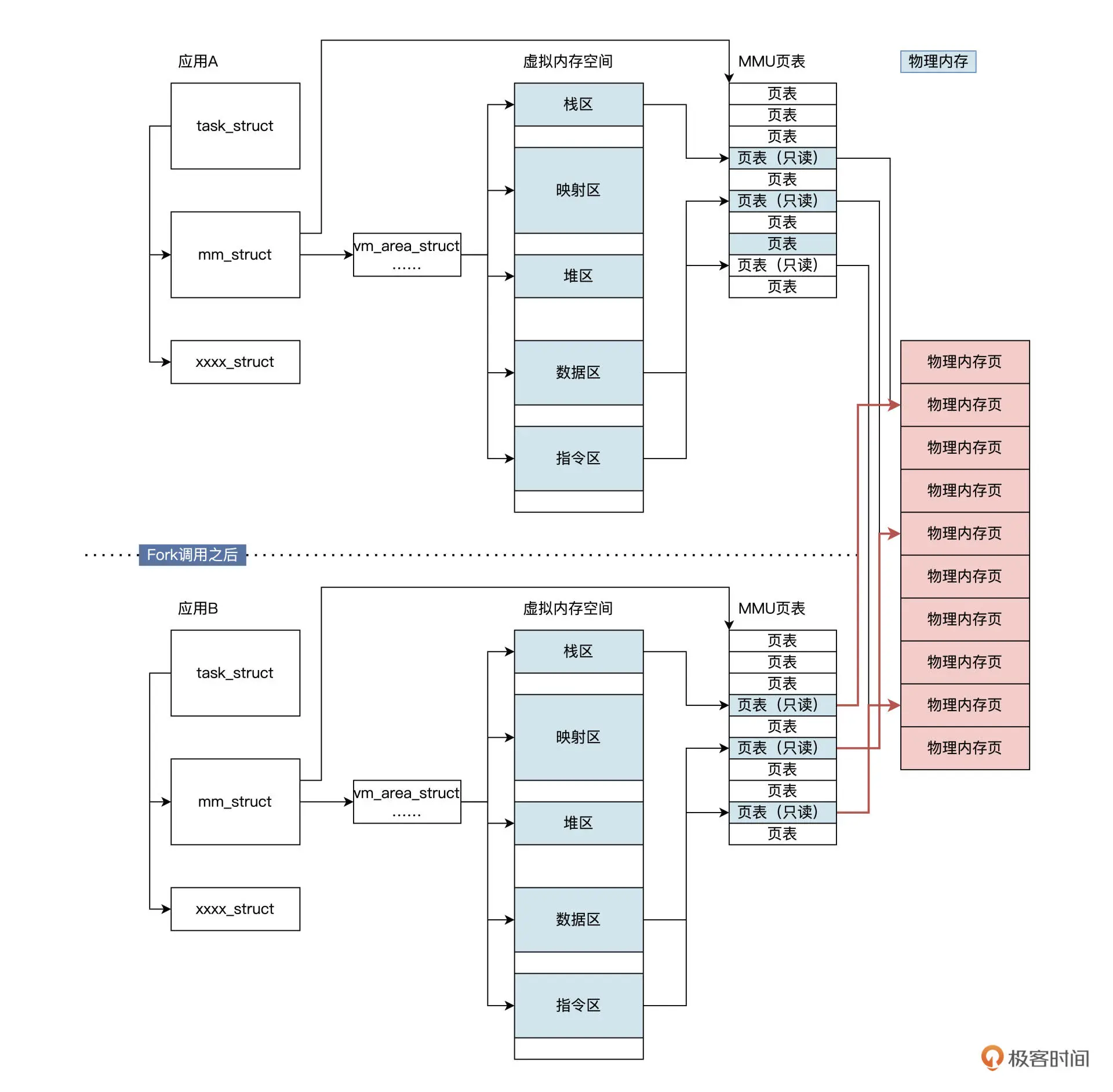
写入时复制 copy-on-write
如果要将一个页面从一个地址空间复制到另一个地址空间,会获取相同的指针,指向相同的资源。这个资源或许是内存中的数据,又或许是硬盘中的文件,直到某个应用真正需要修改某一页时,操作系统才会(惰性地)复制一份该页的专用副本给该应用,填充数据而其他所见的最初资源仍然保持不变。
COW的优点:如果应用没有修改该资源,就不会产生副本,因此多个应用只是在读取操作时可以共享同一份资源,从而节省内存空间。 fork 会复制应用 A 的很多关键数据,但不会复制应用 A 对应的物理内存页面,而是要监测这些物理内存的读写,只有这样才能让应用 A 和应用 B 正常运行
- fork但未写入
- fork后写入
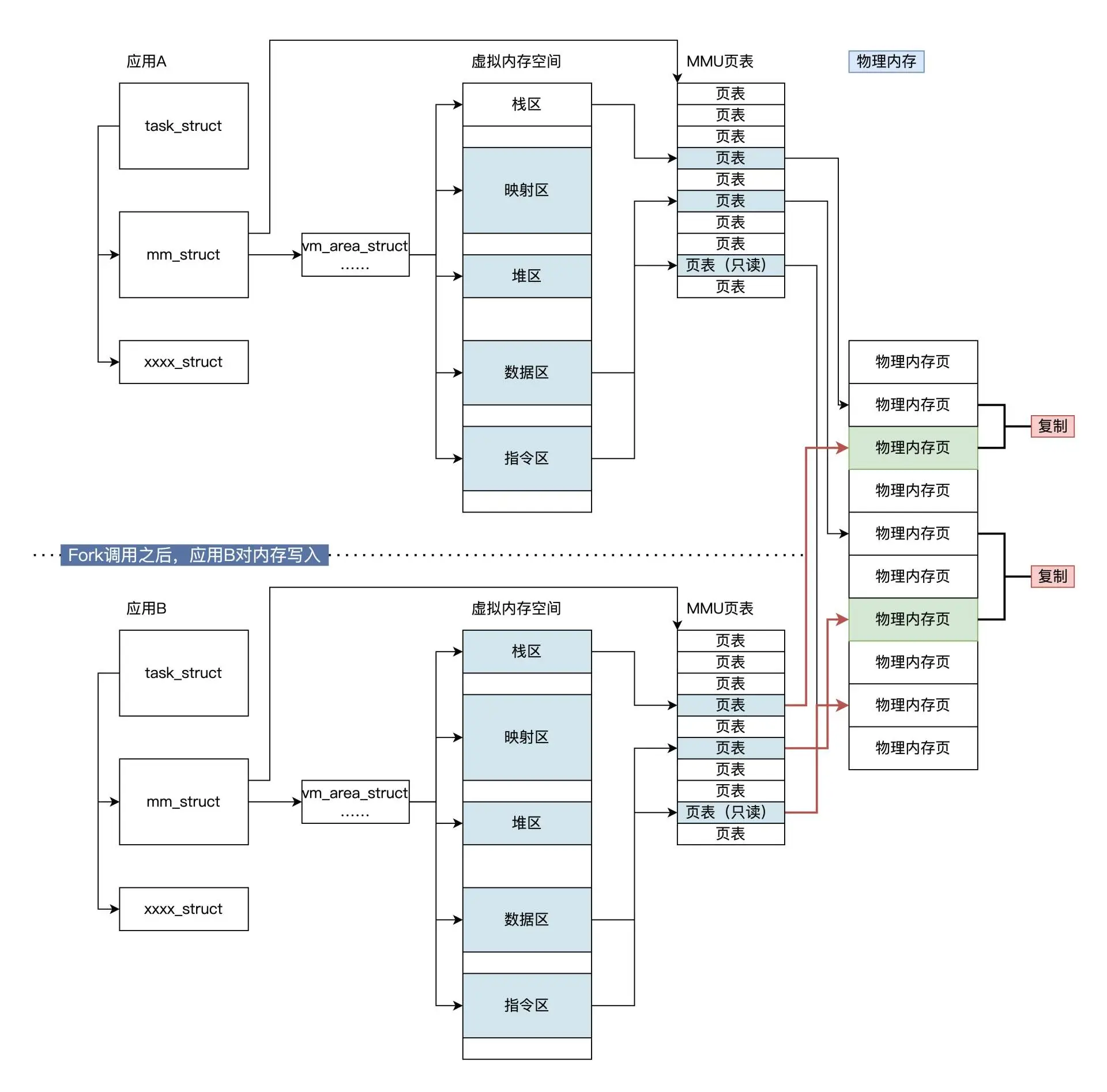
fork()需要复制整个地址空间的内容,如果fork之后还调用了exec,这些地址空间内容又会被马上覆盖,做无用功,cow避免了大量不必要的复制操作,仍然保留正确的语义。
按需调页 demand paging
按需调页是一种动态内存分配技术,更是一种优化技术,它把物理内存页面的分配推迟到不能再推迟为止。之所以能实现,是因为应用程序开始运行时,并不会访问虚拟内存空间中的全部内容。
由于程序的局部性原理,使得应用程序在执行的每个阶段,真正使用的内存页面只有一小部分,对于暂时不用的物理内存页,就可以分配由其他应用程序使用。因此,在不改变物理内存页面数量的情况下,请求调页能够提高系统的吞吐量。
当页添加到地址空间时,会在页表做一个标记(保留的操作系统字段),当进程真正访问到这个虚拟页时,操作系统才会真正寻找物理页并将其置零,映射到地址空间,这样就避免了申请了但是从来不访问 导致浪费的情况。
SWAP 策略
替换策略:Second Chance FIFO
利用的是软性的页错误
- 用RSS(Resident Set Size)限制每个进程可以保存在内存中的最大页数,超过RSS就要“First out”,防止自私进程
- 引入两个全局的页面表,一个记录空闲干净页,另一个记录脏页
- First Out 被换出的页面根据脏位添加到 干净页列表 或 脏页列表 的末尾
- 另一个进程需要空闲页,会先去干净页列表中取出第一个空闲页
- 如果换出页面的进程触发了page fault,则会从表中重新回收页,避免磁盘I/O
批量换出:page clustering
把大批量的页从上述的全局脏页列表中分组聚集到一起,一起写入到磁盘中,使IO次数减少,单次IO写入量更大,提高性能
Linux 虚拟内存系统
Linux 系统主要采用了分页管理,但是由于 Intel 处理器的发展史,Linux 系统无法避免分段管理。于是 Linux 就把所有段的基地址设为 0,也就意味着所有程序的地址空间都是线性地址空间(虚拟地址),相当于屏蔽了 CPU 逻辑地址的概念,所以段只被用于访问控制和内存保护。虚拟空间分布可分为用户态和内核态两部分
地址空间
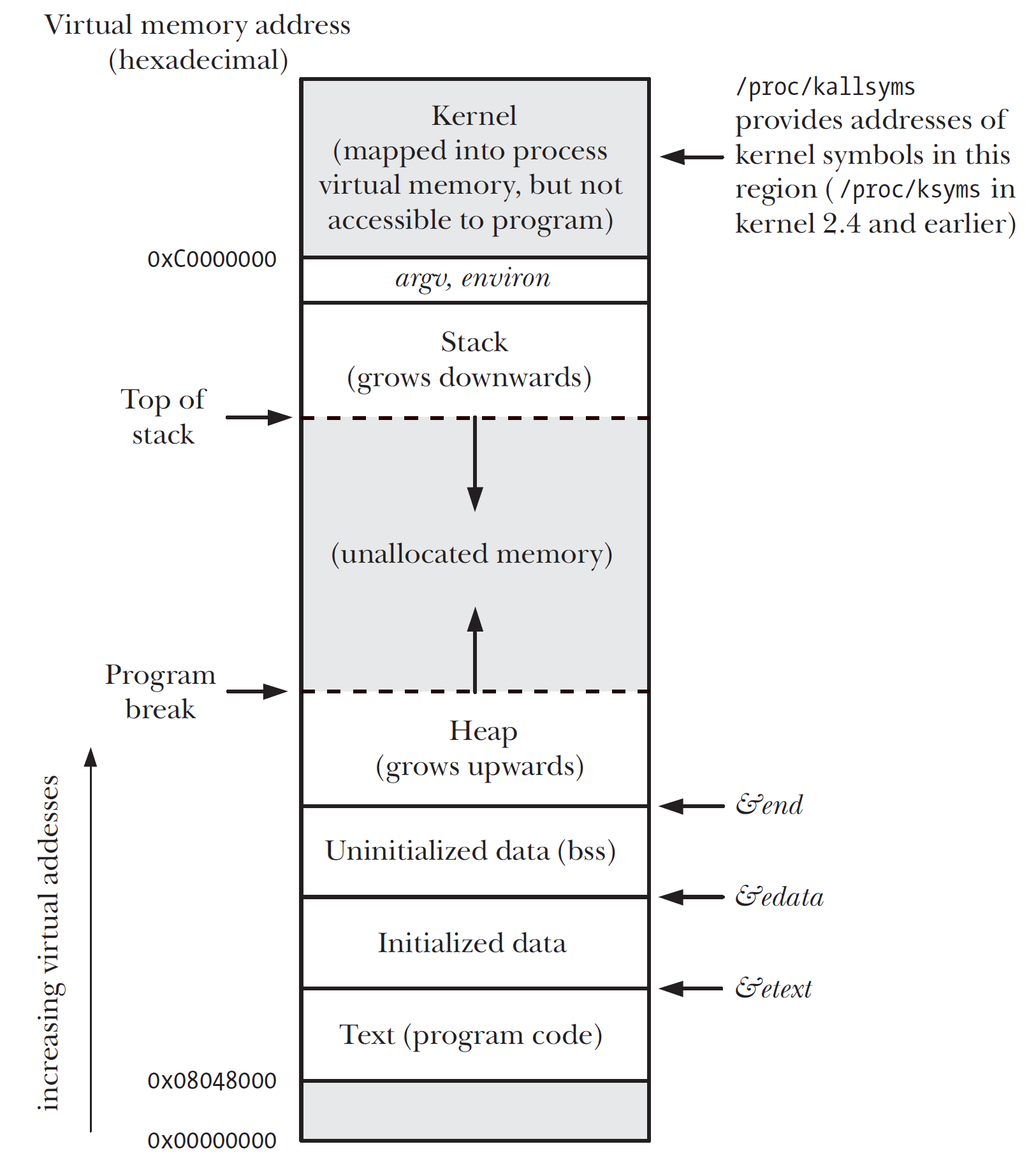
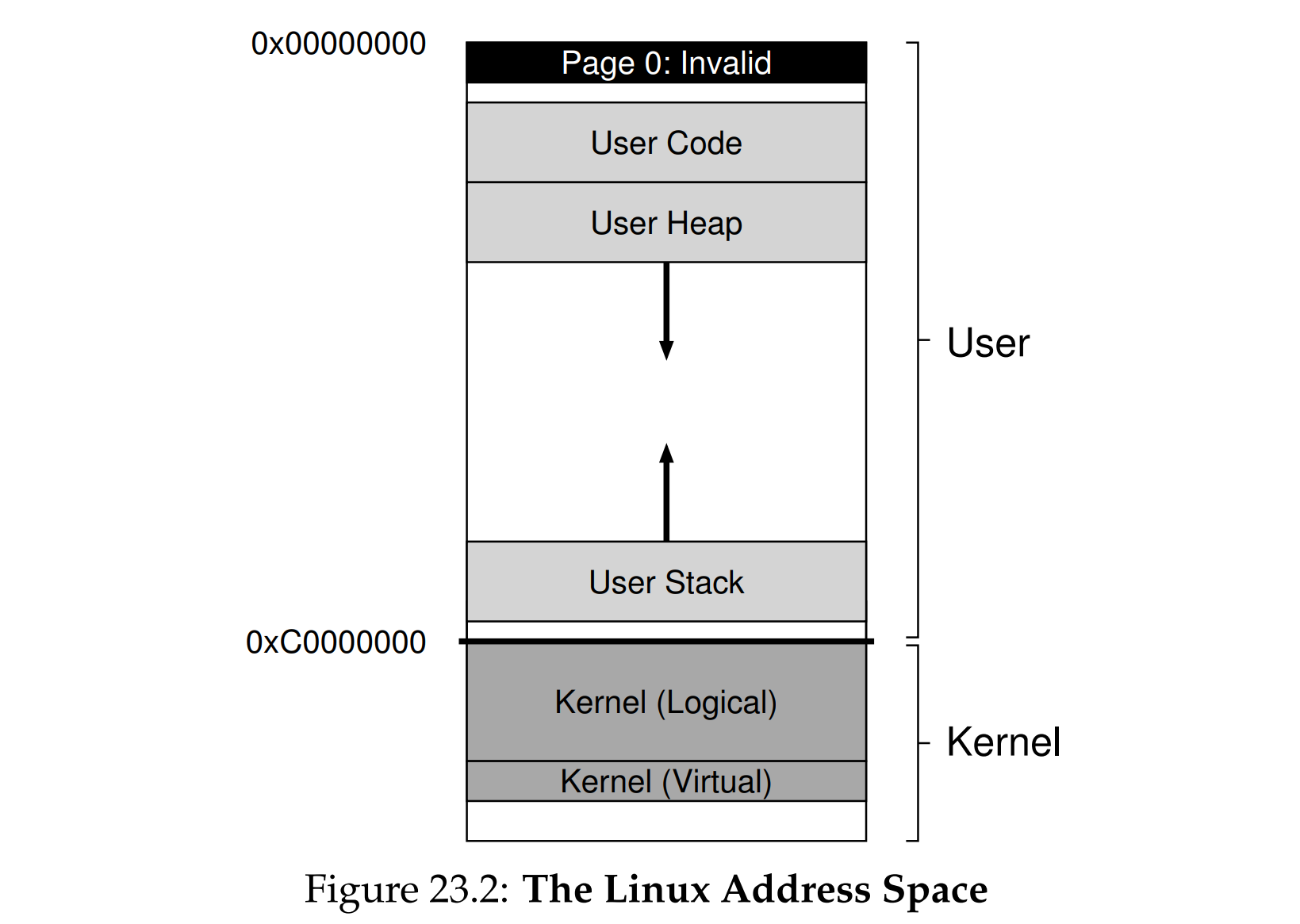
- 0-3GB是用户空间,其中用户态的分布:代码段(.ELF)、全局变量(初始化的数据段)、BSS(未初始化的数据段)、堆内存(Heap)、映射区(mmap)、函数栈(Stack)、初始化参数(argument, environment)
- 最高1GB为内核空间,存放内核的代码以及其他受保护的数据;像VAX/VMS一样,每个用户的进程空间内有着相同的内核。
- 64位的地址空间:低128T为用户空间,高128T为内核空间,中间未定义
逻辑内核空间(kmalloc)
内核代码需要调用
kmalloc申请,内核栈、页表等数据结构存储在这里只能在物理内存中,不能被换出到磁盘
严格的一对一直接映射:
0xC0000000to0x00000000,0xC0000FFFto0x00000FFF不需要进行复杂地址转换,直接将其当成物理地址即可,因此也不需要页表结构
连续的虚拟地址在物理上也一定是连续的
适合DMA
This makes memory allocated in this part of the kernel’s address space suitable for operations which need contiguous physical memory to work correctly, such as I/O transfers to and from devices via direct memory access (DMA)
虚拟内核空间(vmalloc)
- 内核代码需要调用
vmalloc申请,returns 指向连续虚拟内存区域的指针 - 不是直接映射,因此连续的虚拟地址在物理上并不一定连续
- 容易分配(easy to allocate), 因此适合大块缓冲区,因为连续的大块物理内存显然不容易找到
在32位Linux中,虚拟内核空间可以让内核空间大于1GB
Kernel virtual addresses, and their disconnection from a strict one-to-one mapping to physical memory, make this possible. However, with the move to 64-bit Linux, the need is less urgent, because the kernel is not confined to only the last 1 GB of the virtual address space. (64位就没那么重要了)
内存分配
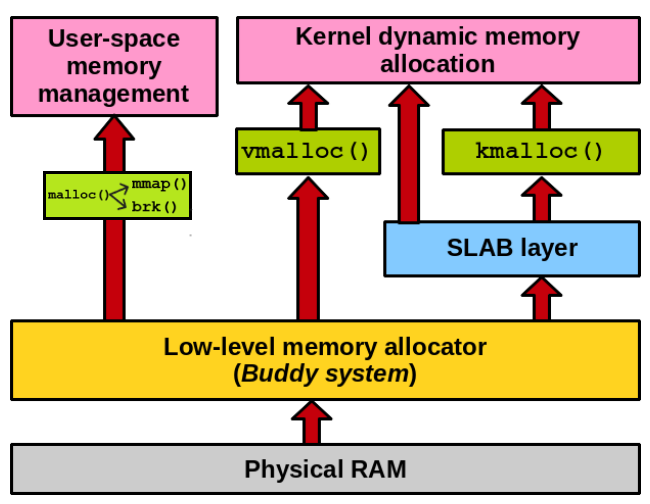
虚拟内存管理
malloc
在不同OS中,malloc的实现也不同,有 dlmalloc, jemalloc, tcmalloc等实现
Linux中,用户可以显式调用mmap或者malloc分配,malloc底层基于mmap(大于128K)或brk(小于128K)
这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
大部分不建议使用brk,brk和sbrk分配的堆空间类似于缓冲池,调用它相当于增大缓冲池。用malloc可以重用前面空闲的内存空间,每次malloc从缓冲池获得内存,如果缓冲池不够了,malloc才会调用brk或sbrk扩充缓冲池,直到达到缓冲池大小的上限,free则将应用程序使用的内存空间归还给缓冲池。而free mmap会直接释放,将空间给操作系统,无法复用,一定会触发缺页中断。
brk
brk 的实现方式是移动Program break,将数据段的最高地址指针 _edata(end of data) 往高地址推(分配的内存小于 128KB),sbrk是通过增量来控制的,原理类似。
同一个程序bss的结束地址是固定的,而heap的起始地址在每次运行的时候都会改变 ASLR。
当ASLR(Address Space Layout Randomization)关闭时,
start_brk和brk同时指向data/bss段的结束位置(end_data)。当ASLR打开时,
start_brk和brk同时指向data/bss段的结束位置(end_data)再加上一个随机的brk偏移。
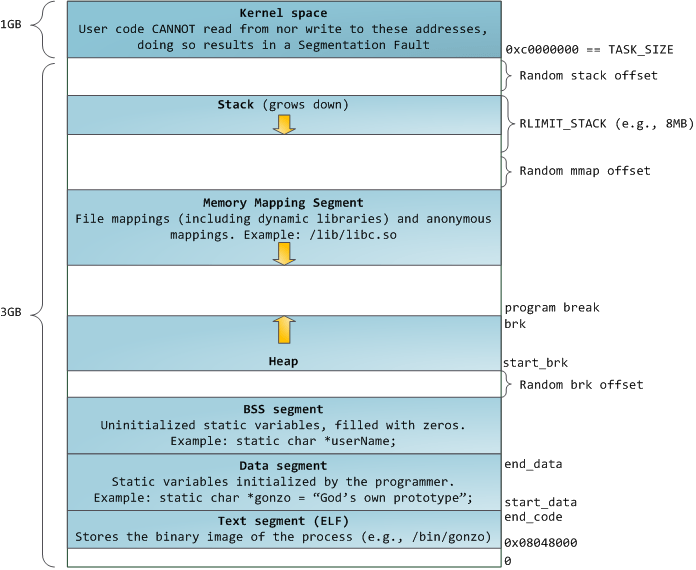
brk的问题:
使用brk连续申请了10K, 20K, 30K内存,前两部分释放了,但是不会归还给操作系统,如果再次申请内存小于30K,就可以复用空闲区域,但是如果申请40K,就会出现内部碎片问题,只能继续新申请40K内存,导致大量内存碎片问题
mmap
在用户进程空间内的内存映射段找一块空闲的虚拟内存(分配的内存大于 128k))—匿名空间,具体使用可见: Memory-mapped I/O
物理内存管理
伙伴系统(Buddy system)
Buddy分配系统在普通内存池的基础上,允许两个大小相同且相邻的内存块合并,合并之后的内存块的「尺寸」增大,因而将被移动到另一个内存池的free list上。
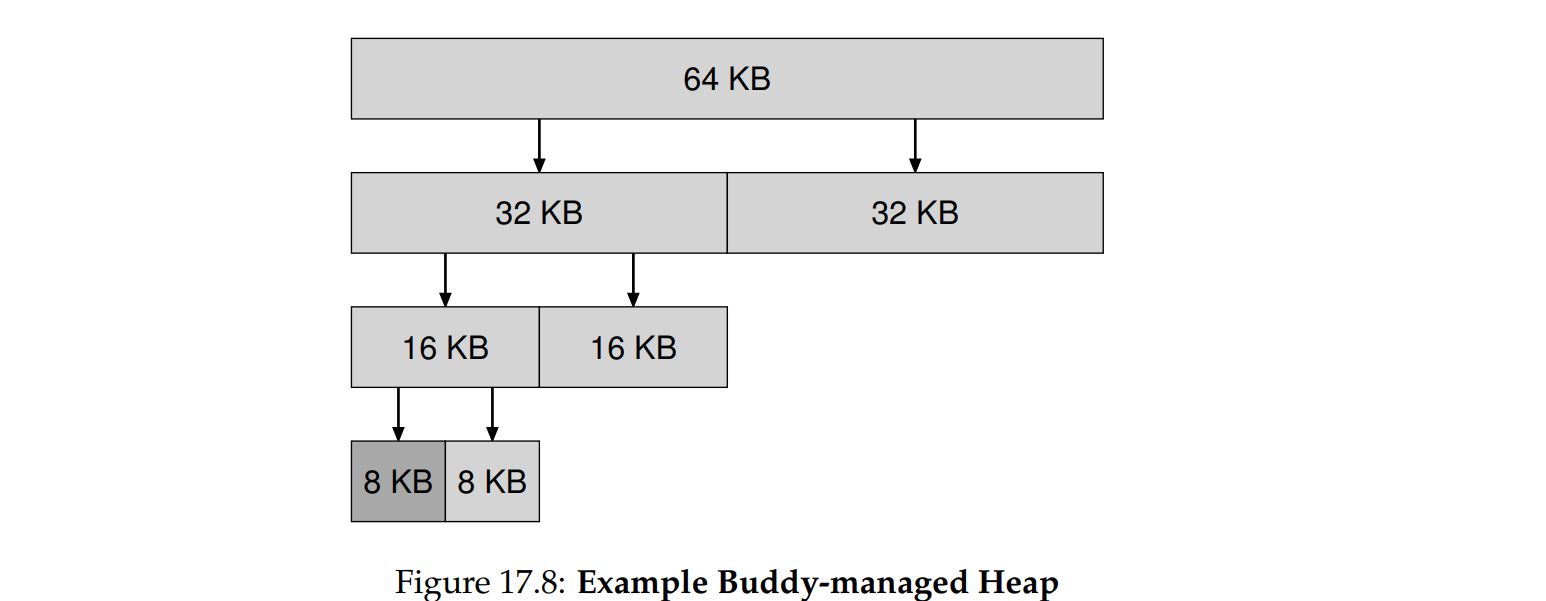
总空间为2^N^,按照递归二分法分配内存,直到块大小刚好满足要求(显然这会导致内部碎片)当一个块释放的时候,allocator会检验与他相同大小的相邻块(buddy)是否空闲,若是则将二者合并,直到合并全部空闲内存。
优点:buddy的地址很容易确认,既然是相邻,说明首部地址只差一位,这个位决定了他们在整个数中的层次
在 Linux 系统中,连续内存管理采用了 伙伴系统(Buddy System)算法 来实现,对于内部碎片的问题,采用了SLAB进行解决。
它把所有的空闲页放到11个链表中,每个链表分别管理大小为1,2,4,8,16,32,64,128,256,512,1024个页的内存块。当系统需要分配内存时,就可以从buddy系统中获取。当分配内存时,会优先从需要分配的内存块链表上查找空闲内存块,当发现对应大小的内存块都已经被使用后,那么会从更大一级的内存块上分配一块内存,并且分成一半给我们使用,剩余的一半释放到对应大小的内存块链表上。
想要分配一个8KB大小的内存,但是发现对应大小的内存已经没有了,那么伙伴系统会从16KB的链表中查找一个空闲内存块,分成两个8KB大小,把其中的一个8KB大小返回给申请者使用,剩下的8KB放到8KB对应的内存块链表中进行管理。更坏的一种情况是,系统发现16KB大小的连续内存页已经没有了,那么以此会向更高的32KB链表中查找,如果找到了空闲内存块,那么就把32KB分成一个16KB和两个8KB,16KB的内存块放到16KB的链表进行管理,两个8KB的内存块一个返回给申请者,另一个放到8KB大小的链表进行管理。
当释放内存时,会扫描对应大小的内存块链表,查看是否存在地址能够连续在一起的内存块,如果发现有,那么就合并两个内存块放置到更大一级的内存块链表上,以此类推。比如我们释放8KB大小的内存,那么会从对应的链表扫描是否有能够合并的内存块,如果有另一个8KB大小的内存和我们使用的内存地址连续,那么就合并它们组成一个16KB大小的内存块,然后接着扫描16KB大小的内存块链表,继续查找合并的可能,以此类推下去。
操作系统的内存管理通常是基于页(page)的概念,即操作系统将物理内存分为固定大小的页。页是内存管理的基本单位,这样可以统一管理和访问内存。页的大小通常是2的幂次方,例如4KB、8KB或16KB等。
- 操作系统需要高效地管理内存,而将内存管理的单位限定为页大小可以简化这一过程。每一页都有一个对应的页表项,操作系统只需要管理页而不是单个字节或更小的单位。这减少了管理开销。
分离空闲列表(SLAB, segregated free lists)
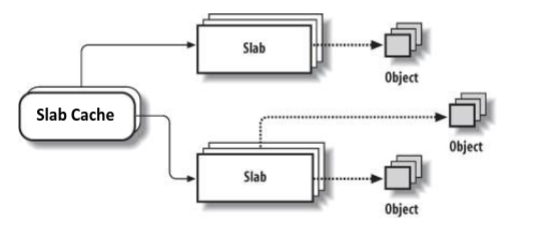
为了方便管理,Linux中的buddy allocator以物理页框为最小粒度,而现实的应用中,操作系统作为一个一直在运行的程序,多是以内核objects(比如描述文件的”struct inode”)的大小来申请和释放内存的,这些内核objects的大小通常从几十字节到几百字节不等,远远小于一个page的大小。如果程序固定分配一个或者几个大小的的内存,那就专门给他分配一块内存用于分配这些固定大小空间,减少了大小上的差异,碎片自然也就少了
在内核启动时,为诸如锁、文件inode之类频繁请求的内核object分配 Object cache,他们的对象缓存分离了特定大小的空闲列表,获得了性能上的提升,当cache将要耗尽时从通用的内存分配程序申请slab(总量是page size和object size的最小公倍数)例如,2.5KB objectsize, 4KB pagesize 就去申请5个页, 专门用来放这种object,一个页能放5个
当cache中内核object的引用计数变为0,通用的内存分配程序会从专用的分配器中回收这些资源。同时还使空闲对象保持在预初始化的状态,避免频繁销毁、初始化的开销。
Linux实现
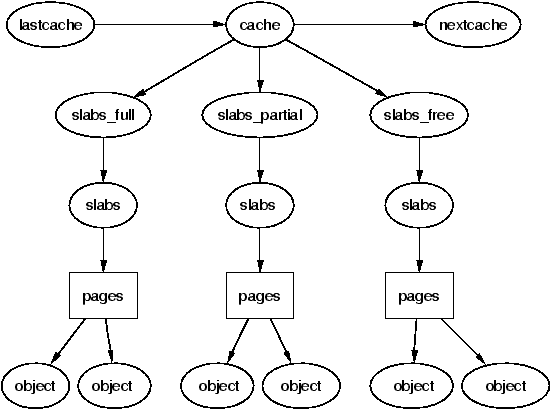

每个kmem_cache都是链接在一起形成一个全局的双向链表,系统可以从Cache_chain开始扫描每个kmem_cache(相当于上面说的内存池, fixed size)
slab是内存池从系统申请内存的最小单位,在实现上一个slab有一个或多个连续的物理页组成(通常只有一页)单个slab可以在slab链表之间移动,例如如果一个slabs_partial中的slab被分配了对象后变满了,就要从slabs_partial中被删除,同时插入到slabs_full中去。
页表结构
虚拟地址:

4KB的页大小对应12位offset,共四级页表,每级索引为9位,一个表条目占用4B空间,一张表正好占满一页
更大的页大小(huge pages)
Specifically, recent designs support 2-MB and even 1-GB pages in hardware. Thus, over time, Linux has evolved to allow applications to utilize these huge pages (as they are called in the world of Linux).
提升 TLB 命中率
一方面是减少了页表项数,更重要的是提升了TLB的命中率(hit rate):
- TLB的条目数(slots)是固定的,因为空间局部性,同一页放更多数据,将更多的物理内存空间纳入到TLB中
- 换个角度,如果发生TLBmiss,因为页表项数的减少,遍历速度就会加快
- 与此同时,某些情况下也可以加快分配内存
如何申请
一些对性能要求严格的应用如大型数据库应该使用更大的页大小,用来提高性能,必须通过mmap或者shmget进行显式申请,因此其他正常使用4KB页大小的程序不受影响。
**透明大页(transparent huge pages)**:不需要应用程序修改源代码,OS 会自动根据情况决定是否分配大页。
缺陷
Huge pages are not without their costs. The biggest potential cost is internal fragmentation, i.e., a page that is large but sparsely used. This form of waste can fill memory with large but little used pages. Swapping, if enabled, also does not work well with huge pages, sometimes greatly amplifying the amount of I/O a system does.
- 内部碎片:由于各种内存操作基本都要求按照page对齐,比如一个可执行文件映射到进程地址空间,根据文件大小的不同,平均算下来会浪费掉半个page size的物理内存,使用large page的话这个消耗就显得比较大了。
- 需要连续大块的物理内存:系统运行一段时间后,会很难再也大块的连续物理内存,这时分配large page将会变的很困难,所以通常需要在系统初始化的时候就划分出一段物理内存给large page用(类似于DMA的内存分配),这样就减少了一些灵活性。
- swap开销大:动态large page(THP)在换出到外部的flash/disk和从flash/disk换入物理内存的过程会比normal size的page带来更大的开销(可参考这篇文章)。
Page Cache/Disk Cache
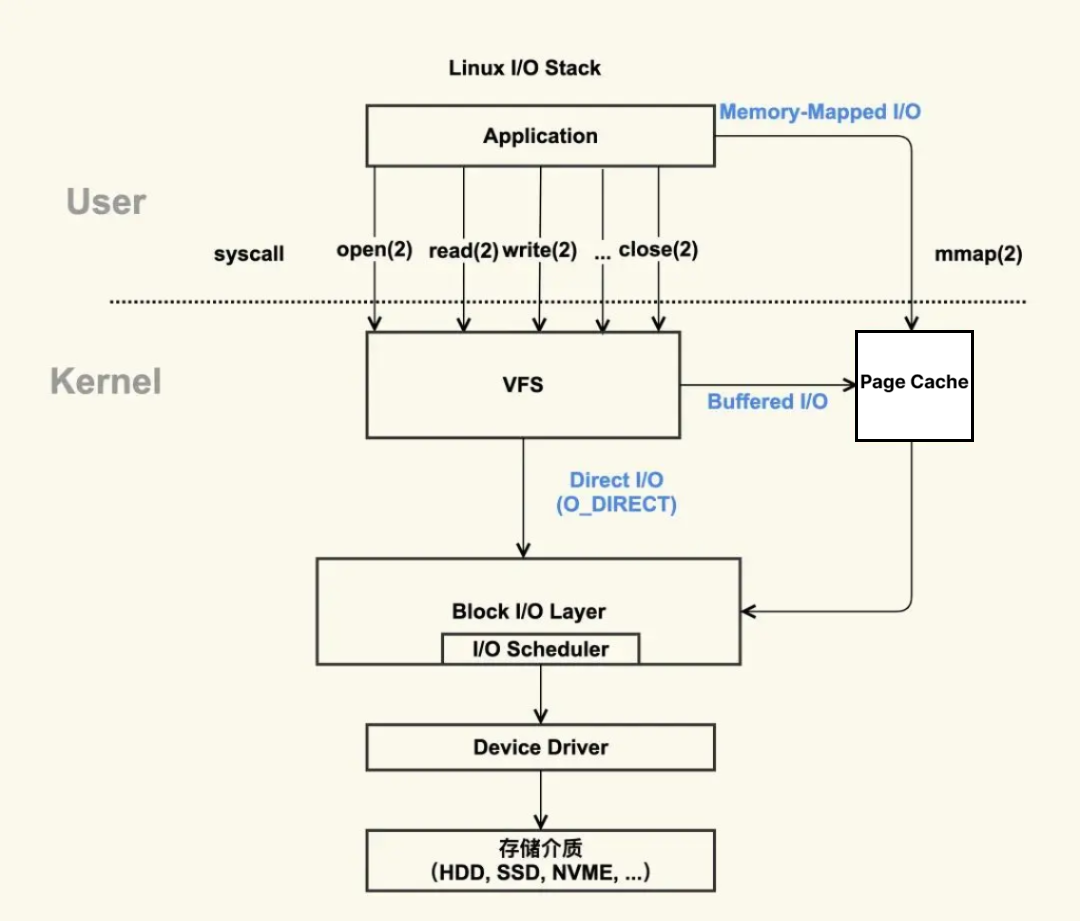
Page Cache 是由内核管理的内存,位于 VFS(Virtual File System) 层和具体文件系统层(例如ext4,ext3)之间。应用进程使用 read/write 等文件操作,通过系统调用进入到 VFS 层,根据 O_DIRECT 标志,可以使用 Page Cache 作为文件内容的缓存,也可以跳过 Page Cache 不使用内核提供的缓存功能
aggressive caching subsystem to keep popular data items from persistent storage in memory
Buffered I/O: IO缓存 (
read(),write()) [dentry, inode cache]Memory-mapped I/O: 内存映射 mmap()
- File-backed 文件映射: 其可以将文件内容映射到用户空间,虚拟内存和磁盘文件中间通过 Page Cache 进行数据中转,因此可以像普通虚拟内存一样访问文件,这些虚拟内存在磁盘中有对应的文件,读取这部分内容就像是文件I/O一样
- Anonymous Mapping 匿名映射: mmap以
MAP_ANONYMOUS方式申请内存,这些虚拟内存在磁盘中没有确切的文件,持久化到swap space,全部初始化为0,
通过
page_cache_hashtable搜索,加快访问速度。
Memory-mapped I/O
Linux 下的两个特殊的文件 – /dev/null 和 /dev/zero 简介及对比_linux空洞文件null-CSDN博客
Linux 内存映射函数 mmap()函数详解_mmap fb-CSDN博客
void* mmap(void* start, size_t length, int prot, int flags, int fd, off_t offset);int munmap(void* start, size_t length);prot:保护位PROT_EXEC,PROT_READ,PROT_WRITE,PROT_NONEflags:MAP_SHARED共享模式MAP_PRIVATE写时复制,不共享MAP_ANONYMOUS匿名模式fd无效fd:文件描述符,如果是匿名模式可以置为-1,或者打开/dev/zero获取其fdoffset:文件映射的偏移量,通常设置为0,代表从文件最前方开始对应,offset必须是分页大小的整数倍。
fopen()系统调用打开文件,并返回描述符fd。mmap(start,...)建立内存映射并返回映射首地址指针start参数start可以是空指针,系统自动分配地址- 通过对
start对文件进行各种操作,首次访问start指向的内容会触发页错误(demand paging) munmap (start,...)关闭内存映射fclose(fd)系统调用关闭文件fd
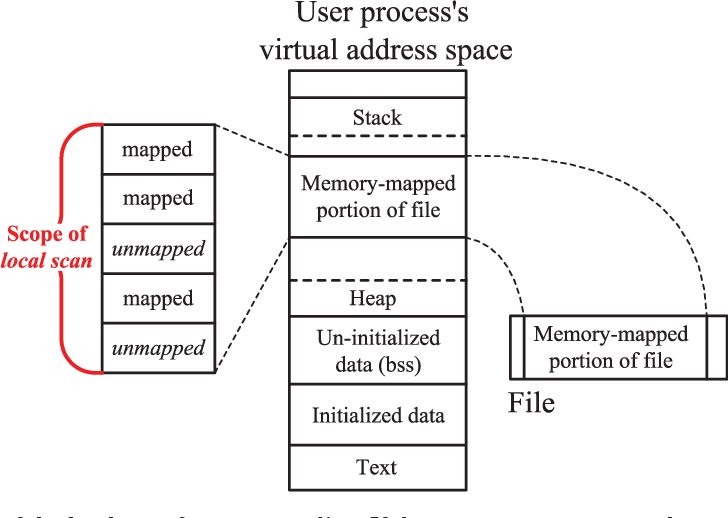
通过对一个打开的FD调用mmap(),进程能够获得一个指向内存映射区的指针,内存映射区是一个独立区域,因此可以独立释放。通过这个指针就能够对文件进行操作。这里采用了demand paging——懒加载的策略,直到第一次访问触发页错误,才会真正把文件内容分配到物理页中。
数据一致性:
- files:程序通过
mmap映射文件时,如果页面未修改(脏位为0),无需将内存中的数据写回磁盘 - Swap space:当内存不足时,未被修改的页面无需写回磁盘的 Swap space,节省时间和空间
即使不显式调用mmap也会使用这个共享的文件映射区域,比如从可执行文件中加载的代码、进程之间共享的库代码
使用pmap分析tcsh进程的虚拟内存映射情况如下:
1 | Virtual Address Size Protection Source |
除了tcsh自己的代码,libc, libcrypt, libtinfo 这些共享库代码也被加载到tcsh的虚拟地址空间中,连接器ld的可执行代码也在其中。[anon]表示自己的heap堆空间,[stack]表示自己的stack栈空间
和 shmem 的区别:
System V 共享内存是持久的:除非被进程显式删除,否则它会保留在内存中并保持可用,直到系统关闭。 mmap 内存在应用程序的执行之间不是持久的(除非它由文件支持,MAP_SHARED)
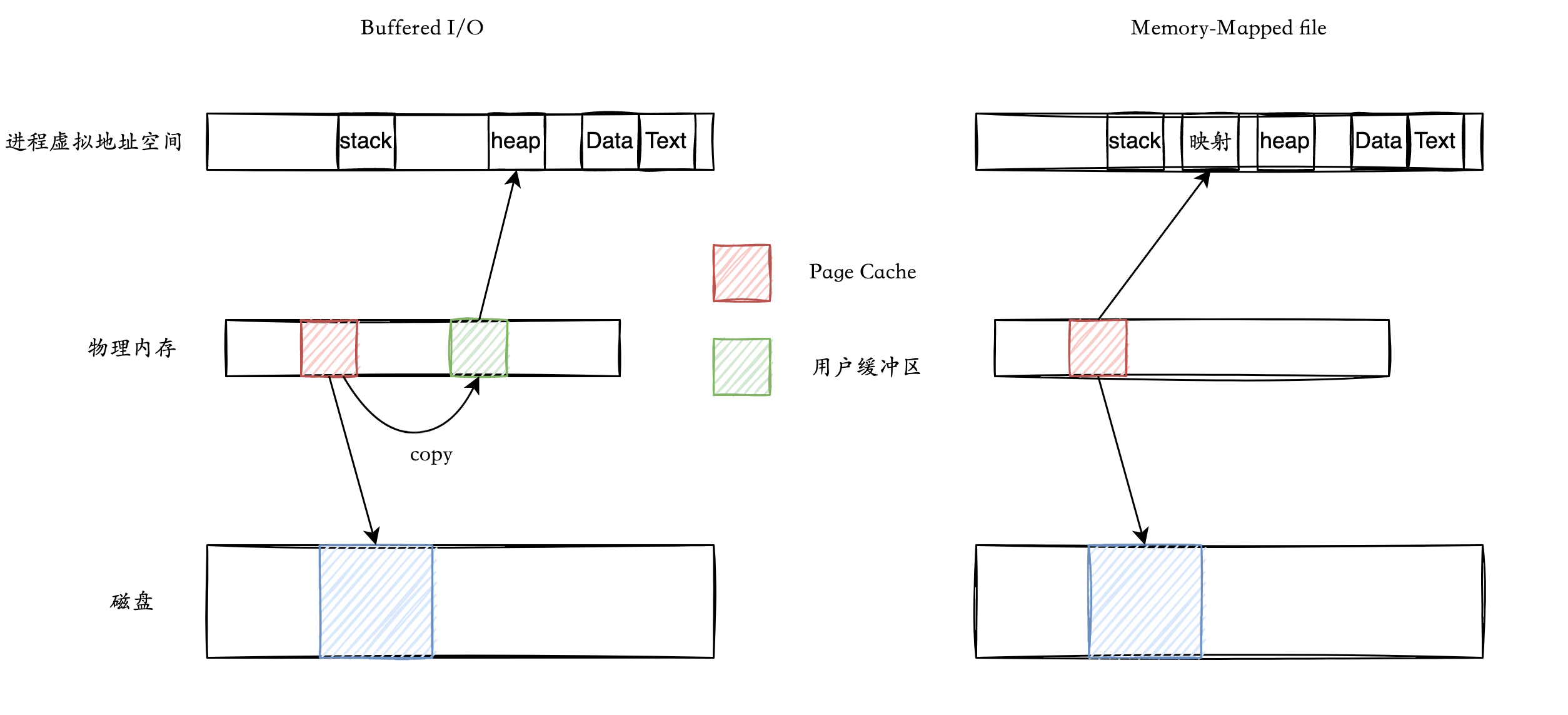
Buffered I/O
Buffered I/O 与 内存映射文件 的区别:
读取机制
int fd = open(file_path)- fd是内核对打开的文件的编号,通过fd就可以操作文件
int c = read(fd, buf, 512)- 由内核负责将 fd 翻译成 inode+offset
- 读取inode,如果page cache没有就从磁盘读,然后写入inode到Page cache中
- 读取对应偏移的block,如果page cache没有就从磁盘读,然后写入block到Page cache中
- 从内存中的 cached block 复制 512 B 到 buf 中
写入机制
Write-back (default)
write back 写回 只对缓存进行操作 read-allocate 先把数据读取到Cache中,再从Cache中读数据
By default, kernel marks written pages dirty and flushes after a delay:
int fd = open("myfile");write(fd, "hello world", 11)- 内核将hello world字符串写入到 cached block 对应的 page cache 页中
- 内核将被修改的页加入脏页列表中
- 按照一定的策略进行刷盘
在系统发生宕机的情况下无法确保数据已经落盘,因此存在数据丢失的问题。不过,在程序挂了,例如被 kill -9,Page Cache 中的数据操作系统还是会确保落盘;
Write-through
直写,在更改page cache的同时刷盘(synchoronized)
O_SYNC flag converts file descriptor to write-through
int fd = open("myfile", O_SYNC |...);write(fd, "hello world", 11);- This affects all accesses to the same disk blocks
以牺牲系统 I/O 吞吐量作为代价,向上层应用确保一旦写入,数据就已经落盘,不会丢失
脏页刷盘
Page cache 追踪脏页,保存一个脏文件inode链表,脏页需要写入到磁盘的文件或者swap space中,确保内存数据的持久化,可以由叫做pdflush的后台线程,唤醒方式有如下
定期唤起
pdflush,确保不会有脏页驻留时间过长在脏页比例达到阈值时,按照一定速率刷盘(1024)
内存可用空间低到一定阈值,刷脏页释放内存
响应特定的系统调用
fsync(int fd)将fd的脏数据和所有脏元数据刷盘fdatasync(int fd)将fd的脏数据和必要的脏元数据刷盘sync()将全部脏页刷盘O_SYNC文件打开方式要求同步写操作
应用
- 文件映射:程序通过
mmap映射文件时,如果页面未修改(脏位为0),无需将内存中的数据写回磁盘。 - 交换区:当内存不足时,未被修改的页面无需写回交换区,节省时间和空间。
Direct I/O
Buffered I/O要在磁盘和VFS之间加一层Page cache,对于写入操作,需要在cache中开辟新页,然后将其标记为脏。
OS cache提供的这些预读取、顺序读取等特性,这些特性并不适用于所有的场景,比如数据库,数据库通常都有自己的一套缓存机制,就像mysql的innodb存储引擎,它有自己的缓存页,有自己的落盘机制,如果不使用directIO,这明显就会存在双重的cache,一个是OS设计的,一个是DB设计的,而通常,DB需要更加符合自己使用的cache机制,而非OS提供的通用化的缓存机制。直接写入不会将要写入的数据先从磁盘读到cache,而是直接将要写的数据写入磁盘。
O_DIRECT 下的 I/O 操作是直达磁盘的,用户空间通过 DMA 的方式与磁盘以及网卡进行数据拷贝。
页面置换:2Q
关键词:预读失效 + 缓存污染
- 预读失效:提前加载到内存,但是并没有访问
- 缓存污染:加载到内存,但是只访问一次
LRU:如果打开一个非常大的文件,LRU会把其他在内存中的文件都淘汰掉,但是写入这个文件到内存中并没有什么用,就和循环访问一样,文件之前的数据在被淘汰掉之前再也被访问。
Linux的2Q(Two queue)策略
该算法类似于LRU-2,不同点在于2Q将LRU-2算法中的访问历史队列(注意这不是缓存数据的)改为一个FIFO缓存队列,即:2Q算法有两个缓存队列,一个是FIFO队列,一个是LRU队列。
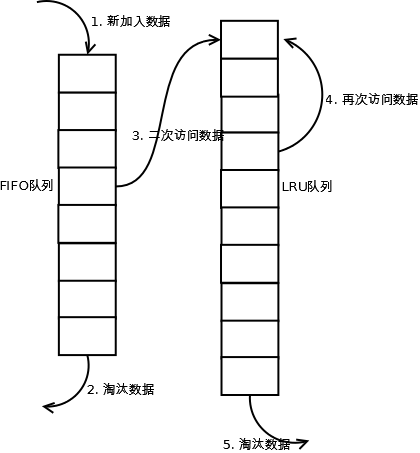
Linux对于2Q的实现,只淘汰FIFO队列里面的数据:
Page cache(Buffered I/O或mmap)维护两个队列:
inactive list(FIFO), active list(LRU)
- 第一次被访问,将页面加入
inactive list - 之后的访问,将页面升至
active list - 需要进行替换时,
inactive list进行FIFO active list对定期 LRU 到inactive list,使active list占 Page cache 的2/3左右。- 循环访问大文件时,大文件的页面不会跑到
active list中,因此原来active list的页面就不会被迫换出
其他策略
fork()采用COW写时复制的策略,减少无效的复制swapd可以监控内存状况,内存占用过高(watermark)换出页面,释放到安全水平(异步)- swappiness:修改换出页面的积极性,0为不主动换出
- 关闭swap:服务器内存本身足够大,不需要换出操作,因为会降低效率
- 内存颠簸(thrashing) 虚拟内存申请,但是物理内存几乎占满,导致同时出现大量缺页错误,此时linux oom killer会杀死内存密集型,一般这些都是低优先级的,也有一定的风险)
安全
现代操作系统最大的一个特点就是对安全的注重,仅仅使用内核
针对用户程序:缓冲区溢出攻击
1 | int some_function(char *input) { |
如果输入超过缓冲区,input就会开始覆盖其他数据,攻击者可以利用缓冲区溢出注入他们的恶意代码,在页表中引入NXbit能够在一定程度上解决问题,但是黑客可以更改函数的执行栈,将函数的返回值指向恶意代码的地址。
return-to-libc attack:==ROP==
Thus, an attacker can overwrite the stack such that the return address in the currently executing function points to a desired malicious instruction (or series of instructions), followed by a return instruction.
By stringing together a large number of gadgets (i.e., ensuring each return jumps to the next gadget), the attacker can execute arbitrary code. Amazing!
address space layout randomization:==ASLR==
Instead of placing code, stack, and the heap at fixed locations within the virtual address space, the OS randomizes their placement, thus making it quite challenging to craft the intricate code sequence required to implement this class of attacks.
ASLR可以确保客户的程序只崩溃不执行恶意代码,ASLR将brk、mmap、stack的开始段加一些随机数,
由此衍生出了KASLR,内核的地址空间也可以随机生成
1 | //random.c |
针对内核程序:Meltdown & Spectre
利用了 CPU 预测执行的漏洞,分支预测将串行的程序变成了并行的,而前后数据依赖,不可避免地在硬件上留下了踪迹,造成了并发安全问题
1 | mov rax byte[x] ; 非法操作 将x的数据拷贝到rax |
解读 Meltdown & Spectre CPU 漏洞 - 知乎
操作系统会事先标注好内核的内存地址范围,如果 x 在内核的这个地址范围内,并且 CPU 不是以内核模式运行的话,那么该指令会被 CPU 标注为非法,引起异常,异常处理程序会将 rax 清空为0,并且终结此程序,这样后续指令再来读 rax 的时候就只能读到0了。
理论上讲,在执行第二条指令之前,rax应该已经被清零了。然而在实际的 CPU 运行中,为了达到更好的性能,第二条和第三条指令在异常处理生效之前都会被部分执行,直到异常处理时 rax 和 rbx 被清零。
但问题的关键就在第三行指令:如果地址 rbx + rax 不在cache中的话,CPU 会自动将这一地址调入cache中,以便之后访问时获得更好的性能,然而异常处理并不会将这个cache flush掉。而这条 cache 的地址是和 rax 直接相关的,这样就相当于在 CPU 硬件中留下了和rax 相关的信息。

那么如何还原 rbx + rax 这个被cache的地址呢?这时候需要用到的原理就是利用cache的访问延时,即已经被cache的数据访问时间短,没有被cache的数据访问时间长。由于[rbx]这个array是在用户地址空间内的,可以自由操作,首先我们要确保整个 [rbx]这个array 都是没有被cache的,然后执行上述攻击代码,这时候 rbx + rax 这个地址就已经被cache了,接下来遍历整个[rbx] array,来测量访问时间,访问时间最短的那个 page 就可以确定为 rbx + rax。
对于个人终端用户,利用Meltdown与Spectre漏洞,低权限用户可以访问内核的内容,泄露本地操作系统底层的信息、秘钥信息等,通过获取泄露的信息,可以绕过内核的隔离防护;如果配合其它漏洞,可以利用该漏洞泄露内核模块地址绕过KASLR等防护机制实现其他类型的攻击进行提权。另外,利用浏览器JIT特性预测执行特殊的JIT代码,从而读取整个浏览器内存中的数据,泄露用户帐号,密码,邮箱, cookie等隐私信息。
因此,增强内核保护的一种途径是从每个用户进程中删除尽可能多的内核地址空间,并为大多数内核数据提供单独的内核页表(称为内核页表隔离,或 KPTI)[G+17]。因此,不是将内核的代码和数据结构映射到每个进程中,而是只保留最低限度的代码和数据结构;当切换到内核时,现在需要切换到内核页表。这样做可以提高安全性并避免一些攻击媒介,但代价是:性能。切换页表的成本很高。
内存虚拟化总结
虚拟地址的作用
虚拟地址的翻译(重定位)
- 段式 base+bound, bound varies from each other
- 页式 fixed bound
- 段页式
- 多级页表 fill one page with one table, hi-level table points to low-level table
- TLB:翻译缓存
Swap:将物理内存看作虚拟内存的缓存
- 机制:Page Fault & Disk I/O
- 策略:
- 是否需要SWAP?物理内存充足就没必要开启
- 具体换出哪一页?LRU, FIFO, Random, Second Chance, LRU-K, 2Q, Clock
- 何时换出?(被动watermark、主动swappiness>0)
- 一次 I/O 换出多少页?(clustering)
- 何时换入?(lazy aka. demand paging)
- 一次 I/O 只换入一页吗?(prefetching)
内存分配:
- 机制:空闲空间链表节点的分割与合并
- 物理:Buddy, SLAB
- 虚拟:mmap malloc brk