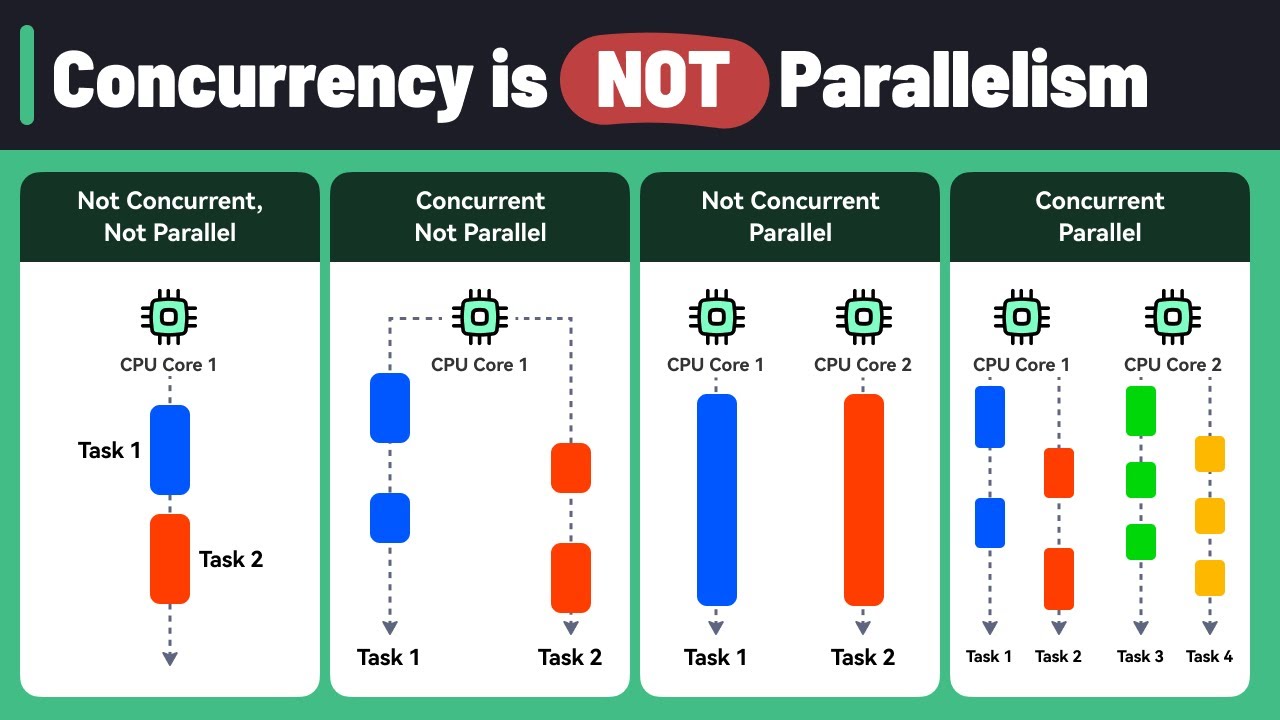
同一时刻,多条指令在一个CPU上同时执行,物理上和逻辑上都是同时执行的。分布式计算 (Distributed computing)是并行计算 的一个特例,它采用计算机网络来进行同步。
分类 指令级并行,线程级并行,数据级并行区别?线程的概念是什么? - 知乎
线程级并行 TLP 线程级并发(Concurrency)
并发计算 - 维基百科,自由的百科全书 (wikipedia.org)
并发是一种现象 ,比并行更加抽象,同时运行多个程序或多个任务需要被处理的现象。
它可以执行在单一处理器 上,将不同的执行步骤分散在不同时间片 中执行,以非并行 方式循序运算,通过操作系统调度CPU快速切换执行上下文来实现宏观上的“并行”
它也可以用真正的并行计算 来实现,将每个行程指定给处理器组中的某个处理器,以单片机多处理器 平台,或是透过网络链接的分散 平台来实做。
coroutine就是典型的并发不并行
操作系统通过时间片轮转调度,在不同的任务之间来回切换.
对cpu而言,这两个进程其实不是同时进行的;
线程级并行(Parallelism) 一个核心仍然无法处理多个线程
英特尔和AMD也意识到,当主频接近4GHz时,速度也会遇到自己的极限:那就是单靠主频提升,已经无法明显提升系统整体性能 。因此迫切需要一个能支持同时处理2个线程以上的处理器,来提升CPU的瓶颈。需求推动了技术,线程级并行应运而生 。主要由下面两种技术的支撑:
超线程(Hyper-Threading,HT/SMT) 2004年,奔腾4实现了Hyper-Threading(单核心双线程)
超线程技术实现了单个物理核心同时两个线程,也就是别人常说的虚拟内核数。比如单物理核心实现的双线程,它同时可以处理两个线程,它的物理核心数其实是是1个,通过HyperThreading技术实现的线程级并行 (Thread Lever Parallelism)。至于技术细节的实现,这涉及到高速缓存的知识。
Intel的SMT技术是我们认知最广泛的,早在2002年的Pentium 4上(应该是Pentium 4的E)和Xeon上,Intel就把SMT技术包装成Hyper Threading,并推向市场了。之后因为架构切换,在酷睿诞生初期暂停过一段时间,而自从Core i7 960这个划时代的酷睿后,就一直是Intel中高端CPU的标配了。 Intel的超线程一直都是SMT2,也就是一个物理核心虚拟出两个核心,也就是逻辑核心。 AMD最新的Zen系列CPU,也同样加入了SMT2的超线程,现在超线程技术可以说是PC和服务器CPU的标配了。
SMT是在指令级并行的基础上的扩展,可以在一个核上运行多个线程,多个线程共享执行单元,以便提高部件的利用率,提高吞吐量。SMT需要为每个线程单独保持状态,如程序计数器(PC),寄存器堆 ,重排序缓冲等。在一个CPU 的时钟周期 内能够执行来自多个线程的指令的硬件多线程技术 。本质上,同步多线程是一种将线程级并行处理 (多CPU)转化为指令 级并行处理(同一CPU)的方法。 同步多线程是单个物理处理器从多个硬件线程上下文同时分派指令 的能力。
多核心(Multicore) 物理核心数量的提升
多核处理器 (Multicore Processors)
描述 :一个芯片上集成多个核心,每个核心可独立运行一个线程或任务。代表技术 :Intel Core i7、AMD Ryzen。特点:
多个核心共享内存或缓存,提高线程并发能力。
适用于多线程应用和多任务环境。
2005年,英特尔宣布他的第一个双核心 EM64T 处理器,和 Pentium D840(次年发布,双核心双线程,蹩脚双核)
2006年,Core 2(双核心双线程,但不支持HT技术)这大概才算真正意义上单芯片多核心处理器的诞生。(物理双核)
而2006后迎来了Multi-Core Processor多内核处理器时代,而且也伴随着多线程技术.
多处理器系统 (Multi-Processor Systems)
描述 :多个物理 CPU 组成的系统,每个 CPU 拥有自己的内存或共享内存。类型:
SMP(对称多处理) :所有处理器访问共享内存,共享操作系统资源。NUMA(非一致存储访问) :各处理器访问本地内存更快,远程内存访问更慢。
应用场景 :大型服务器、高性能计算集群。
分布式计算 (Distributed Computing)
描述 :任务分布到多个计算节点,每个节点处理部分任务,并通过网络协调结果。典型框架 :Hadoop、Spark、MPI。应用场景 :数据挖掘、大规模仿真建模。
GPU 并行计算 (GPU Parallel Computing)
描述 :利用 GPU 的众多流处理器并行处理大量数据,适合数据密集型任务。特点:
专门用于图形渲染和 AI、机器学习任务。
框架:CUDA(NVIDIA)、OpenCL。
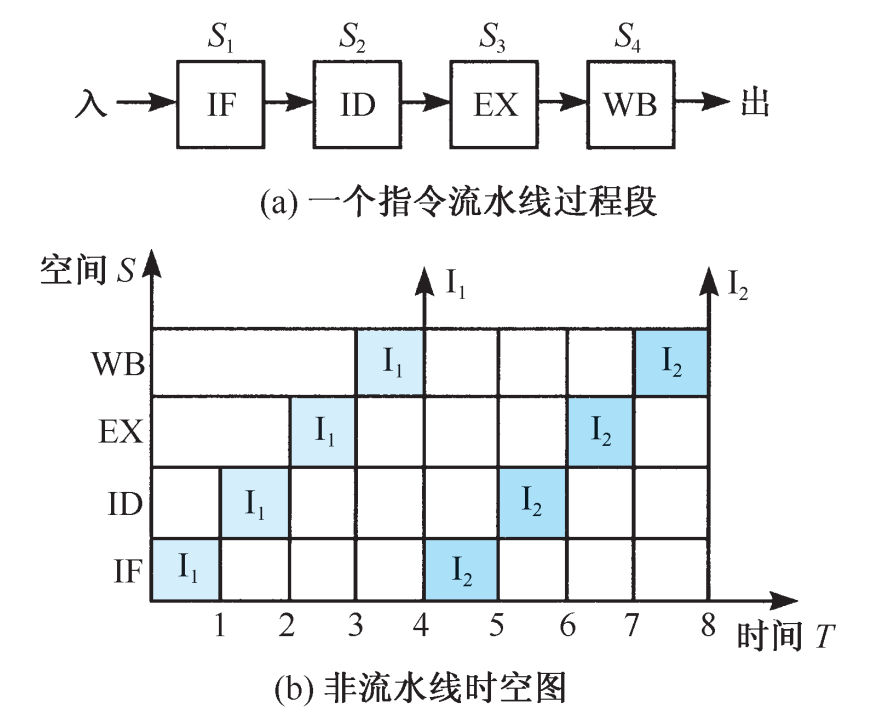
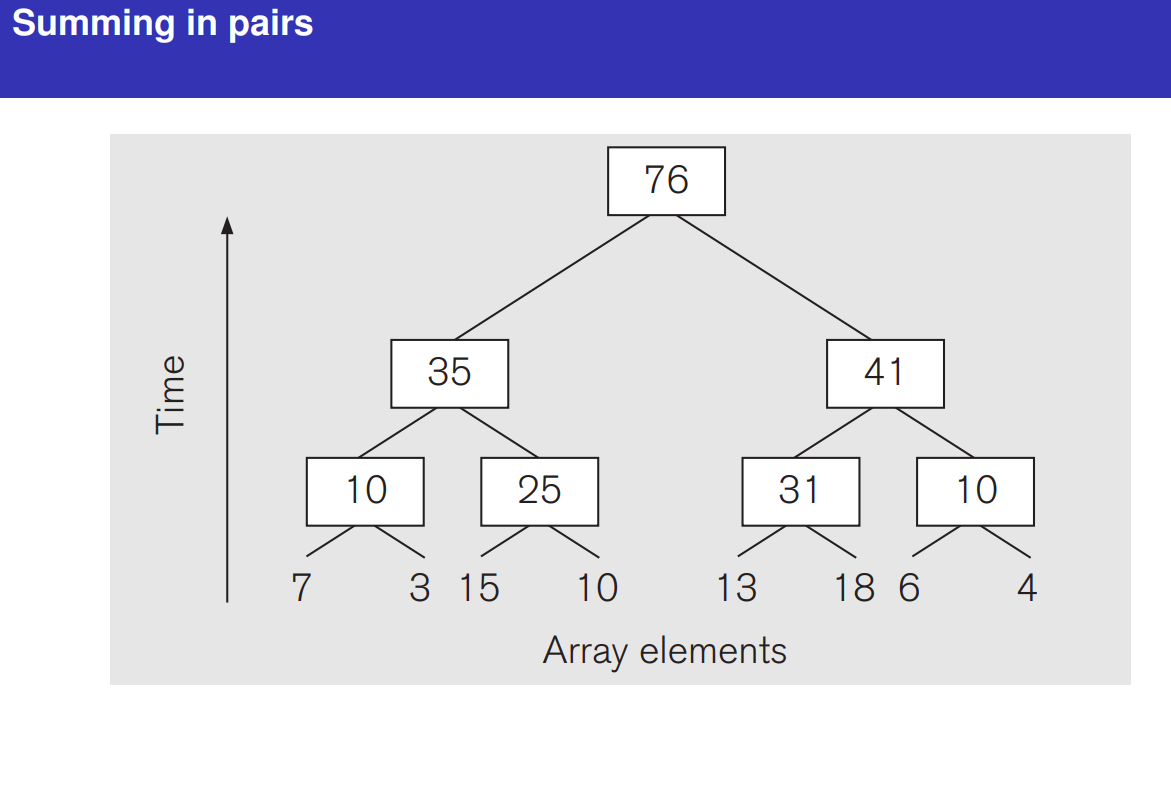
单核实现时间并行(指令流水)在并行性概念中引入时间因素,让多个处理过程在时间上相 互错开,轮流重叠地使用同一套硬件设备的各个部分,以加快硬件周转而赢得速度。 时间并行性概念的实现方式就是采用流水处理部件。这是一种非常经济而实用的并行 技术,能保证计算机系统具有较高的性能价格比。目前的高性能微型机几乎无一例外地使 用了流水技术。将计算机指令 处理过程拆分为多个步骤,并通过多个硬件处理单元并行执行来加快指令执行速度,跟CPU核心数无关。
指令级并行(Instruction-Level Parallelism, ILP) 是指在单个处理器 内部通过同时执行多条指令 来提高程序运行速度的一种技术。它利用程序中指令之间的数据和控制独立性,使多条指令可以并行执行,从而提高性能。ILP 实质上是==时间级并行==的典型代表 :
利用流水线、超标量和乱序执行等技术,在一个核心内并行处理多条指令,但这些指令共享相同的计算资源,只是在不同阶段的时间上交错执行。
它依赖于执行单元复用,而不是多个物理核心并行处理任务。
ILP 的核心思想
并行性基础 :程序中的指令并非严格依赖顺序执行,而是存在某些可以同时执行的指令。
流水线技术 :将指令分解为多个阶段(如取指、译码、执行、访存和写回),使得不同阶段的操作可以同时处理不同指令。
硬件支持 :依赖于高级处理器架构和控制逻辑来检测和管理指令依赖关系。
ILP 的关键技术
指令流水线 (Instruction Pipeline)
将指令分为多个阶段,每个阶段处理一部分操作,类似于生产线作业。
缺点:流水线可能因为数据依赖或控制依赖导致阻塞或停顿(称为流水线冒险)。
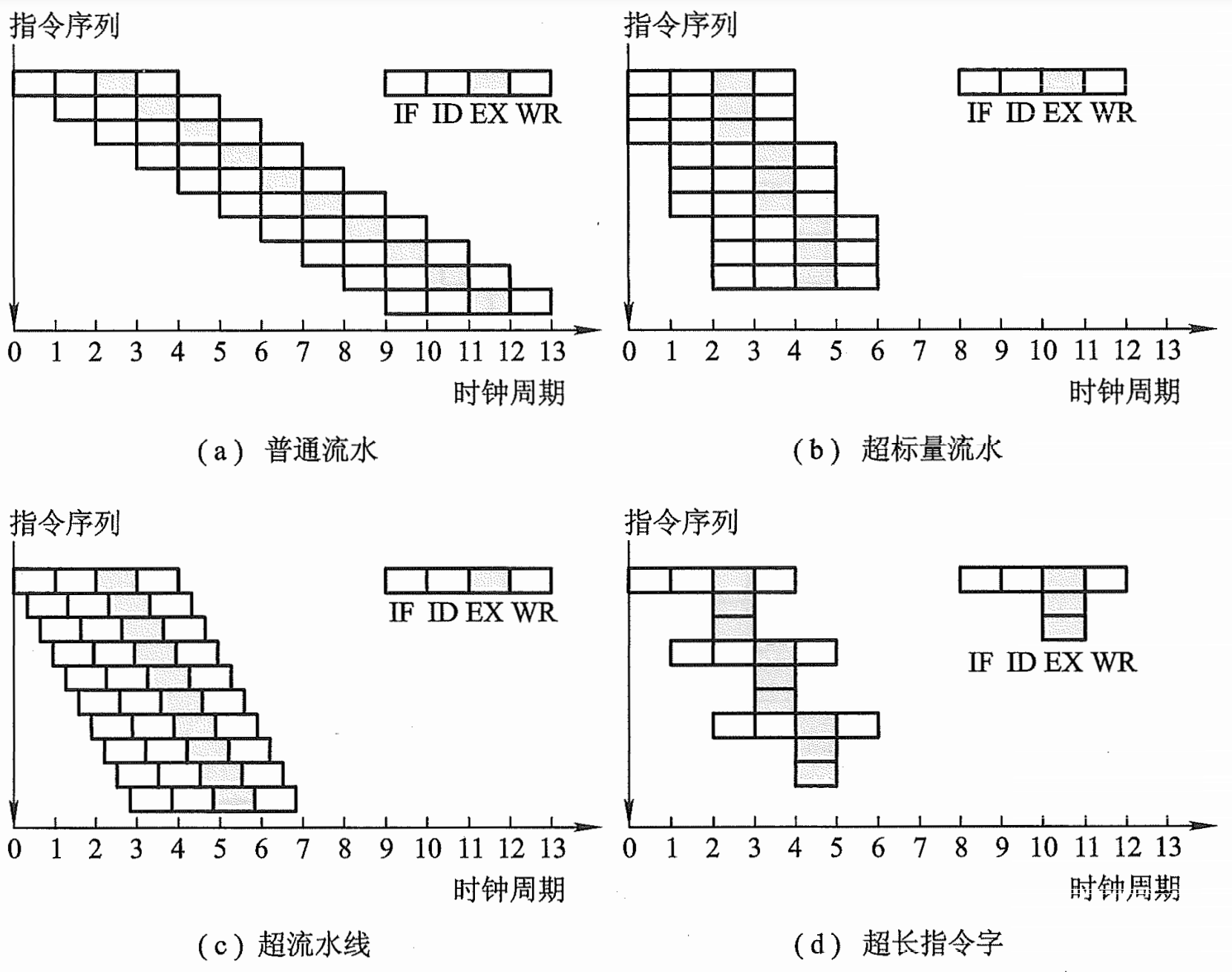
超标量处理 (Superscalar Execution)
在单个周期内执行多条指令,通过多个执行单元实现真正的并行执行。
例如:Intel Pentium 系列采用超标量设计,每周期可执行多条整数和浮点运算指令。
动态调度 (Dynamic Scheduling)
采用硬件动态调整指令顺序,绕过依赖性阻塞,提高指令吞吐量。
典型实现:Tomasulo 算法。
分支预测 (Branch Prediction)
解决控制依赖问题,预测程序分支方向,提前加载和执行指令。
精确的预测减少因分支跳转导致的流水线停顿。
乱序执行 (Out-of-Order Execution)
指令不按照程序编写顺序执行,而是根据依赖分析和资源调度动态调整执行顺序。
硬件负责结果重排序,确保程序语义正确性。
寄存器重命名 (Register Renaming)
通过给物理寄存器重新分配逻辑名称,避免写后读 (WAR) 和写后写 (WAW) 依赖冲突。
ILP 的依赖分析
数据依赖 :
**真实依赖 (RAW, Read After Write)**:指令需要前一指令的结果。
**反依赖 (WAR, Write After Read)**:后续指令会覆盖前面指令所需数据。
**输出依赖 (WAW, Write After Write)**:两个指令尝试写入同一位置。
控制依赖 :
指令执行取决于程序分支跳转结果,导致流水线停顿。
ILP 的局限性
数据依赖的限制 :高度依赖指令本身的数据流特性,若指令相关性强,则并行度受限。控制流的限制 :分支预测失败会导致流水线清空和指令重启,降低性能。硬件复杂度 :超标量、乱序执行和动态调度需要大量硬件资源,功耗和成本较高。内存访问瓶颈 :指令并行执行过程中,内存访问速度可能无法满足需求。
内存级并行 (英语:Memory-level parallelism,缩写为 MLP’),并行计算 技术的一种,是计算机体系结构的一种,能够同时进行数个存储器操作,特别是在缓存 未命中(cache miss),或转译后备缓冲器 未命中(TLB miss)时。
在宏内核处理器架构下,内存级并行可以被视为是一种特殊的指令层级平行 (ILP)。它也经常在超标量 架构下出现。
数据级并行 DLP(SIMD) Flynn将计算机分为四类:
SISD:单条指令操作一条数据,例如之前介绍的简单流水线
MISD:多条指令操作一条数据,很少
MIMD:多条指令操作多条数据,例如VLIW
SIMD:单条指令操作多条数据, 例如Vector Processor,GPU
数据级并行就是指的SIMD,SIMD可以分为array processor和vector processor,array processor由多种ALU组成,成本更高,同一个时间可以有多个数据执行相同操作,vector processor每种硬件单元只有一个,同一个时间不同数据无法执行相同操作。
大型机多用于进行科学计算,为了更快的处理数据,它们使用了更多的寄存器,这样可以同时可以处理更多的操作数。单一指令运行多个操作数 并行计算 。这里涉及到操作数的概念,如果你有汇编的基础应该会很好理解。我们考虑下面这个计算式子:(a+b)*(c+d),该计算过程被分解为三步:
1 2 3 1. e = a + b 2. f = c + d 3. m = e * f
早期的计算机一次只能处理一条指令,它要先算步骤1(加法操作),再算步骤2(加法操作),最后算3(乘法操作 )。需要三步(花费三个指令)得到答案。
但是我们观察到:3的结果依赖于1和2,而1和2都单纯的加法操作,所以开始想办法让1和2同时计算,那么CPU只要两步得到答案,步骤1和2一次算出来的结果,直接进行乘法运算 。
它运用了SIMD(Single -Instruction ,Multple -Data)单指令多数据流技术。一个指令执行了(a,b,c,d) 4个操作数。SIMD指令集可以提供更快的图像,声音,视频数据等运行速度。
发展 单核编程 :一开始是单核编程,优化算法也是在单核的基础上优化,为了更好的兼容性,发掘单核潜力
多核编程 :
摩尔定律,晶体管增长遥遥领先于指令执行。
能量消耗的问题,速度快了,能量消耗指数级上升,发热严重,影响计算速度,所以要进行散热,受制于经济原因,单核提升不上去
线路延迟问题,指令周期呈现缩短趋势,布线范围也呈缩短趋势,算得快但是来不及拿数,数据传递不过来,DRAM访问延迟,CPU 增长快于内存,一样的道理,拿不上数
收益递减diminishing returns:cpu性能提升难度陡增80s 流水线 90s 收益低于预期 00s 并行传输
一个任务一个核,任务不够核消费,单个任务会有各种中断,不能有效利用核
并行理论基础 串行需要依赖,并行步骤之间不能有依赖,并行也分步骤,但是每一步的不同计算不能互相影响
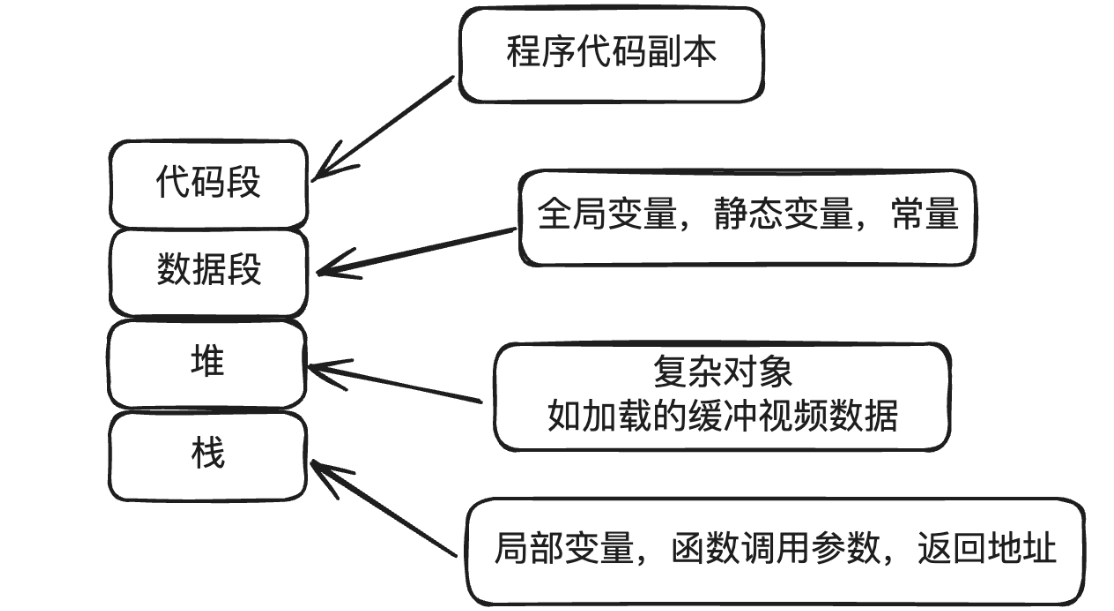
Thread 线程 并行最小单位 Parallel Unit
拥有自己的上下文
拥有调用堆栈
有PC
但是内存和同一个进程的其他线程共享(SHARED),发生竞态条件(RACE CONDITION)
众所周知,CPU、内存、I/O 设备的速度是有极大差异的,为了合理利用 CPU 的高性能,平衡这三者的速度差异,计算机体系结构、操作系统、编译程序都做出了贡献,主要体现为:
CPU 增加了缓存,以均衡与内存的速度差异;// 导致 可见性问题
操作系统增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异;// 导致 原子性问题
编译程序优化指令执行次序,使得缓存能够得到更加合理地利用。// 导致 有序性问题
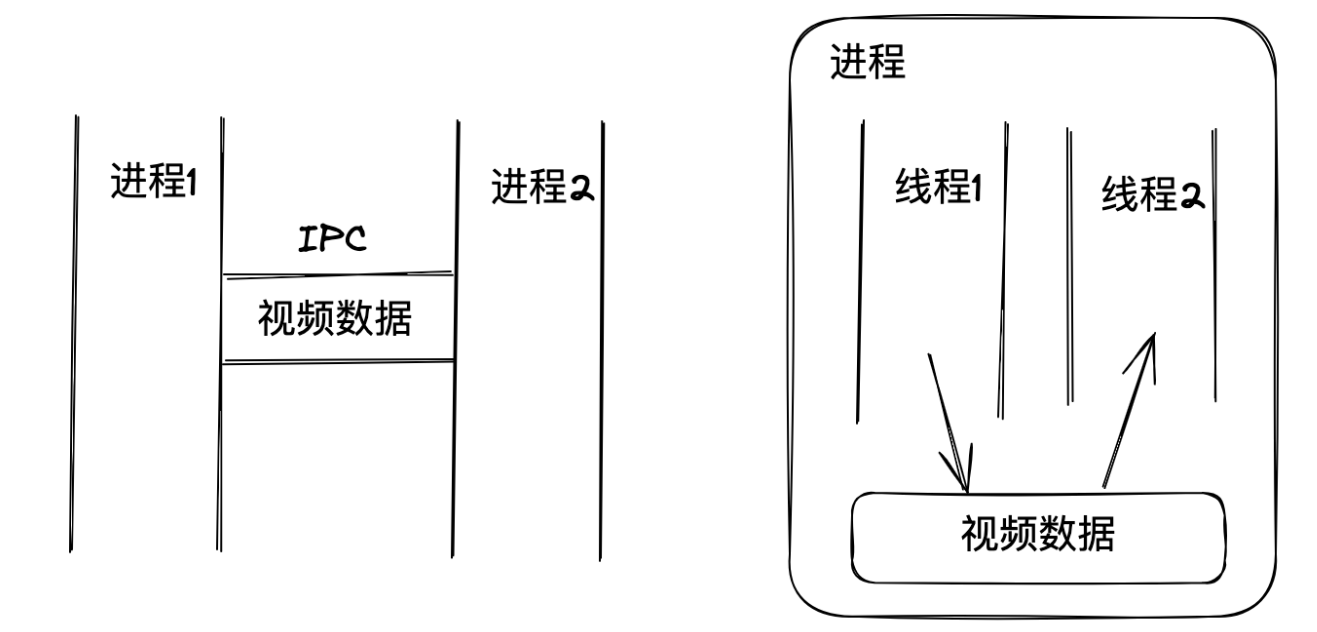
Process 进程 进程就是程序的实例(就像面向对象编程中的类,类是静态的,只有实例化后才运行,且同一个类可以有多个实例)比如,你可以一边播放视频,一边编辑文档,每个程序都有自己的进程,互不干扰。即使它们都是同一份代码,但各自播放的内容和进度都可以不同。
进程(可以看成只有一个线程的进程)同时只能做一件事,如果将一个进程分成多个线程,这样就不会浪费时间空等了
进程间是完全独立的,互不干扰。而线程则共享同一个进程的资源,所以线程间交换数据更方便,几乎没有通讯损耗。
但进程间交换数据就麻烦多了,得通过一些通讯机制,比如管道、消息队列之类的(Inter-process Communication)
需要注意的是,线程各自拥有各自的栈
Coroutine 协程 线程在执行加载视频片段时,必须等待结果返回才能再次执行解码操作,如果引入多线程:加载本身是IO行为,CPU在等待结果返回期间几乎是在空等,浪费了CPU资源。当然,你可以让它休眠以释放 CPU 时间,但创建线程本身就有开销,线程切换同样有开销。
相比之下,协程(Coroutine)非常轻量,创建和切换的开销极小——它并非操作系统层面的东西,就不涉及内核调度。一般是由编程语言来实现(比如 Python 的 asyncio 标准库),它属于用户态的东西。
资源共享问题:线程的执行时机由操作系统调度,程序员无法控制,这正是多线程容易出现资源覆盖的主要原因。而协程的执行时机由程序自身控制,不受操作系统调度影响,因此可以完全避免这类问题。同一个线程内的多个协程共享同一个线程的 CPU 时间片资源,它们在 CPU 上的执行是有先后顺序的,不能并行执行。而线程是可以并行执行的
协程(coroutine),其实是一种特殊的子程序(subroutine,比如普通函数)。普通函数一旦执行就会从头到尾运行,然后返回结果,中间不会暂停。而协程则可以在执行到一半时暂停。利用这一特性,我们可以在遇到 I/O 这类不消耗 CPU 资源的操作时,将其挂起,继续执行其他计算任务,充分利用 CPU 资源。等 I/O 操作结果返回时,再恢复执行。在一个线程内并发执行多个任务
Mutex 互斥锁 案例:计算数组中3的个数。考虑将数组分成多个部分,每个部分由一个线程负责。
V1 线程不安全
1 2 3 4 5 6 7 8 void count3s_thread (int id) { int length_per_thread = length / t; int start = id * length_per_thread; for (i = start; i < start + length_per_thread; i++) { if (array [i] == 3 ) count++; } }
V2 线程安全
1 2 3 4 5 6 7 8 9 10 11 12 mutex m; void count3s_thread (int id) int length_per_thread = length / t; int start = id * length_per_thread; for (i = start; i < start + length_per_thread; i++) { if (array[i] == 3 ) { mutex_lock (m); count++; mutex_unlock (m); } } }
V3 减少加锁次数 优化性能
1 2 3 4 5 6 7 8 9 10 11 12 13 private_count[MaxThreads]; mutex x; void count3s_thread (int id) int length_per_thread = length / t; int start = id * length_per_thread; for (i = start; i < start + length_per_thread; i++) { if (array[i] == 3 ) private_count[id]++; } mutex_lock (m); count += private_count[id]; mutex_unlock (m); }
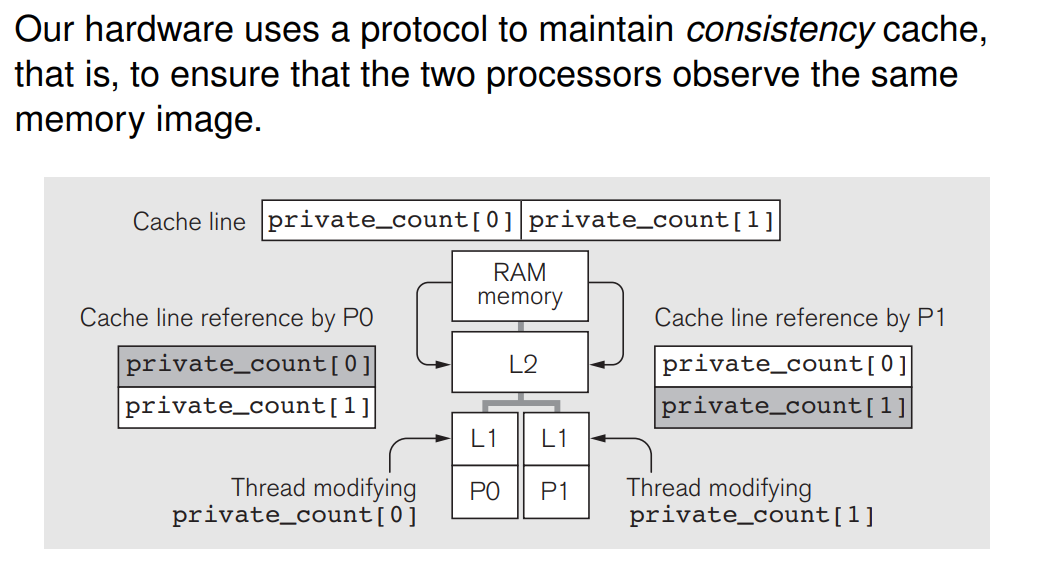
V4 针对硬件结构进行优化 避免伪共享
在多线程程序中,如果不同线程访问的变量在同一个缓存行中,而其中一个线程修改了它所在缓存行的某个变量,其他线程即使访问不同的变量,也会因为缓存一致性协议(如 MESI 协议)而导致缓存失效,迫使这些线程频繁地从内存(RAM)中重新加载数据。
在大多数现代 CPU 上,一个缓存行通常是 64 字节。如果 private_count 数组的每个元素占用的空间小于 64 字节(例如一个 int 通常为 4 字节),多个 private_count 元素会共享同一个缓存行。这样一来,即使线程各自访问不同的 private_count 元素,它们的读写操作也会相互干扰。
细说Cache-L1/L2/L3/TLB - 知乎 (zhihu.com)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 struct padded_int { int value; char padding[60 ]; }private_count[MaxThreads]; void count3s_thread (int id) int length_per_thread = length / t; int start = id * length_per_thread; for (i = start; i < start + length_per_thread; i++) { if (array[i] == 3 ) { private_count[id]++; } } mutex_lock (m); count += private_count[id].value; mutex_unlock (m); }
MESI 协议简介
在 MESI 协议中,每个缓存行可以有以下四种状态:
Modified(M) :缓存行被当前处理器独占,并且内容已被修改,与主存不同步。Exclusive(E) :缓存行被当前处理器独占,且内容与主存同步。Shared(S) :缓存行在多个处理器的缓存中都有副本,且与主存同步。Invalid(I) :缓存行无效,即该缓存行内容与主存不同步,不能使用。
判断缓存失效的机制
缓存失效通常是通过监听总线上的操作 来判断的。每个核心的缓存控制器都会监视其他核心发出的读写请求,这样它可以判断自己是否需要使某个缓存行失效。具体流程如下:
读操作 :当一个处理器读取一个缓存行时,如果其他处理器的缓存中有该缓存行的修改版(Modified 状态),它会通知主存和其他缓存进行更新,使这个缓存行失效或进入共享状态。
写操作(写失效) :当一个处理器要写入一个缓存行时,如果其他缓存有该缓存行的副本(处于 Shared 或 Exclusive 状态),它们会收到写入请求并将该缓存行标记为无效(Invalid)。这称为写失效 。
广播和探测 :在缓存一致性协议中,当处理器对缓存行进行操作(如写操作)时,处理器会向其他核心或处理器发出广播 或探测 信号,要求其他缓存检查是否有该缓存行的副本。如果存在副本,这些副本会被标记为无效。
缓存失效的例子(基于 MESI 协议)
假设处理器 P0 和 P1 都在各自的缓存中存有某个变量 x,且 x 的初始值为 0。以下是一个缓存失效的示例过程:
步骤 1 :P0 读取 x,此时 x 在 P0 的缓存中处于 Shared 状态。步骤 2 :P1 也读取 x,此时 x 在 P0 和 P1 的缓存中都是 Shared 状态。步骤 3 :P0 对 x 进行写操作,将 x 修改为 1。
P0 的缓存控制器会通知 P1 的缓存,将 x 在 P1 的缓存中标记为 Invalid。
P0 中的 x 变为 Modified 状态,与主存不同步。
步骤 4 :当 P1 再次尝试读取 x 时,发现该缓存行是无效的(Invalid 状态),因此会触发一次从主存或 P0 缓存中的更新操作来同步数据。
硬件实现的细节
总线监听(Bus Snooping) :每个缓存控制器通过监听总线上其他处理器的内存访问请求来判断是否需要使缓存行失效。如果其他处理器发出了对自己缓存行的写请求,那么本地的缓存行会被标记为无效。目录协议(Directory-Based Protocol) :在一些系统中,每个内存块的状态由一个中央目录来管理。目录保存了该内存块在哪些缓存中有副本,哪个处理器在修改状态。当某个处理器要写数据时,目录会通知所有拥有该缓存行的处理器将其标记为无效。
在伪共享中,不同线程访问不同变量,但这些变量在同一个缓存行中。当一个线程修改了它的变量,其他线程的缓存行会被标记为无效,迫使它们重新从内存中加载。这是因为缓存行是最小的一致性单位,即使只修改缓存行中的一个字节,整个缓存行都需要保持一致。
总结
缓存失效的判断是通过缓存一致性协议 和硬件监听机制 实现的。当一个缓存行被修改时,其他缓存中的相同缓存行会被标记为无效,从而保证所有处理器访问同一内存地址时的一致性。
C++ 并行编程 HelloWorld:
1 2 3 4 5 6 7 8 9 10 11 12 #include <thread> #include <iostream> void func () { std ::cout << "**Inside thread " << std ::this_thread::get_id() << "!" << std ::endl ; } int main () { std ::thread t ( func ) ; t.join(); return 0 ; }
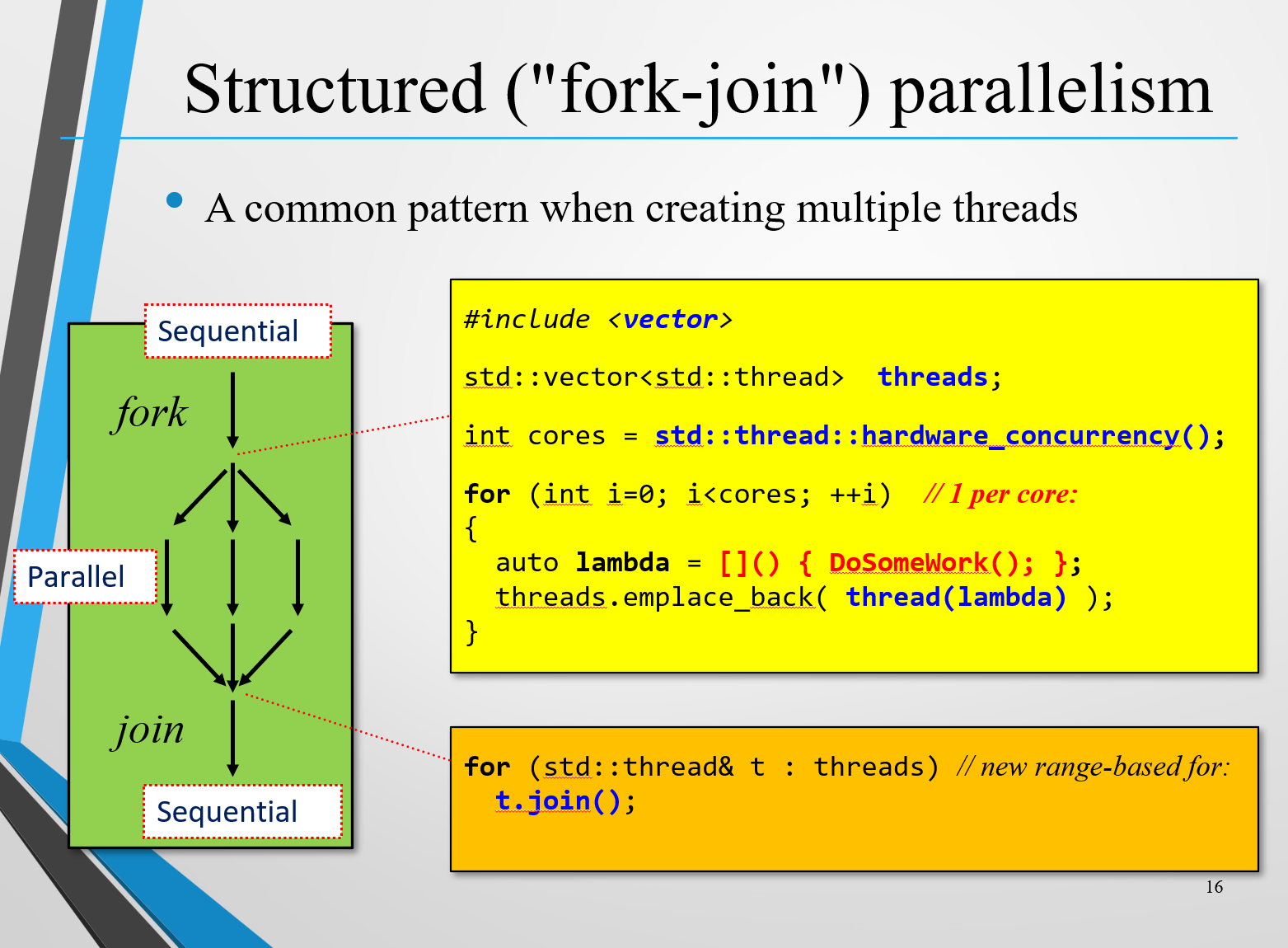
结构化并行编程 fork-join
不能一创建子线程就join(),join的意思是让主线程等子线程执行完再继续,所以循环体内join就会阻塞其他子线程的创建,变成事实上的串行程序。因此应该全部创建完子线程后以后再统一join(),
常见错误
不能让线程直接赋值,而是要用std::move(t)将t的上下文等信息转移到t2,然后t就变成了一个空壳,
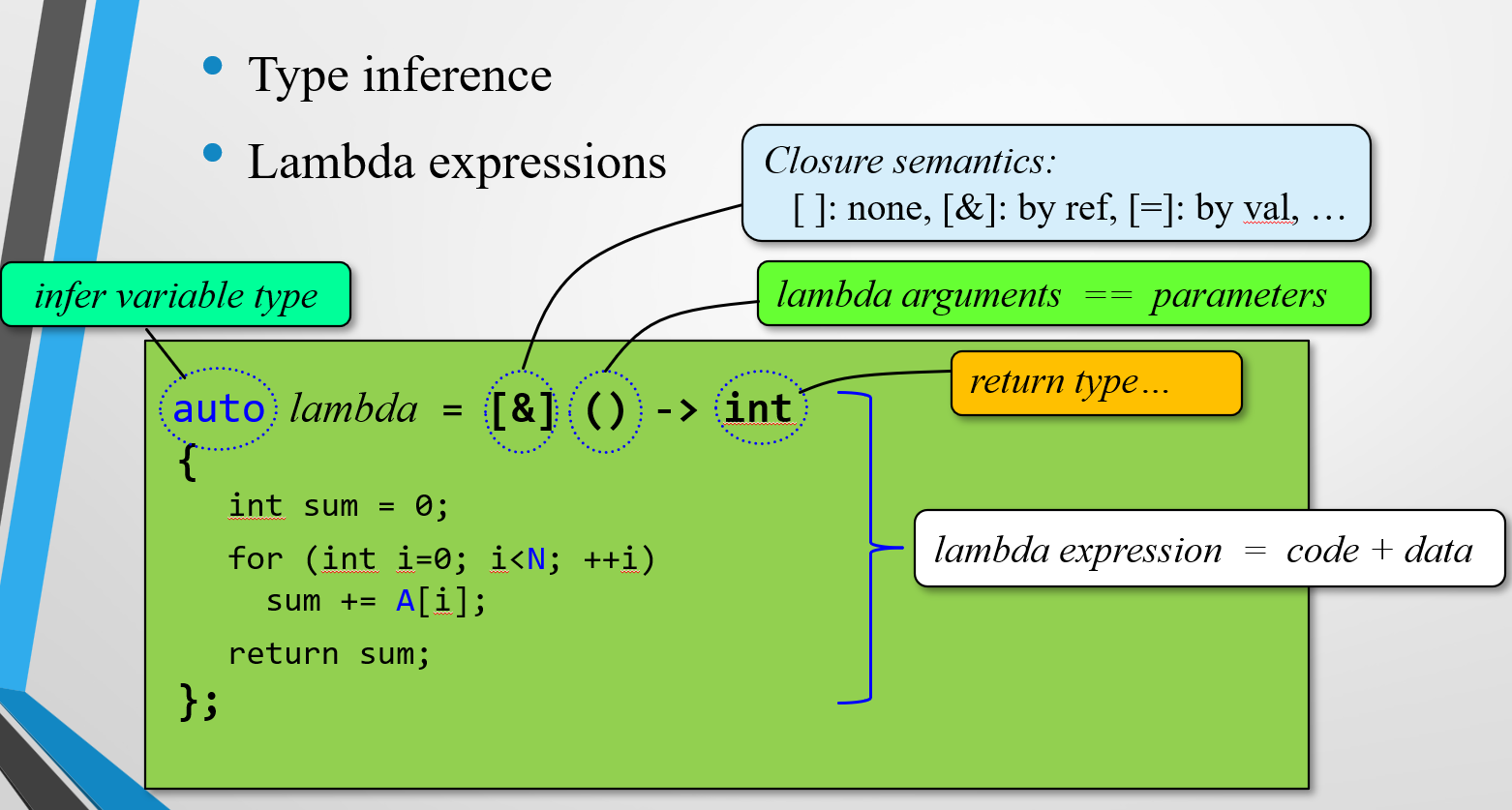
Lambda表达式
[]代表不传任何值[&]代表把在进程内部但在函数外部的变量以引用的形式传递进去[=]代表把上述变量以值传递的形式传过去(传递副本)
()表示参数,{}表示函数体
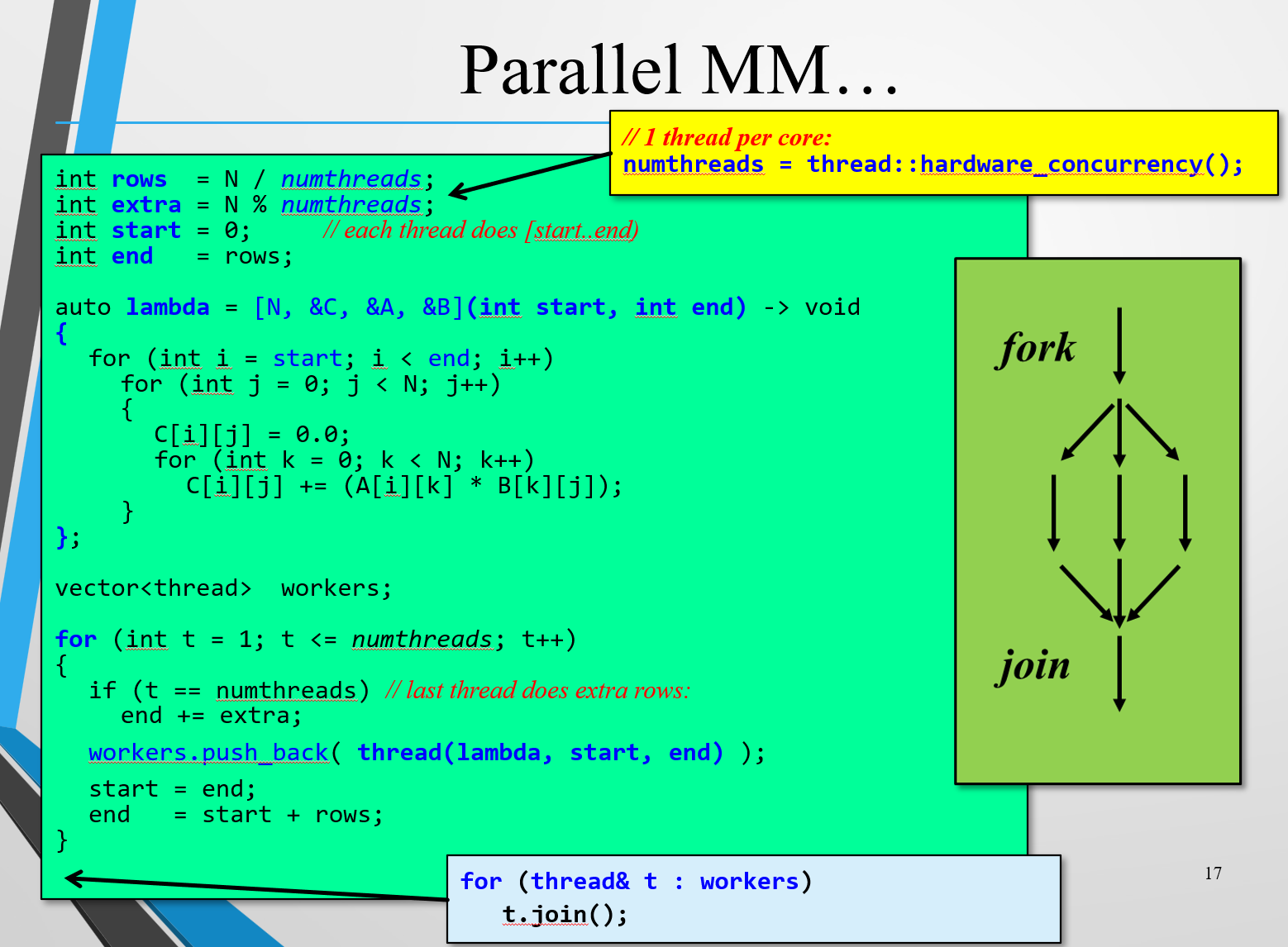
案例:矩阵乘法
C[i][j] 就是矩阵A的第i行和矩阵B的第j行的每一个数据相乘的和
$C_{i,j}=\sum_{k=0}^N A_{i,k}B_{k,j}$
并行版本:把总的任务拆分开。
优化:
数据结构、算法与应用 C++语言描述(原书第2版):第4章 性能测量 P88 矩阵乘法
一个循环体内部只对C[i][j]做一次赋值操作
优化嵌套的顺序:一共需要进行$N^3$次乘法,A[i][k] B[k][j] C[i][j]的元素都变成按行访问,有效利用了cache空间(因为同行的元素在内存中相邻,而同列的元素不是,如果数组长度过长,导致同列的元素无法同时存储在L2缓存中,使得缓存未命中必须从RAM中取,大大降低了效率)
高速缓存与矩阵乘法(一)_矩阵乘法cache-CSDN博客
高速缓存与矩阵乘法(二)_矩阵乘法的瓶颈-CSDN博客
高速缓存与矩阵乘法(三)_clapack用法-CSDN博客
其他并发库 Future Async 更舒适的开启线程方式
async能实现异步开启一个线程的功能,并返回future,future最重要的是能够直接拿到返回值
Mutex 解决RA
竞态条件(Race Condition):
操作同一变量导致了竞态条件的发生,从上到下性能依次降低
redesign to eliminate (e.g. reduction) 重新设计程序,尽量减少共享变量的次数use thread-safe entities (e.g. parallel collections) 比如java中的concurrentHashMap,比如原子变量(乐观锁)use synchronization (e.g. locking) 实在没办法只能加锁
因此要定义针对共享代码块的锁,也就是互斥锁Mutex
Mutex :
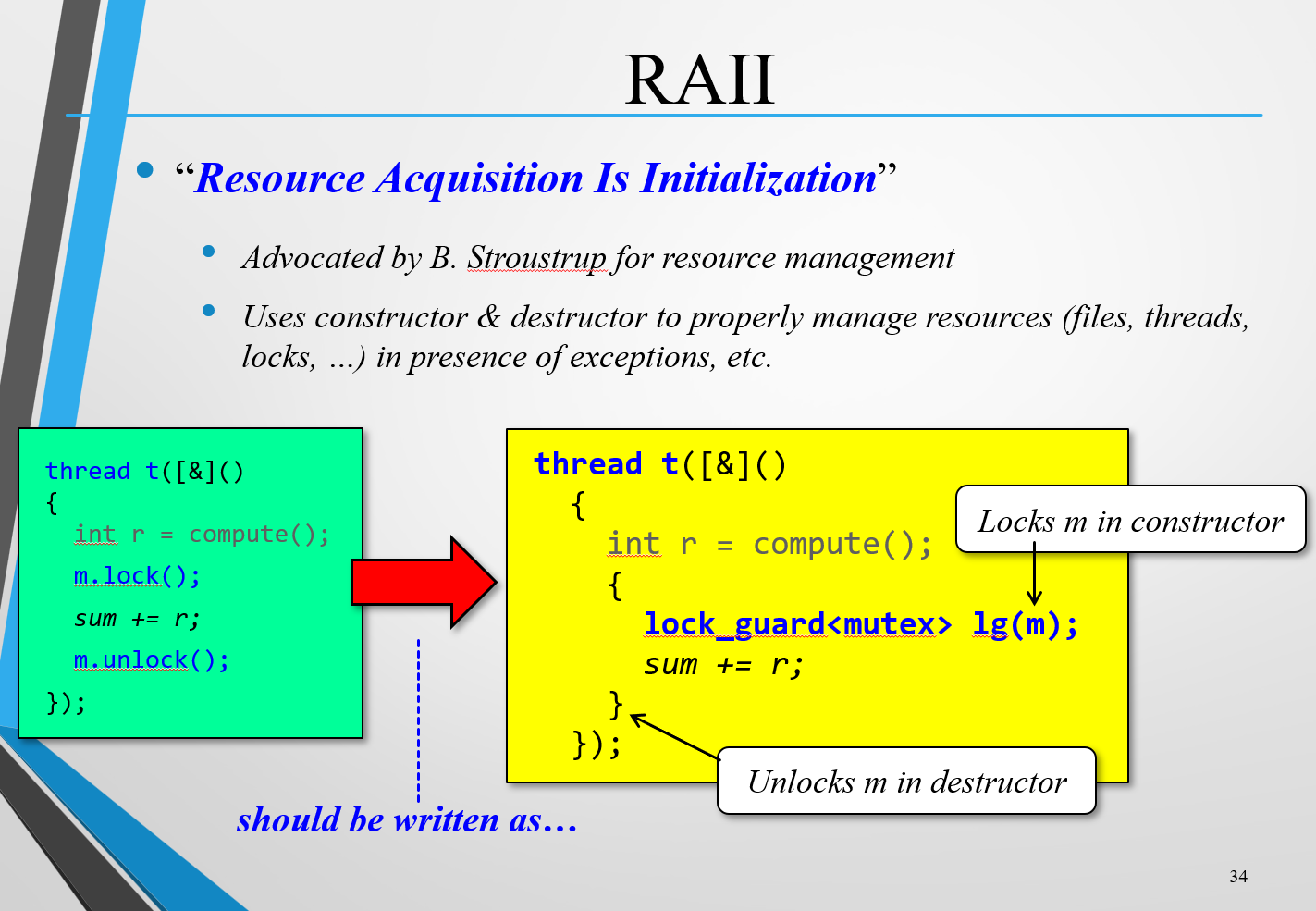
Lock Guard :
直接使用mutex的加解锁,如果中间代码出现异常,就会出现死锁,那么显然就不能简单粗暴地直接调用锁。
Java中的锁监视器(Monitor)和 lock_guard 确实有相似之处。它们都是用来管理资源的互斥访问,确保线程安全。lock_guard 是 C++ 中的一种 RAII 风格的锁实现,它在构造时加锁,在析构时自动解锁。锁监视器则是一个对象,包含加锁和解锁操作,通常通过 synchronized 关键字来实现。两者的核心思想都是在临界区自动管理锁的生命周期,避免死锁。
Atomic :
原子变量 只支持自增
将共享的变量去除,直接拿到异步future的返回值相加,完全避免了RA
并行算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <iostream> #include <vector> #include <thread> #include <algorithm> #include <random> using namespace std;void parallelSort (vector<int >& arr) int n = arr.size (); int rounds = log2 (n); auto compareAndSwap = [&](int start,int step) { for (int i = start; i < n; i += 2 * step) { if (arr[i] < arr[i + step]) { swap (arr[i], arr[i + step]); } } }; for (int r = 0 ; r < rounds; ++r) { int step = 1 << r; int threadsCount = n / (2 * step); vector<thread> threads; for (int t = 0 ; t < threadsCount; ++t) { threads.emplace_back (compareAndSwap, t * 2 * step, step); } for (auto & t : threads) { t.join (); } } }
Bitonic Sort 双调排序(Bitonic Sort)是一种并行排序算法,特别适用于多处理器系统。它通过递归方式构造双调序列(bitonic sequence),然后使用双调合并(bitonic merge)将其排序。以下是用C++和多线程实现双调排序的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <cuda_runtime.h> #include <iostream> #include <vector> __global__ void bitonicSortKernel (int * d_arr, int n, int stage, int step) { unsigned int idx = threadIdx.x + blockIdx.x * blockDim.x; unsigned int pairIdx = idx ^ step; if (pairIdx > idx && pairIdx < n) { bool ascending = ((idx & stage) == 0 ); if ((d_arr[idx] > d_arr[pairIdx]) == ascending) { int temp = d_arr[idx]; d_arr[idx] = d_arr[pairIdx]; d_arr[pairIdx] = temp; } } } void bitonicSortCUDA (std::vector<int >& arr) int n = arr.size (); if ((n & (n - 1 )) != 0 ) { throw std::runtime_error ("Array size must be a power of 2." ); } int * d_arr; cudaMalloc ((void **)&d_arr, n * sizeof (int )); cudaMemcpy (d_arr, arr.data (), n * sizeof (int ), cudaMemcpyHostToDevice); int threadsPerBlock = 256 ; int blocksPerGrid = (n + threadsPerBlock - 1 ) / threadsPerBlock; for (int stage = 2 ; stage <= n; stage *= 2 ) { for (int step = stage / 2 ; step > 0 ; step /= 2 ) { bitonicSortKernel<<<blocksPerGrid, threadsPerBlock>>>(d_arr, n, stage, step); cudaDeviceSynchronize (); } } cudaMemcpy (arr.data (), d_arr, n * sizeof (int ), cudaMemcpyDeviceToHost); cudaFree (d_arr); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 int main () std::vector<int > arr = {19 , 7 , 5 , 3 , 17 , 13 , 11 , 2 , 1 , 9 , 4 , 8 , 6 , 12 , 10 , 14 }; std::cout << "Original array: " ; for (int num : arr) { std::cout << num << " " ; } std::cout << std::endl; try { bitonicSortCUDA (arr); } catch (const std::exception& e) { std::cerr << e.what () << std::endl; return 1 ; } std::cout << "Sorted array: " ; for (int num : arr) { std::cout << num << " " ; } std::cout << std::endl; return 0 ; }
bitonicMerge
负责将双调序列合并为一个有序序列。
使用 low 和 count 参数确定操作范围,并通过 ascending 决定升序或降序。
bitonicSort
构造双调序列并调用 bitonicMerge 完成排序。
parallelBitonicSort
通过多线程加速排序过程。
根据线程数分配工作,递归调用 parallelBitonicSort。
main
验证数组大小为 2 的幂。
使用多线程完成排序,并输出结果。
输入数组大小必须是 2 的幂。如果不是,可以填充为下一个最近的 2 的幂。
适当调整线程数量,以避免因过多线程导致上下文切换开销。
std::thread::hardware_concurrency() 获取系统支持的最大线程数。
运行结果会显示原始数组和排序后的数组,从而验证算法正确性和并行效果。
Odd-Even Sort 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include "cuda_runtime.h" #include "device_launch_parameters.h" #include <stdio.h> #define BLOCK_SIZE 1024 __global__ void odd_even_sort_step (int * data, int size, int phase) { unsigned int i = threadIdx.x + blockIdx.x * blockDim.x; unsigned int index = 2 * i + (phase % 2 ); if (index < size - 1 ) { if (data[index] > data[index + 1 ]) { int temp = data[index]; data[index] = data[index + 1 ]; data[index + 1 ] = temp; } } } void odd_even_sort (int * data, int size) { int * d_data; cudaMalloc((void **)&d_data, size * sizeof (int )); cudaMemcpy(d_data, data, size * sizeof (int ), cudaMemcpyHostToDevice); int threads_per_block = BLOCK_SIZE / 2 ; int num_blocks = (size / 2 + threads_per_block - 1 ) / threads_per_block; for (int phase = 0 ; phase < size; phase++) { odd_even_sort_step << <num_blocks, threads_per_block >> > (d_data, size, phase); cudaDeviceSynchronize(); } cudaMemcpy(data, d_data, size * sizeof (int ), cudaMemcpyDeviceToHost); cudaFree(d_data); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <stdio.h> #include <cuda_runtime.h> __global__ void oddEvenSortKernel (int *arr, int n, int phase) { int index = threadIdx.x + blockIdx.x * blockDim.x; if (phase % 2 == 0 ) { if (index % 2 == 0 && index < n - 1 ) { if (arr[index] > arr[index + 1 ]) { int temp = arr[index]; arr[index] = arr[index + 1 ]; arr[index + 1 ] = temp; } } } else { if (index % 2 == 1 && index < n - 1 ) { if (arr[index] > arr[index + 1 ]) { int temp = arr[index]; arr[index] = arr[index + 1 ]; arr[index + 1 ] = temp; } } } } int main () { const int numElements = 1024 ; int h_input[numElements]; int *d_input; for (int i = 0 ; i < numElements; i++) { h_input[i] = rand() % 1000 ; } cudaMalloc((void **)&d_input, numElements * sizeof (int )); cudaMemcpy(d_input, h_input, numElements * sizeof (int ), cudaMemcpyHostToDevice); int blockSize = 512 ; int numBlocks = (numElements + blockSize - 1 ) / blockSize; for (int phase = 0 ; phase < numElements; phase++) { oddEvenSortKernel<<<numBlocks, blockSize>>>(d_input, numElements, phase); cudaDeviceSynchronize(); } cudaMemcpy(h_input, d_input, numElements * sizeof (int ), cudaMemcpyDeviceToHost); for (int i = 0 ; i < numElements; i++) { printf ("%d " , h_input[i]); } printf ("\n" ); cudaFree(d_input); return 0 ; }
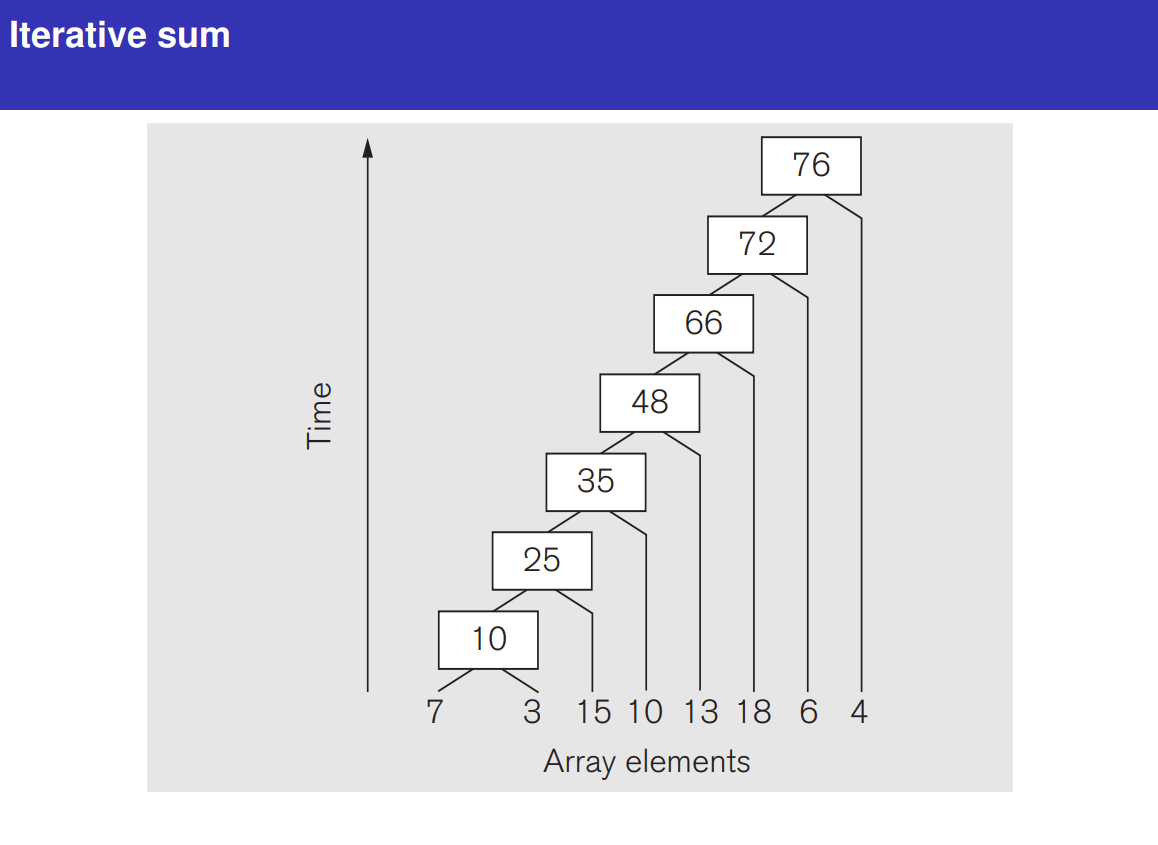
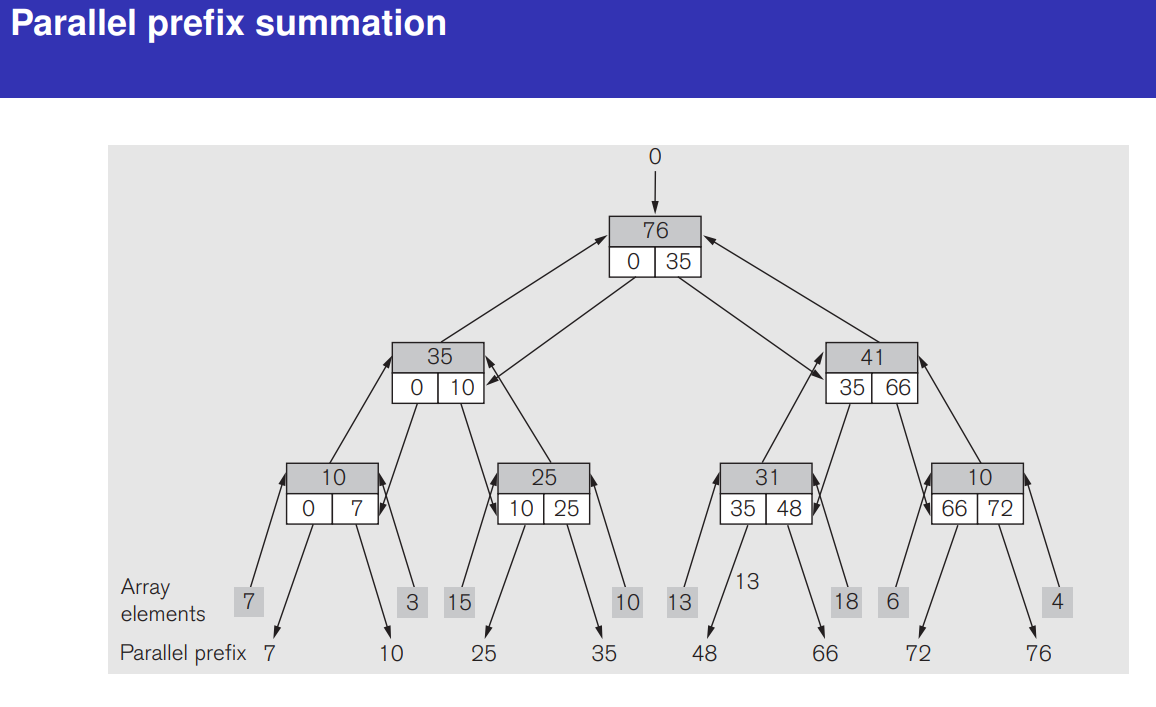
Prefix Sum 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 #include <iostream> #include <vector> #include <thread> #include <functional> #include <mutex> void parallel_prefix_sum () const int k = 3 ; const int n = 1 << k; std::vector<int > elements = {7 , 3 , 15 , 10 , 13 , 18 , 6 , 4 }; std::vector<int > tree_top (2 * n, 0 ) , tree_left (n, 0 ) ; std::copy (elements.begin (), elements.end (), tree_top.begin () + n); auto reduce_layer = [&](int i) { int layer_size = 1 << (k - i - 1 ); for (int j = 0 ; j < layer_size; ++j) { int idx = (1 << (k - i - 1 )) + j; tree_top[idx] = tree_top[2 * idx] + tree_top[2 * idx + 1 ]; } }; auto expand_layer = [&](int i) { int layer_size = 1 << i; for (int j = 0 ; j < layer_size; ++j) { int idx = (1 << i) + j; if (idx % 2 == 0 ) { tree_left[idx] = tree_left[idx / 2 ]; } else { tree_left[idx] = tree_left[idx / 2 ] + tree_top[idx - 1 ]; } } }; for (int i = 0 ; i < k; ++i) { int thread_count = 1 << (k - i - 1 ); std::vector<std::thread> threads; for (int j = 0 ; j < thread_count; ++j) { threads.emplace_back (reduce_layer, i); } for (auto &t : threads) t.join (); } tree_left[0 ] = 0 ; for (int i = 0 ; i < k; ++i) { int thread_count = 1 << i; std::vector<std::thread> threads; for (int j = 0 ; j < thread_count; ++j) { threads.emplace_back (expand_layer, i); } for (auto &t : threads) t.join (); } }
归约阶段 :
利用线程池对每一层的节点进行并行处理。
reduce_layer 是一个 lambda 函数,用于计算每一层的节点累积值。
扩展阶段 :
同样使用线程池完成每一层的前缀和传播。
expand_layer 是一个 lambda 函数,计算每个节点的前缀和。
线程池管理 :
每层节点的数量决定了需要启动的线程数。
std::thread 管理每个线程,join 确保主线程等待所有子线程完成。
Max Subsequence Sum 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 #include <stdio.h> #include <cuda_runtime.h> __global__ void maxSubarraySumKernel (int *arr, int *result, int n) { extern __shared__ int sharedData[]; int tid = threadIdx.x; int start = blockIdx.x * blockDim.x + threadIdx.x; if (start < n) { sharedData[tid] = arr[start]; } else { sharedData[tid] = 0 ; } __syncthreads(); for (int stride = 1 ; stride <= blockDim.x / 2 ; stride *= 2 ) { if (tid % (2 * stride) == 0 && tid + stride < blockDim.x) { sharedData[tid] += sharedData[tid + stride]; } __syncthreads(); } if (tid == 0 ) { result[blockIdx.x] = sharedData[0 ]; } } int main () { const int numElements = 1024 ; int h_input[numElements]; int *d_input, *d_result; int h_result[32 ]; for (int i = 0 ; i < numElements; i++) { h_input[i] = rand() % 100 - 50 ; } cudaMalloc((void **)&d_input, numElements * sizeof (int )); cudaMalloc((void **)&d_result, 32 * sizeof (int )); cudaMemcpy(d_input, h_input, numElements * sizeof (int ), cudaMemcpyHostToDevice); maxSubarraySumKernel<<<32 , 32 , 32 * sizeof (int )>>>(d_input, d_result, numElements); cudaMemcpy(h_result, d_result, 32 * sizeof (int ), cudaMemcpyDeviceToHost); int maxSum = h_result[0 ]; for (int i = 1 ; i < 32 ; i++) { if (h_result[i] > maxSum) { maxSum = h_result[i]; } } printf ("最大子段和: %d\n" , maxSum); cudaFree(d_input); cudaFree(d_result); return 0 ; }
Merge Sort 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 #include <stdio.h> #include <cuda_runtime.h> __device__ void merge (int *arr, int left, int mid, int right) { int n1 = mid - left + 1 ; int n2 = right - mid; int *L = new int [n1]; int *R = new int [n2]; for (int i = 0 ; i < n1; i++) { L[i] = arr[left + i]; } for (int i = 0 ; i < n2; i++) { R[i] = arr[mid + 1 + i]; } int i = 0 , j = 0 , k = left; while (i < n1 && j < n2) { if (L[i] <= R[j]) { arr[k++] = L[i++]; } else { arr[k++] = R[j++]; } } while (i < n1) { arr[k++] = L[i++]; } while (j < n2) { arr[k++] = R[j++]; } delete[] L; delete[] R; } __global__ void mergeSortKernel (int *arr, int left, int right) { if (left < right) { int mid = left + (right - left) / 2 ; if (threadIdx.x == 0 ) { mergeSortKernel<<<1 , 1 >>>(arr, left, mid); } if (threadIdx.x == 1 ) { mergeSortKernel<<<1 , 1 >>>(arr, mid + 1 , right); } merge(arr, left, mid, right); } } int main () { const int numElements = 1024 ; int h_input[numElements]; int *d_input; for (int i = 0 ; i < numElements; i++) { h_input[i] = rand() % 1000 ; } cudaMalloc((void **)&d_input, numElements * sizeof (int )); cudaMemcpy(d_input, h_input, numElements * sizeof (int ), cudaMemcpyHostToDevice); mergeSortKernel<<<1 , 2 >>>(d_input, 0 , numElements - 1 ); cudaMemcpy(h_input, d_input, numElements * sizeof (int ), cudaMemcpyDeviceToHost); for (int i = 0 ; i < numElements; i++) { printf ("%d " , h_input[i]); } printf ("\n" ); cudaFree(d_input); return 0 ; }
Quick Sort 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 #include <stdio.h> #include <cuda_runtime.h> __device__ int partition (int *arr, int low, int high) { int pivot = arr[high]; int i = low - 1 ; for (int j = low; j < high; j++) { if (arr[j] <= pivot) { i++; int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } } int temp = arr[i + 1 ]; arr[i + 1 ] = arr[high]; arr[high] = temp; return i + 1 ; } __global__ void quickSortKernel (int *arr, int low, int high) { if (low < high) { int pi = partition(arr, low, high); if (threadIdx.x == 0 ) { quickSortKernel<<<1 , 1 >>>(arr, low, pi - 1 ); } if (threadIdx.x == 1 ) { quickSortKernel<<<1 , 1 >>>(arr, pi + 1 , high); } } } int main () { const int numElements = 1024 ; int h_input[numElements]; int *d_input; for (int i = 0 ; i < numElements; i++) { h_input[i] = rand() % 1000 ; } cudaMalloc((void **)&d_input, numElements * sizeof (int )); cudaMemcpy(d_input, h_input, numElements * sizeof (int ), cudaMemcpyHostToDevice); quickSortKernel<<<1 , 2 >>>(d_input, 0 , numElements - 1 ); cudaMemcpy(h_input, d_input, numElements * sizeof (int ), cudaMemcpyDeviceToHost); for (int i = 0 ; i < numElements; i++) { printf ("%d " , h_input[i]); } printf ("\n" ); cudaFree(d_input); return 0 ; }
Odd-Even Merge 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 #include <cuda_runtime.h> #include <iostream> #include <cstdlib> #include <ctime> using namespace std ; __global__ void oddEvenMergeSortKernel (int *arr, int n, int step, int halfStep) { int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < n / 2 ) { int index = i * step; int first = index; int second = index + halfStep; if (second < n && arr[first] > arr[second]) { int temp = arr[first]; arr[first] = arr[second]; arr[second] = temp; } } } void cudaOddEvenMergeSort (int *arr, int n) { int *d_arr; size_t size = n * sizeof (int ); cudaMalloc((void **)&d_arr, size); cudaMemcpy(d_arr, arr, size, cudaMemcpyHostToDevice); for (int step = 2 ; step <= n; step <<= 1 ) { for (int halfStep = step >> 1 ; halfStep > 0 ; halfStep >>= 1 ) { int threadsPerBlock = 256 ; int numBlocks = (n / 2 + threadsPerBlock - 1 ) / threadsPerBlock; oddEvenMergeSortKernel<<<numBlocks, threadsPerBlock>>>(d_arr, n, step, halfStep); cudaDeviceSynchronize(); } } cudaMemcpy(arr, d_arr, size, cudaMemcpyDeviceToHost); cudaFree(d_arr); } void printArray (int *arr, int n) { for (int i = 0 ; i < n; i++) { cout << arr[i] << " " ; } cout << endl ; } int main () { const int n = 8 ; int arr[n] = {9 , 7 , 3 , 8 , 5 , 6 , 4 , 2 }; cout << "排序前: " ; printArray(arr, n); cudaOddEvenMergeSort(arr, n); cout << "排序后: " ; printArray(arr, n); return 0 ; }
CUDA 并行编程 特性 Terminology :
==Host== :The CPU and its memory (host memory)==Device== : The GPU and its memory (device memory)
函数元关键字 :
__global__: 一组由 CPU 调用、GPU 执行的并行计算任务
__global__ 必须采用 void 返回值类型__global__ 函数是异步的,这意味着函数未执行完就返回了控制权。因此,测量内核函数的时间需要同步操作才能获得准确的结果
1 2 3 __global__ void add (int *a, int *b, int *c) { *c = *a + *b; }
函数超参数 :
1 add<<<gridDim, blockDim>>>(pa, pb, pc);
GPU 结构:Grid -> Block -> Thread
这个 add 函数执行在 Grid,gridDim 就是 Block 数目,blockDim 为 Thread 数目,最基本的并行单位是 Thread,下面的 idx 是全局的线程号, threadIdx 为块内的线程序号,blockIdx 为Grid内的块序号
1 2 3 4 __global__ void add (int *a, int *b, int *c) { unsigned int idx = threadIdx + blockIdx * blockDim; *c[idx] = *a[idx] + *b[idx]; }
编程示例 add<<<(N + M-1) / M,M>>>(d_a, d_b, d_c, N) 保证能够除尽
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 #include <cuda_runtime.h> #include <stdio.h> __global__ void vectorAdd (const float * A, const float * B, float * C, int N) { int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < N) { C[i] = A[i] + B[i]; } } int main () { int N = 1000 ; size_t size = N * sizeof (float ); float *h_A, *h_B, *h_C; h_A = (float *)malloc (size); h_B = (float *)malloc (size); h_C = (float *)malloc (size); for (int i = 0 ; i < N; i++) { h_A[i] = i * 0.1f ; h_B[i] = i * 0.2f ; } float *d_A, *d_B, *d_C; cudaMalloc((void **)&d_A, size); cudaMalloc((void **)&d_B, size); cudaMalloc((void **)&d_C, size); cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice); cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice); int threadsPerBlock = 256 ; int blocksPerGrid = (N + threadsPerBlock - 1 ) / threadsPerBlock; vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N); cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost); bool success = true ; for (int i = 0 ; i < N; i++) { if (fabs (h_C[i] - (h_A[i] + h_B[i])) > 1e-5 ) { success = false ; break ; } } if (success) { printf ("Test PASSED!\n" ); } else { printf ("Test FAILED!\n" ); } free (h_A); free (h_B); free (h_C); cudaFree(d_A); cudaFree(d_B); cudaFree(d_C); return 0 ; }
Memory API
cudaError_t cudaMalloc(void **ptr, size_t size): 在 GPU 上动态分配内存
ptr: devicePtr 指向显存,通过ptr 修改 devicePtr
malloc 直接返回一个内存指针,而 cudaMalloc 不返回指针,需要传入一个指向 devicePtr 的二级指针 ptr,分配空间后通过 ptr 修改 devicePtr
size: 分配空间大小,类似 malloc
cudaError_t cudaMemcpy(void *dst, const void *src, size_t size, enum cudaMemcpyKind kind):
dst: 指向拷贝的目的地指针;src: 拷贝源头指针;size: 空间大小;kind: 枚举,拷贝的类型,cudaMemcpyHostToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToHost cudaMemcpyDeviceToDevice 分别表示从主机到主机、从主机到设备、从设备到主机和从设备到设备的拷贝。
cudaError_tcudaFree(void *devicePtr): 释放内存
先分配,然后把数据拷贝到GPU,开始调用,调用完拷贝回 CPU
线程同步 块内同步 :__syncthreads():
__syncthreads() 是 CUDA 编程中的一个同步原语,它用于确保在某个线程块中的所有线程都已完成它们之前的所有指令,然后才能继续执行__syncthreads()之后的指令。这个函数只能在设备代码中使用,例如CUDA内核
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 __global__ void example (int *data) { int i = threadIdx.x; data[i] += 10 ; __syncthreads(); if (i > 0 ) { data[i] += data[i - 1 ]; } }
__syncthreads()的关键点
作用域 :它只对一个线程块内的线程起作用,不会同步整个网格的所有线程。使用场景 : 当线程写入共享内存,并且这些数据将被线程块中的其他线程读取时,通常需要一个__syncthreads()调用来确保写入完成。 当线程块内的线程可能同时写入同一个位置(导致不确定的结果)或在其他线程完成某些操作之前需要读取数据时,使用__syncthreads()可以避免竞态条件。注意事项 : 不要在分支条件下不均匀地调用__syncthreads(),这可能会导致死锁。 不要在循环中过度使用__syncthreads(),因为它会阻止线程并行地执行。 CUDA本身不提供跨线程块的同步机制。为了在全网格范围内实现同步,程序员通常需要结束当前的kernel执行并启动一个新的kernel,因为kernel启动之间存在隐式的全局同步。
设备同步 :cudaDeviceSynchronize()
CUDA 中的线程块(Block)之间不能直接通信 ,即使使用 __syncthreads() 也只对同一个线程块内部 有效。因此:
不同线程块之间的数据依赖需要通过全局内存 传递,并通过内核(kernel)调用之间进行同步:
1 2 cudaMemcpy(); cudaDeviceSynchronize();
如果线程之间完全没有数据依赖,比如前面提到的向量加法 示例,每个线程独立计算一个元素,互不干扰,那么不需要任何同步操作:
1 2 3 4 5 6 __global__ void vectorAdd (const float * A, const float * B, float * C, int N) { int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < N) { C[i] = A[i] + B[i]; } }