序列化
序列化
序列化乍眼一看似乎是多此一举,比如你在内存中创建了一个Person对象,你把内存中那块表示Person二进制数据原封不动地抠出来放到磁盘中,下次再原封不动地读入内存重构出Person对象不就行了吗,何必要进行序列化呢?
但事实并非那么简单,因为内存中的数据可能是非连续的。你所创建的Person对象可能有一个Name成员变量,它可能仅仅是一个指向另一片内存某块连续字符数组的指针。现实往往会更复杂,一个成员变量指针往往又指向其他的指针,使得一个简单的对象可能分布在你内存多个零散区域。而序列化,就是把这个对象的数据一层层连根拔起,将其打平成一块连续的数据。
我们知道一个对象往往包含很多信息,其成员可能有flaot, string, integer, 也可能是指向另一个对象的指针。比如JSON通过把以上的数据全部压平成字符串来进行传输,通过嵌套的字符串来替换原对象中的内存指针,来将不连续的数据重建为连续的数据。如果你说,我的对象不包含任何的引用变量或者指针,在内存中就是连续存储的。比如
Class Simple { int a=1; int b= 2} 或者 struct Simple {double a = 1.0;double b = 2.0;}
我还需要进行序列化吗?当然不必要,你可以把它这一块内存直接原封不动地丢进磁盘或网络,然后原封不动地取出来。这种情况极大降低时间消耗(几乎不花时间)也降低空间消耗(字符串存储效率往往低于二进制)。但是序列化依然有很多好处:
- 如果序列化成字符串,可以手动对传输的数据进行修改或者校验
- 如果序列化成字符串,机器用自己的方式解析字符串,避免**大小端**不一致带来的冲突
- 即使是不序列化成字符串,其他一些独特的二进制序列化方式极大地缩小空间,比如一个长度为8的boolean的数组(原本需要8个byte),可以压缩成一个byte再传输(每一个bit为一个boolean).
序列化组件
单方面的只把对象转成字节数组还不行,因为没有规则的字节数组我们是没办法把对象的本来面目还原回来的,所以我们必须在把对象转成字节数组的时候就制定一种规则(序列化),那么我们从IO流里面读出数据的时候再以这种规则把对象还原回来(反序列化)。
OSI七层协议模型中表示层(Presentation Layer)的主要功能是把应用层的对象转换成一段连续的二进制串,或者反过来,把二进制串转换成应用层的对象–这两个功能就是序列化和反序列化。
- IDL(Interface description language)文件:参与通讯的各方需要对通讯的内容需要做相关的约定(Specifications)。为了建立一个与语言和平台无关的约定,这个约定需要采用与具体开发语言、平台无关的语言来进行描述。这种语言被称为接口描述语言(IDL),采用IDL撰写的协议约定称之为IDL文件。
- IDL Compiler:IDL文件中约定的内容为了在各语言和平台可见,需要有一个编译器,将IDL文件转换成各语言对应的动态库。
- Stub/Skeleton Lib:负责序列化和反序列化的工作代码。Stub是一段部署在分布式系统客户端的代码,一方面接收应用层的参数,并对其序列化后通过底层协议栈发送到服务端,另一方面接收服务端序列化后的结果数据,反序列化后交给客户端应用层;Skeleton部署在服务端,其功能与Stub相反,从传输层接收序列化参数,反序列化后交给服务端应用层,并将应用层的执行结果序列化后最终传送给客户端Stub。
动态库:
1 | //main.c |
1 | gcc -o hello main.c func.c # 静态链接 |
编译器在预处理阶段将include的头文件插入到源文件,然后编译成目标代码,后缀名.o 就是object, 也就相当于windows下编译的obj文件,该文件能被cpu直接执行的二进制代码。由编译器生成,具体的生成方法取决于不同的开发环境。
链接:当我们的程序模块调用a另一个模块中b的函数(foo())或变量时,在编译的阶段编译器并不知道函数foo的地址,所以暂时把调用foo的指令的目标地址搁置,等待最后链接的时候由连接器去将这些指令的目标地址修正。把目标文件和库一起链接成可执行文件。将.o文件与其他库文件进行静态链接就生成可执行文件,也就是把多个.o文件连接成一个可执行ELF文件了
由于业务越来越复杂,导致程序的体积也越来越大,在多进程的操作系统中,可能同时存在成百上千各应用同时运行。每个应用中都会使用到printf、scanf、strlen等基础函数,链接的时候就需要把printf.o这个编译器内置的目标代码链接到hello.o中
那么不同的程序中一定会包含它们的指令部分。这就导致这些程序在磁盘保存时,都有这些基础函数的副本。运行时,也会将这些副本加载到对应进程的虚拟空间内存中去。这就导致了浪费磁盘和内存。

| 序列化组件 | 数据库组件 | 说明 |
|---|---|---|
| IDL | DDL | 用于建表或者模型的语言 |
| DL file | DB Schema | 表创建文件或模型文件 |
| Stub/Skeleton lib | O/R mapping | 将class和Table或者数据模型进行映射 |
IDL用于描述对象的结构,IDL编译器用于将IDL描述语言转化成
- Client/Server:指的是应用层程序代码,他们面对的是IDL所生存的特定语言的class或struct。
- 底层协议栈和互联网:序列化之后的数据通过底层的传输层、网络层、链路层以及物理层协议转换成数字信号在互联网中传递。
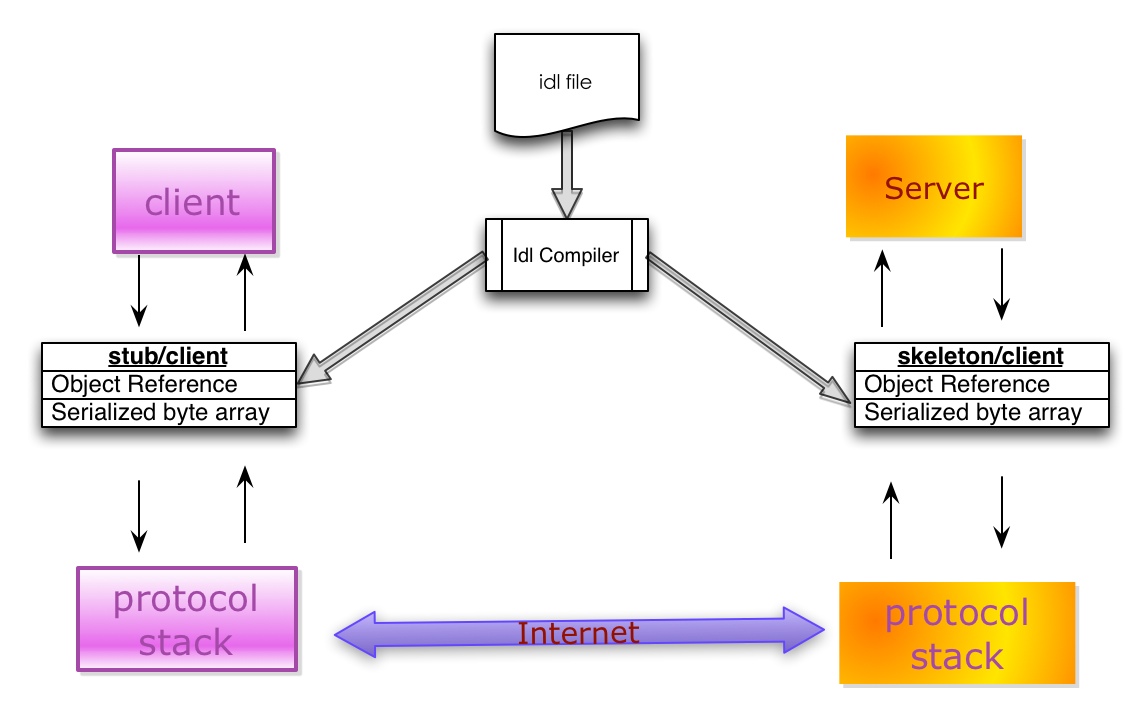
序列化只是一种拆装组装对象的规则,那么这种规则肯定也可能有多种多样,比如现在常见的序列化方式有:
JDK(非跨语言)、JSON、XML、Hessian、Kryo(不支持跨语言)、Thrift、Protobuf、FST(非跨语言)
1 | class Address{ |
Java Serializable
当创建了⼀个对象后,只要你需要它,它就可以⼀直存在;但是如果程序 退出,这个对象就不存在了。
虽然这乍看起来说得通,但在某些情况下, 如果程序不再运⾏,⽽对象仍然能够存在并且保留相关信息,会对我们⾮ 常有⽤。也就是说,在下次启动程序时,包含上次程序运⾏时信息的对象 还会在那⾥。我们可以通过将信息写⼊⽂件或数据库来实现此效果,但本着⼀切皆对象的宗旨,如果能将对象声明为持久性的,然后让编程语⾔⾃ 动为你处理所有的细节,会⽅便很多。
Java的对象序列化(object serialization)机制会接受实现了 Serializable 接⼝的任意对象,并将其转换成⼀个字节序列,便于以后 重新⽣成原始对象。它甚⾄可以通过⽹络⼯作,这意味着序列化机制会⾃ 动消除操作系统之间的差异。也就是说,你可以在Windows机器上创建⼀个对象、将其序列化,然后通过⽹络发送到UNIX机器上,它会在那⾥被正 确重建。你不需要担⼼不同机器上的数据表⽰、字节顺序或任何其他细节。
对象序列化可以实现轻量级持久化(lightweight persistence)。持久化意味着对象存活于程序调⽤之间,其⽣命周期不是由程序是否在执⾏决 定的。通过获取⼀个可序列化的对象并将其写⼊磁盘,然后在重新调⽤程 序时恢复该对象,这样就产⽣了持久化的效果。之所以称其为“轻量级”, 是因为你不能使⽤某个“持久化”关键字定义⼀个对象,并让编程语⾔替你 处理⼀切细节。相反,你必须在程序中显式地序列化和反序列化对象。如 果需要更严格的持久化机制,请考虑使⽤像Hibernate这样的⼯具。 在语⾔中添加对象序列化,主要是为了⽀持两个功能。
- ⾸先,Java的远程⽅法调⽤(remote method invocation, RMI)可以让存在于远程机器 上的对象表现得像存在本地机器上⼀样。当把消息发送给远程对象时,需 要对象序列化来传输参数和返回值。
- 其次,JavaBeans也需要对象序列化(在撰写本书时,JavaBeans被认为 是⼀项失败的技术)。当使⽤Bean时,⼀般会在设计时配置其状态信息。 这个状态信息必须存储起来,然后在程序启动时恢复,对象序列化就被⽤ 来执⾏此任务。
对象序列化⾥⼀个特别出彩的地⽅是,它不仅保存了对象的镜像,⽽且会 跟踪该对象包含的所有引⽤并保存这些引⽤对象的镜像,然后跟踪每个对象所包含的全部引⽤,以此类推。这有时称为单个对象可以连接到的“对象 ⽹络”,包括成员对象以及存储了对象引⽤的数组。如果你必须维护⾃⼰的 对象序列化⽅案,那么遍历所有这些链接的维护代码可能会极为复杂。不过,Java的对象序列化似乎完美地实现了这个⽬标。毫⽆疑问,它使⽤了 ⼀种遍历对象⽹络的优化算法。
Serializable:
- 实现
Serializable接口的目的是为类可持久化,比如在网络传输或本地存储,为系统的分布和异构部署提供先决条件。若没有序列化,现在我们所熟悉的远程调用,对象数据库都不可能存在。 - 序列化⼀个对象很简单,只要对象实现了
Serializable接⼝就可以。Serializable是⼀个标签接⼝,没有⽅法。当序列化被添加到语⾔中 时,标准库⾥的许多类被更改以便可序列化,包括所有基本类型的包装 类、所有容器类,等等。甚⾄Class对象也是可以序列化的。 - 序列化对象的持久化需要一个
ObjectOutputStream的字节流writeObject(),反序列化需要ObjectInputStream的readObject(),返回的是一个Object,因此需要强转类型。 - 反序列化后得到的对象确实包含了原始对象中的所有链接。 注意,在反序列化
Serializable对象的过程中,我们没有调⽤任何构造 器,连⽆参构造器也没有调⽤。整个对象的数据都是从InputStream⾥恢复的。
Externalizable:
所有正常的默认构造⾏为都会发⽣(包括在字段定义处的初始化),之后
readExternal()被调⽤。请注意这⼀点,特别是所有默认的构造总是会发⽣,这样才能在Externalizable对象中产⽣正确的⾏为一言以蔽之,不会存储具体的值,只会存储对象的骨架。在⽆参数构造器中没有初始化。这意味着,如果你没有在
readExternal()中初始化s和i,那么s就 是null且i是零(对象的存储在其创建的第⼀步被擦除为零)。因此,为了使序列化正常,不仅需要在
writeExternal()⽅法⾥写⼊对象的重要数据(序列化机制不会默认为Externalizable对象写⼊任何成 员对象),⽽且需要在readExternal()⽅法中恢复该数据。起初这可能有点令⼈困惑,因为Externalizable对象的默认构造⾏为有可能使它看起来像存在某种⾃动存储和恢复⾏为,⽽这实际上是没有的。
static:
凡是被static修饰的字段是不会被序列化的因为序列化保存的是对象的状态而非类的状态,所以会忽略static静态域。
transient:
- 防⽌对象的敏感部分被序列化的⼀种⽅法是将你的类实现为
Externalizable,如前所⽰。这样就不会⾃动序列化任何内容了,你可以仅显式地序列化writeExternal()中的必要部分。 但是,如果你正在使⽤Serializable对象,则所有序列化都会⾃动发⽣。 - 为了控制这⼀点,可以使⽤
transient关键字逐个字段地关闭序列化,它表⽰“不要费⼼保存或恢复这个字段——我会处理它的”。date和username是普通字段(不是transient的),因此会⾃动序列化。然⽽password是transient的,所以不会被存储到磁盘,序列化机制也不会尝试恢复它。
1 | public class Logon implements Serializable { |
- 当对象被恢复时,password字段为null。注意, toString()使⽤重载的+运算符组装了⼀个字符串对象,⽽其中的null 引⽤被⾃动转换成了字符串”null”。 你还可以看到date字段被存储到磁盘并从磁盘恢复,⽽不是重新⽣成。 Externalizable对象默认不存储⾃⾝的任何字段,因此
transient关键字仅适⽤于Serializable对象。
serialVersionUID:
在进行反序列化时,JVM会把传来的字节流中的
serialVersionUID于本地相应实体类的serialVersionUID进行比较。如果相同说明可以反序列化,否则会出现反序列化版本不一致的异常InvalidCastException具体过程是这样的:序列化操作时会把系统当前类的
serialVersionUID写入到序列化文件中,当反序列化时系统会自动检测文件中的serialVersionUID,判断它是否与当前类中的serialVersionUID一致。
java类中serialVersionUID的作用_seriaversionid 1l-CSDN博客
当实现
java.io.Serializable接口中没有显示的定义serialVersionUID变量的时候,Java序列化机制会根据Class自动生成一个serialVersionUID作序列化版本比较用,这种情况下,如果class文件(类名,方法等)没有发生变化(增加空格,换行,增加注释等等),就算再编译多次,serialVersionUID也不会变化的。如果我们不希望通过编译来强制划分软件版本,即实现序列化接口的实体能够兼容先前版本,就需要显示的定义一个
serialVersionUID,类型为long的变量。不修改这个变量值的序列化实体,都可以相互进行序列化和反序列化。还强烈建议使用
private修饰符显示声明serialVersionUID(如果可能),原因是这种声明仅应用于直接声明类 –serialVersionUID字段作为继承成员没有用处。数组类不能声明一个明确的serialVersionUID,因此它们总是具有默认的计算值,但是数组类没有匹配serialVersionUID值的要求。
序列化与继承:
序列化是以正向递归的形式进行的,如果父类实现了序列化那么其子类都将被序列化;子类实现了序列化而父类没实现序列化,那么只有子类的属性会进行序列化,而父类的属性是不会进行序列化的。
XML
对象序列化的⼀个重要限制是,它仅适⽤于Java平台:只有Java程序可以 反序列化此类对象。⼀个更具互操作性的解决⽅案是将数据转换为XML格式,这使得它可以被各种平台和语⾔使⽤。 由于XML的流⾏,使⽤它编程有很多令⼈困惑的选项,包括与JDK⼀起分 发的javax.xml.*库。我选择使⽤Elliotte Rusty Harold的开源XOM库 (可从XOM⽹站下载并查看其⽂档),因为在使⽤Java⽣成并修改XML的 各种⽅式中,它似乎是最简单、最直接的。此外,XOM还强调了XML的正 确性。 例如,假设有⼀个包含名字和姓⽒的APerson对象,你希望将其序列化为 XML。下⾯的APerson类有⼀个getXML()⽅法,它使⽤XOM将APerson 的数据抽取并转换为XML的Element对象,还有⼀个接受Element对象的 构造器,可以提取相应的APerson数据(注意XML⽰例在它⾃⼰的⼦⽬录 中)
1 | <xsd:complexType name='Address'> |
JSON
1 | { |
Kryo
Kryo是一个高性能的序列化/反序列化工具,由于其变长存储特性并使用了字节码生成机制,拥有较高的运行速度和较小的字节码体积。
另外,Kryo 已经是一种非常成熟的序列化实现了,已经在Twitter、Groupon、Yahoo以及多个著名开源项目(如Hive、Storm)中广泛的使用。
guide-rpc-framework 就是使用的 kyro 进行序列化,序列化和反序列化相关的代码如下:

Github 地址:https://github.com/EsotericSoftware/kryo 。
Protobuf
Protobuf出自于Google,性能还比较优秀,也支持多种语言,同时还是跨平台的。就是在使用中过于繁琐,因为你需要自己定义 IDL 文件和生成对应的序列化代码。这样虽然不然灵活,但是,另一方面导致protobuf没有序列化漏洞的风险。
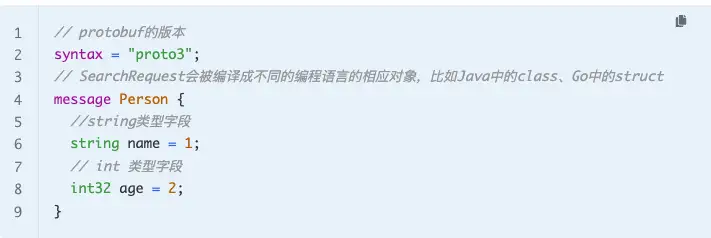
Protobuf包含序列化格式的定义、各种语言的库以及一个IDL编译器。正常情况下你需要定义proto文件,然后使用IDL编译器编译成你需要的语言
一个简单的 proto 文件如下:
1 | message Address |
Github地址:https://github.com/protocolbuffers/protobuf。
ProtoStuff
由于Protobuf的易用性,它的哥哥 Protostuff 诞生了。
protostuff 基于Google protobuf,但是提供了更多的功能和更简易的用法。虽然更加易用,但是不代表 ProtoStuff 性能更差。
Gihub地址:https://github.com/protostuff/protostuff。
Hessian
hessian 是一个轻量级的,自定义描述的二进制RPC协议。hessian是一个比较老的序列化实现了,并且同样也是跨语言的。

以上描述的五种序列化和反序列化协议都各自具有相应的特点,适用于不同的场景:
1、对于公司间的系统调用,如果性能要求在100ms以上的服务,基于XML的SOAP协议是一个值得考虑的方案。
2、基于Web browser的Ajax,以及Mobile app与服务端之间的通讯,JSON协议是首选。对于性能要求不太高,或者以动态类型语言为主,或者传输数据载荷很小的的运用场景,JSON也是非常不错的选择。
3、对于调试环境比较恶劣的场景,采用JSON或XML能够极大的提高调试效率,降低系统开发成本。
4、当对性能和简洁性有极高要求的场景,Protobuf,Thrift,Avro之间具有一定的竞争关系。
5、对于T级别的数据的持久化应用场景,Protobuf和Avro是首要选择。如果持久化后的数据存储在Hadoop子项目里,Avro会是更好的选择。
6、由于Avro的设计理念偏向于动态类型语言,对于动态语言为主的应用场景,Avro是更好的选择。
7、对于持久层非Hadoop项目,以静态类型语言为主的应用场景,Protobuf会更符合静态类型语言工程师的开发习惯。
8、如果需要提供一个完整的RPC解决方案,Thrift是一个好的选择。
9、如果序列化之后需要支持不同的传输层协议,或者需要跨防火墙访问的高性能场景,Protobuf可以优先考虑。
总结
- Web开发(特别是前后端通信):JSON占主导地位。
- 高性能需求:Protobuf和Thrift是更优的选择。
- 大数据处理:Avro和MessagePack可能是合适的选择。
- 复杂文档结构:XML仍然是标准选择。
不同场景下的需求,决定了选择哪种序列化方法。